
![]()
![]()
1025 1004 0916 0727 0703 0607 0601 0529 0509 0502 0426 0424 0327 0319

前回、前々回からの続きです。「エスキモーの雪に関する語彙デマ」の話を発端として二種類の言語観(相対主義、普遍主義)についてアレコレ語っています。
この両者の関係では、生成文法を信奉する普遍主義者が「言語学は自然科学であらねばならない」「自然科学の対象は普遍的なはずだ」という信念のもと(母語が違うと世界の分節法も変わるんやで、という)言語相対論系統の言語学を「非科学的でナンセンスだ」と排斥してほぼ絶滅(←!)に追い込みました。
(私の理解では)二十世紀の言語学は「いかにして言語そのものを研究対象にするか」という問題意識から始まっています。その際に「論理」「歴史」「書きことば」に関わる要素などをできるだけ排除することが「言語そのもの」を扱う上で重要になっていたはずでした。方法や手続きに拙い点はあっても、言語相対論系統の言語学はこの原則に従っています。その意味で彼等は正統派でした。
>> 
けれども、これを批判した生成文法派(=普遍主義者)は堂々と「論理」と「言語」を混同して開き直っています。言語を生み出す「こころ」の「普遍文法」は「論理」である、みたいな感じでしょうか。
言語と論理の関係について研究する、ということ自体は勝手にやればよいと思います。また論理が普遍的なものですべての人間の脳に生得的に備わっている何かであるとかなんとか、そういうことも御自由にどうぞ。そんな学問領域があっても一向に構いません。ですが、他の言語研究手法や研究者をことあるごとに執拗に攻撃しつつ、自分たちだけが「言語学」に値するのだと主張して「言語学」の乗っ取りを図り、それに(特に北米や日本などでかなりの程度)成功してしまったことは大問題です。
こうした彼等の所業(=悪業三昧、マジで:怒)についてもあとで具体的にちょっと御浚いしておこうとは思いつつ、直接的には関係なさそうな(←!)話題から...
千葉のスイカに続き、今度は岩手県宮古市の知人から、毎年恒例のホヤ貝が送られてきた。知人の斉藤おじさんとは十年来のおつき合いである。十年前、初めて宮古を訪れて、斉藤おじさんのご接待の席にて初めておいしいホヤ貝に出会った。(p.159)
引用は『残るは食欲』(阿川佐和子)に収録されている「孤独なホヤ」というエッセイ冒頭からなのですが、「ホヤ貝」という語にモジモジしてしまいます。自然科学的観点からいって「ホヤ貝」などという貝は存在しないので端的に申し上げればこの語は現代日本語においては普通「間違い」とされます。
「ホヤ貝」でググってみるとこれが「間違い」であると指摘している事例を多数見かけます。たとえば以下のように。
>> クリトモのさかな道
ホヤは貝ではありません。尾索(びさく)動物といいます。プランクトンを濾過して食べる動物で、ホヤ類は2300以上あると言われています(怖っ)。
わざわざ「貝ではありません」とことわっているのは「貝だと思っている人」が多数いるためでしょう。つまり『残るは食欲』の著者もありふれた誤解者のひとりということです。
生物学(?)的には「貝類」というのは「軟体動物」あるいは「軟体動物で殻を持つもの」のことらしいです。タコやイカなんかも軟体動物だし祖先(?)は殻を持っていたようなので定義上は「貝類」になるそうです。タコが貝類...(汗)(アンモナイトとかオウム貝とかを考えれば、まあ、たしかにそうかも...)。
で、ホヤは軟体動物ではなく「尾索動物」に分類され、これはヒトなどを含む「脊椎動物」が属する「脊索動物」門の下位区分にあたります。つまりホヤは貝類などよりはずっと我々人類に近い生物といえそうな気もしないでもない。納得いくかどうかは別にしてですが。
まあ、なにはともあれ、このエッセイで著者が読者に伝えるべく意図した内容は「ホヤは嫌いだったが新鮮なものはおいしいとわかった。だからホヤがまずいという世間の誤解を解くべく新鮮なホヤを知人らに勧めている。しかし外見が醜いため、にべもなく拒否されて誰にも食べてもらえない。残念である」程度にまとめられます。
また、ホヤの「魅力を理解できるのは、醜さの奥に隠れた真の価値を見抜く力のある限られた民のみ、たとえば私(p.163)」と末尾あたりに書かれていることから、世の中には偏見から見向きもされないにもかかわらず優れた真価をもつ人や物なんかが存在するんだよ、という(イソップ童話的教訓風?)含意もありそうです。タイトルが「孤独なホヤ」ですし。誰にも理解されず孤独な...ということでしょうか。
ところで、一般的にいって著者が表現しようと意図したものだけがテクストの意味や内容とはいえません。意図せず表出されてるもの、読み手が(それなりの根拠はありつつ)勝手に受け取ってしまう何かというものもあります。
このエッセイの場合、著者の意図した伝達内容が「ホヤの隠された魅力を伝えること」であったとしても、「ホヤ貝」などという「ホヤが貝じゃないということさえ理解していない」ことを窺わせる語を使っているわけですから、素直には受け取れません。信用できない書き手なんじゃないかという疑念は湧きます。
「孤独なホヤ」の著者がどういう「こころ」でこのテクストを書いたのか、「ホヤ」を意味しているであろう語の使い分けについて具体的に計数などしつつ推理してみます。「ことば」から「こころ」を分析してみる試みです。
まず以下の三種類の語が使われていました。
| ホヤ貝 | 14 |
| ホヤ | 12 |
| 貝 | 4 |
タイトルでの使用を入れると更に「ホヤ」に1票入りますので、総計だけみると「ホヤ貝」と「ホヤ」の使用数は拮抗しています。ページごとの内訳は以下のとおりです。
| 159 | ホヤ貝 | 7 | ホヤ | 0 | 貝 | 0 |
| 160 | ホヤ貝 | 2 | ホヤ | 1 | 貝 | 1 |
| 161 | ホヤ貝 | 1 | ホヤ | 3 | 貝 | 2 |
| 162 | ホヤ貝 | 3 | ホヤ | 6 | 貝 | 1 |
| 163 | ホヤ貝 | 1 | ホヤ | 2 | 貝 | 0 |
全部で5ページ。最後の163ページは半分くらいまでしか文字で埋まっていませんでした。
分布の特徴としては、最初のページで全「ホヤ貝」使用の半分が出現、最後からひとつ前のページに「ホヤ」の半数が固まっている、というのが目につきます。大雑把にいうと前半で「ホヤ貝」、後半では「ホヤ」が優勢という傾向です。
もう少し細かく使い分けの条件を探ってみましょう。
| 発言の引用 | ホヤ貝 | 4 | ホヤ | 0 | 貝 | 1 |
| 複合語 | ホヤ貝 | 1 | ホヤ | 5 |
実際の会話をカギカッコつきで引用した部分では「ホヤ」は全く使われていません。このうち著者以外の発話は2例で「あらホヤ貝!?(p.160)」「ああ、ホヤ貝は苦手なんだよ(p.162)」です。後者は「ホヤ苦手組」の発話なのでホヤを貝だと思っていても問題はないのですが、前者は「ホヤ好きイノマタ夫人」の発話なので疑問が生じます。青森出身でホヤ解体法なども熟知しているイノマタ夫人がホヤを貝だと誤認しているとは考えられませんので実際は「あらホヤ!?」と言ったのを改変したのでしょう。こういう点での正確さに全く配慮していないことが窺い知れます。
複合語に関しては1例を除いて「ホヤ」を使用しています。後半で「ホヤ」の使用が増えるのは話題が展開していく中で複合語の出現頻度が上がったためというのも主たる要因のひとつでしょう。
唯一用法が異なった「ホヤ貝クール宅急便(p.163)」では「貝」という字を間に入れないと「ホヤクール宅急便」となって「ホヤ」と「クール宅急便」の境目が表記上わかりにくいことからそのようにしたのではないかと推察できます。逆にいえば他の事例「ホヤ解体術(p.161)」「ホヤ好きイノマタ夫人(p.162)」「ホヤ好き人種(p.162)」「ホヤ苦手組(p.162)」では「貝」が入ると漢字部分との境目が表記上わかりにくくなると判断して「ホヤ」を用いたとも考えられます。
残りの用例「新鮮ホヤ(p.161)」については直接的な理由はよくわかりません。なんとなくの傾向として同じ語が連続しすぎたり重複したりすることを避けようという配慮がみられますので、それに因った可能性はあります。
エッセイの二ページめ(p.160)に初めて「ホヤ」表記が出現したときも「北の貝であるホヤだから」で、これは「北の貝であるホヤ貝だから」というように「貝」が重複してしまうのを避けたのではないでしょうか。
いずれにせよ著者は「ホヤ」と「ホヤ貝」を(たとえばホヤ理解の程度を表現する指標としてなど明確な基準では)使い分けてはいません。「ホヤ」を「ホヤ貝」の略称くらいに思っているのでしょう(だからこそ十年以上ホヤを送ってもらって解体までしていてもそれが貝ではないという事実に気づかなかったのかも...斎藤さんやイノマタ夫人は一貫して「ホヤ」と言ったり書いたりしていたはずなんですけど:汗)。
「孤独なホヤ」の著者における「ホヤ」と「ホヤ貝」の使い分けには、この人物の「個人言語 idiolect」が反映されていると考えて良いでしょう。普通の現代日本語とは少し違っています。
A term used in LINGUISTICS to refer to the linguistic SYSTEM of an individual speaker - one's personal DIALECT. A dialect can be seen as an abstraction deriving from the analysis of a large number of idiolects.
上記 idiolect の説明は『A Dictionary of Linguistics and Phonetics』(Crystal, D.)から。ここまでの話は日本語における阿川佐和子方言(笑?)についてアレコレ述べてきたことになるわけです。同書による「方言 dialect」の解説は以下の通りです。
A regionally or socially distinctive VARIETY of language, identified by a particular set of WORDS and GRAMMATICAL STRUCTURES.
長いので冒頭だけ引用しました。「ホヤ貝」は「ホヤ貝誤用系話者(の社会的)方言」を特徴付ける「a particular set of WORDS」に含まれる語だと考えられます。阿川佐和子方言の分析から、それが属するもっと大きな規模の方言(=具体的には、このエッセイが連載されていた雑誌『クロワッサン』読者層方言...かな?)の特徴を抽出できるかもしれません。そんなことしてどうすんだ、という気がかなり強くしますけど(滝汗)。
ですので(←?)もう少し分析というか考察というか推理を続けてみます。
唐突ですが「ホヤ」と「ホヤ貝」のセットに似たもので「ホタテ」と「ホタテ貝」があることに思い至りました。基本的には同じ意味の語の組み合わせという点が共通です。ただ後者の場合はどちらも自然科学的(?)に妥当ですけれど。
ところでナントカ貝であれば何でもオーケーかというとそういうこともありません。「ムール貝」を「ムール」と呼べばなんのことかわかりませんし、先述の「オウム貝」を「オウム」と呼んだら鳥の名前になってしまいます。「ホラ貝」だと「ホラ」つまり「虚言」と誤解されやすくなります(母語話者として内省してみるとアサリやシジミはぎりぎり「貝」付きで呼ぶこともありそうですが、サザエなんかに「貝」をつけて呼ぶのは普通じゃないように思います。どういう仕組みなんでしょうね...)。(補足:世界はひろい!!サザエ貝の用例はっけん!! >> 「サザエ貝は私の大好物です」)
さて、エッセイ「孤独なホヤ」の pp.161-162 で使われた「ホヤ」と「ホヤ貝」を「ホタテ」と「ホタテ貝」に置き換えてそれを含む文を抜き出してみます。その結果は以下の通り。会話を挟む前後は省略しました。
「私はすぐにホタテを抱えてイノマタ家の台所へ馳せ参じた」「水を出し切ったホタテ貝は、空気の抜けた風船のようにしょぼくれた」「こうしてめでたくホタテ解体術をイノマタ夫人にご指南いただき、お礼に新鮮ホタテを二個ほど差し上げて、帰宅し、自ら実践する」「毎年、この季節になると、斉藤おじさんのホタテが届くのは、秘かな楽しみになっている」「鮮度の高いうちに調理して、ホタテのおいしさを多くの人に知ってもらいたいと、いままでずいぶん(以下略)」「もはや引っ越しを繰り返し、ホタテ好きイノマタ夫人とも家が離れてしまった」「いくら酢に漬けてあると言っても、鮮度が勝負のホタテ貝を何日もたってから人様に差し上げるのは失礼であろう」「都合のいいタイミングにホタテ好き人種を探り当てるのは、なかなか難しい」「誰よりも身近で分けやすい人間が、我がアシスタントのアヤ嬢なのだが、彼女もまた、ホタテ苦手組の一人である」
ホタテを酢に漬けたりはしないと思うので少し妙ですが、意味は概ね通じます。イノマタ家に向かうときは「ホタテ」で、解体作業の具体的描写では「ホタテ貝」です(「この貝のなかから出てくる水が」「貝の管からしたたり落ちる海水」のように「貝」だけも使われていました)。解体の具体的描写パートが済んで以降は「ホタテ」の使用率が高まります。斉藤おじさんが送ってくるものも「ホタテ」に(置き換えてるのでややこしいですが原文冒頭で「ホヤ貝」だったのがここでは「ホヤ」に)変わりました。
この違いはなんでしょうか。もしかすると「食材としての性質が強く認識されているかどうか」にかかわっているのかもしれません。
「ホタテ貝のバター焼き」と「ホタテのバター焼き」では想起するイメージに若干の差があるのではないでしょうか。前者の場合、貝殻がついているといいますかフタ付きで調理されている様子が思い浮かびます。つまり前回ちょっとふれた「a chicken」と「chicken」同様の区分が成り立っているような気がしないでもありません。「ホタテ貝」だと(「ホタテ」に比べて)冠詞のついた chicken のように「まるごと」感があるといいますか。
「ホヤ」と「ホヤ貝」の場合、そもそも「ホヤ貝」が誤用だという意識がどうしてもついてまわるので、上であげたホタテ版のようには考え難かったのですが、この基準による可能性もあるような気がしてきました。
そう考えて読み直してみると解体描写の途中「赤貝のような鮮やかなピンクオレンジ色をした身の部分(p.161)」があらわになった記述に続いて以下のように書かれているのが目に付きました。
「うわー、ここを食べるわけですね」
不気味さが払拭され、ワクワクする。(p.161)
つまり食材と認識されたという感想を述べて以降、急に「ホヤ貝」ではなく「ホヤ」の使用率が上昇したようなのです。
ここまでの考察をまとめてみます。
『残るは食欲』に収録された「孤独なホヤ」というテクストでは、生物学的には存在しないため指示対象がない「ホヤ貝」という語が使用されている。そして「ホヤ」という(現代日本語において正しいとされる)語と併用されて何らかの基準で使い分けられている。
このテクスト内での用法では「ホヤ貝」も「ホヤ」も物理的存在としては同じ物を指し示している(ex. 斉藤さんが送ってくるものに対してどちらの用語も使用している等々)ことがわかる。会話の引用では「ホヤ貝」に統一され、最初のページではすべて「ホヤ貝」を用いていたことから「ホヤ貝」を正式な呼称と認識している可能性がある。
語の使い分けに作用している要因としては、まず読み手に配慮した表記上の工夫が考えられる。カタカナ表記の語が後続する場合には「ホヤ貝」を用いて境界を明らかにし、漢字表記の場合には「ホヤ」を用いる箇所がそれに該当する。また同語反復を嫌って両語を切り替える傾向も疑われる。
テクスト内で記述された内容を大筋で信用するなら、書き手は十年以上に渡って解体作業までしているにも関わらず「ホヤ」を「貝」であると誤認したままであるほど生物学(?)的知識には無関心である。また極度に思い込みが激しく人の話を全く聞かないか、他者が誤認を指摘しにくい人物である(エッセイの連載誌であるマガジンハウス社『クロワッサン』および新潮社の校正をくぐり抜けて「ホヤ貝」が使われ続けているところをみると、いくぶん目眩を覚えまするが...)と考えられる。
しかしながら(厳密に則っているわけではないものの)「食材」とみなす書き手の意識で言及したときに「ホヤ」を選択していると理解できる箇所も存在している。タイトルが「孤独なホヤ」であって「ホヤ貝」を用いなかった点にもこのルールが反映されているのではないか。「ホヤ貝」は不気味だが(その内部に秘められた)食材としての「ホヤ」はおいしいのに不人気である=孤独、という解釈が可能である。
・・・まとまってないですね、これでは(汗)。
たぶん「孤独なホヤ」の著者は自分が行なった「ホヤ貝」と「ホヤ」の使い分けに関してはほぼ無自覚でしょう。しかし全くデタラメでランダムかといえばそういうことはなく、複数のルールというか基準というかコードを混ぜて適用している感じです。重複などもしながら。
科学的にいって「ホヤ貝」なんぞというものは存在しないんだからすべてナンセーンス!!という読み方をしてもまあいいんじゃないかと思うんですが、それよりはこうした語の分布状況を手掛かりにして、つまり「ことば」をもとに「こころ」を推定する方が前向きというか生産的というか、文学的というかなんというか。
てか、この混濁した感じこそが言語の常態だと思うんですけどね、オイラは。だからこういう状態のものを分析できる手法じゃなければ結局なんにもわかんないんじゃないかな。
というわけで(?)次回なるはやで生成文法ネタを書くことにしよう。恨み骨髄すぎてアレなんだけど。(雑感:生成文法派には心底腐った<自粛>だけじゃなくて、生成文法に帰依しているというとてつもなく巨大で非人道的な欠点を除けばナイスガイな方も結構いるので、まあ、いろいろだぬん...)
そんな感じ。
・・・って shellfish について触れてなかったですね(滝汗)。マンドクセーんでアレなんですが、英語で貝類は shellfish だそうなんすよ。他にもなんか言い方あるのかもしんないんですけど。
1 [C] a type of animal that lives in water and has a shell 2 [U] these animals used as food
『Wordpower』にはこんな風に書いてあります。そして挿絵は oyster、mussel、crab、lobster、prawn です。どさくさに紛れて(?)エビやカニも含まれています。甲殻類の外骨格(?)も shell なんですね。
turtle をこの辞書でひくと「a reptile with a soft body and a thick shell that lives in the sea」とあるので shellfish に該当しそうなんですが...いくらなんでもそれはないと信じたい(笑?)。fish が「an animal that lives and breathes in water using its fins and tail for swimming」となっているので肺呼吸するやつはアウトということかもしれませんけろ。いずれにせよ日本語の「さかな」と fish はカバーしている範囲が相当ズレてるみたいですね。
という具合にいろいろでやんすなあ、ってことです。とっぴんぱらりのぷう。
前回の続きです。Twitter で下記のような一連の発言を見ましたので予定を変更して(Pullum やピンカーではなく)これについてアレコレ書いてみます。
しかしなんやろな、やっぱり言語相対性って特別だな。「ことば」と「こころ」をどうしても分離できない学生が少なくない
「green ligntを青信号って言うのを見れば、日本人が青と緑の知覚がアメリカ人と違うのがわかる」-->「知覚が違うってどうしてわかるの?」-->「だってgreen lightを青信号って言うでしょ」みたいなループがすぐ発生してしまう
それはことばが違うってだけで、色の見え方が違ってるかどうかはわかんないよね?と何度も何度も言うのだけれども。
「違う色に見えるけど、同じ色名で呼ぶでしょ。これとこれ、違う色だけどどっちも赤っていうでしょ」「じゃあ同じ名前で呼んでいる人達は色の区別ができないんですね」みたいな齟齬とか
どうやったら「ことばの違い=こころの違い、には必ずしもならないよ」が分かってもらえるのであろうか
なんやろなー、ピカソとかダリとか北斎とかの絵を見せて、「ほらーこの人達の描く絵って違いますよねーでもだからといって、この人達に世界が違って見えてるかはわからないですよねー」とやればいいのだろうか
「言語相対性」とあるのは linguistic relativity のことで、Whorf(1940)(←PDFです)で述べられているような説の根底にある考え方です。関連する用語としては「言語(的)相対論」等々があります。
これを極端に進めた「言語決定論」では「人間の思考(=世界の見え方)はすべて母語によって規定されている」と主張しているのだとか(←具体的に誰がいうてるんかはよくわかってません:汗)。ある言語の母語話者が唱える哲学なり思想といったものは、単にその母語の文法や語彙について解説をしているだけに過ぎないのだ...というのです(トンデモ理論に聞こえますが、「母語」を「言語」に変えたらヴィトゲンシュタインの linguistic turn と同系統話のような気も...)。
上で引用した発言ではこうした言語相対論系の考え方を全面的に否定しています。「ことば」の使用法に相違点があっても、それが話者の「知覚」=「こころ」の違いを反映しているかどうかはわからない、というのが論拠です。しかし「何度も何度も」学生さんに説いたにもかかわらず、言語相対論(?)的意見を翻意させることには失敗したらしい。
以下、この言語相対論批判者の主張を眺めつつ、いったい何が問題でそうなったのかについて述べてみようと思います。
最初に言及された具体例は「green lightを青信号って言う」ことから「青と緑の知覚」が「日本人」(というか日本語母語話者)と「アメリカ人」(=米英語母語話者)の間で違っていると主張することはできない、というものです。

上の写真のように「青」信号に緑色が使われているとき、日本人の意識としては信号が本当に青色に見えるから「青」といっているわけではないので「知覚」の如何とは関係ないだろ、ということかと。黒くなくても「黒板」だったり、「緑児」が緑色ではないみたいなことでしょうか。
色名が使われていても、それが実際に知覚されたものを直接反映しているのかどうかは確かにわかりません。知覚と関係のない様々な事情や経緯の結果ということはよくありますし、そもそも色名は光の波長がどうこう以外のものも含意(日本語「青」や英語「green」の「未熟」など)しているのが普通です。
きちんと色名が使われるに至った背景を調べ上げて「知覚」のみと関係ある事例かどうかを見極めておく必要があります。この過程を無視した短絡的で機械的な一般化は避けるべきであり、その点から「緑色の青信号」だけを根拠に「青と緑の知覚」が日米で違っていると主張することは確かに妥当とはいえません。
しかしこのことは(架空の、しかし残念ながら高確率で存在しそうな:汗)言語相対論者の考察や手続きに至らない点があるというだけで、言語相対論そのものが間違っていることまでは決定付けません。
ちなみに現在の青信号は日本では本当に青いみたいですけろ。
>> 広報けいしちょう
昭和5年に初めて信号機がついたとき、法令上は「緑色」でした。しかし、日本語の「青」の範囲は広く、青菜や青物など緑色のものを「青」と呼ぶ場合が多く、色の三原色「赤・黄・青」からも緑色の信号も青信号と呼ばれたのでしょう。こうして青色信号という呼び名が一般的になってきたことから、昭和22年に法令でも青信号と呼ぶようになり、昭和48年以降に作られた信号機は呼び名どおり青色になりました。
また、違う色に見えるものを同じ色名の「赤」と呼ぶからといって、その違いを「知覚」していないわけではないという事例もあげています。
| #ff0000 | #dc143c |
上の二つの色はどちらも「赤」と呼びますが、確かにその違いは(おそらくどの言語の母語話者にも)「知覚」されています。つまり、ある色を「同じ名前で呼んでいる人達は色の区別ができない」という事実はないのだから言語相対論は間違っている、というわけです。
「色」の「知覚」については古く1970年代にすでに下記のような実験をもとに言語相対論を否定する意見があったことが知られています。
>> Empirical Research of Rosch
Rosch presented the Dani eight focal and non-focal chips for five seconds each. Then, the subjects had to point to the color they had just seen in the color array. Focal chips were matched more precisely. Thus, focal colors are remembered more accurately in short-term memory than non-focal ones. However, the American control group matched the colors more precisely than the Dani.
Eleanor Rosch(エレノア・ロッシュ、旧姓 Heider)が色に関して mili と mola(light と dark?)という語しか持たないというパプアニューギニアの Dani 語話者に対して Munsell Color Chips という実験用具を使って英語母語話者との比較を行なったとあります。focal colors というのは(後に色だけではなく形状も含めて prototype と呼ばれるようになるのですが)「red, orange, yellow, green, blue, purple, pink, brown, gray, black and white」といった、基本的な色および色名語彙のことを指しているようです。原論文を確認していないので(←!)はっきりしないのですが、たぶんこのうち gray、black、white を除いた8色の focal colors とそれ以外の8色による計16種類のチップを使って「知覚」に差がでるのかどうか調べたのだと思います(主たる関心は focal colors の方が non-focal なものより認知しやすいかどうか、にあるようです...)。
結果としては Dani 族も(英語話者よりは「慣れ」の差によって?)「precisely」の点で劣りはするものの、ちゃんと(英語話者と同じく focal なものに対して好成績という傾向を持って)識別できた...つまり母語における色名語彙がどうあれ同じように色を「知覚」するのだから言語相対論は間違っているのだ、と考えたらしいのです。
どんな言語を話す人間にとっても、その言語で用意された「色」を表す「ことば」の種類なんかとは関係なく「世界の見え方」=「知覚」は一緒である、と主張している点で Twitter での批判者と同じ考え方だと言ってよいでしょう。こういう人達は「(言語)相対論者 relativist」に対して「普遍主義者 universalist」と呼ばれるようです。
前回うっかり(?)Pullum を「生成文法信奉者」などと(やや明確に悪意を込めて:汗)呼んでしまいましたが、生成文法と直接の関係は持たない認知科学云々といっている人々の中にも普遍主義者はかなり紛れ込んでいるわけですから、用語としてはこちらで統一しておいた方が良いかもしれません(余談:universalist や universalism というのが一般的には宗教用語である、というのもよく実態を表しているようには思います)。
さて、こうした Rosch らの形式的には合理的な批判が言語相対論者を翻意させないのはなぜなのでしょうか。それはたぶん「こころ」=「知覚」ではないからです。「ことば」の違いは「こころ」の違いを反映しているが、単純な(あるいは身体にある感覚器官の機能としての)「知覚」に関しては「知らんがな」ということかと。
この場合でいえば、感知した波長をどういう基準で分類するのか、その(文化的なコンテクストまでをも含んだ複雑な)処理方法に「こころ」の差が見られ、そうした範疇化の違いについては同一母語話者集団(たとえば日本語なら一億数千万人)に共通した同一の傾向がある、というのが言語相対論の主張だと考えられます。つまり言語相対論で「世界の見え方がどーの」というときの「見え方」は光の波長の違いを感知できるかどうか、という話ではそもそもないのだと思います(デジタルカメラやら液晶テレビやらのハードウェアそのものの回路には何も手が加えられていないのにファームウェアを更新するなどによって不具合が修正されたり性能が向上したりする場合のソフトウェア的な部分が「こころ」なのかなー、と安易な喩え話などしちゃったりしますが...わかりにくいですかね:汗)。
ところで下記の色名を聞かれたら何と答えるのが普通でしょうか。
| #a59aca |
日本人なら「紫」と答える人が多そうです。科学的(で普遍的?)な色彩理論からいえば青の彩度を下げた色とされるので「青」というのが正解(?)であって日本人は間違っている(?)のかもしれません(余談:蛇足ですが最初期に開発された青バラの品種「ブルームーン」はまさしくこんな色です。青バラにしては病弱な印象ではなく育てやすいのでオススメ。苗木も3000円くらいで買えたし)。
日本の伝統的な色体系と欧州文化での色体系に違いがあるため、大まかには一致していてもこういう部分に差が出たりはします。母語が色の範疇化に直接どう作用しているのかは結局のところよくわかりませんが、漠然と「文化」同士で比較した場合に(経験的には)何らかの差が見られるという意見は多いようです。
「色彩とパーソナリティ(著)松岡武」によると、白い世界、雪の中で生活するイヌイットは白を示す名称が多様らしい。つまり日本人には、同じ「白」にしか見えないものが、彼らには「五色」の白系の色として目に映っている可能性もある。
しかし上記に引用した意見などで顕著ですが、なんだか「エスキモーの雪に関する語彙デマ」の変種が流布されているようで、どの程度信用してよいのかはわかりません(典拠として言及されている『色彩とパーソナリティ』は読んでいないので具体的になんと書いてあったのか確認はできていませんが)。
異なる文化に属する人々によって細かなレベルで色の範疇化に違いがあるかどうかをテストすることは可能だと思われます。しかしこのテストによって違いが明らかになったとしても言語相対論が正しいかどうかは全くわかりません。文化と言語と認知の関係(=言語が認知も文化も支配しているという主従関係)をこうした側面から実証することはたぶん無理だからです。
普遍主義者が提示する懐疑(「ことばの違い=こころの違い、には必ずしもならないよ」)に対抗する方法を「ある語が何を指し示しているのか」を巡る議論の中で見つけ出そうとすることは、そもそも言語を「ものの名前のリスト」とする考え方に則っている点で適切ではありません(←ソシュールの主張を踏まえれば当然そうなるはずなのですが、普遍主義者=所謂「言語学者」とのメールのやりとりで「ソシュールの理論などは言語学として認められていない」といわれたことがありますので、まー、なんつーか:汗)。Whorf が言語相対論を説明する中で「エスキモーの雪に関する語彙」の例を出したのは、安易な一般化によってデマが撒き散らされる切っ掛けを与えたという点だけでなく、批判者に対して防御不能の突破口(=「実証不能じゃん?」「ループしてるし、トートロジーだし w w w」)を与えた格好になってしまっていることでも大変不用意かつ致命的なミスだったと言えます。
せめて以下のような文法の話だけに絞ればよかったのに...と思うのですが、これであっても「Shawnee 語なんてこっちはわかんないんだから w w w 本当にこういう言語なのかは確認できないよ?」という懐疑論者を説得するのは難しいでしょう。
>> 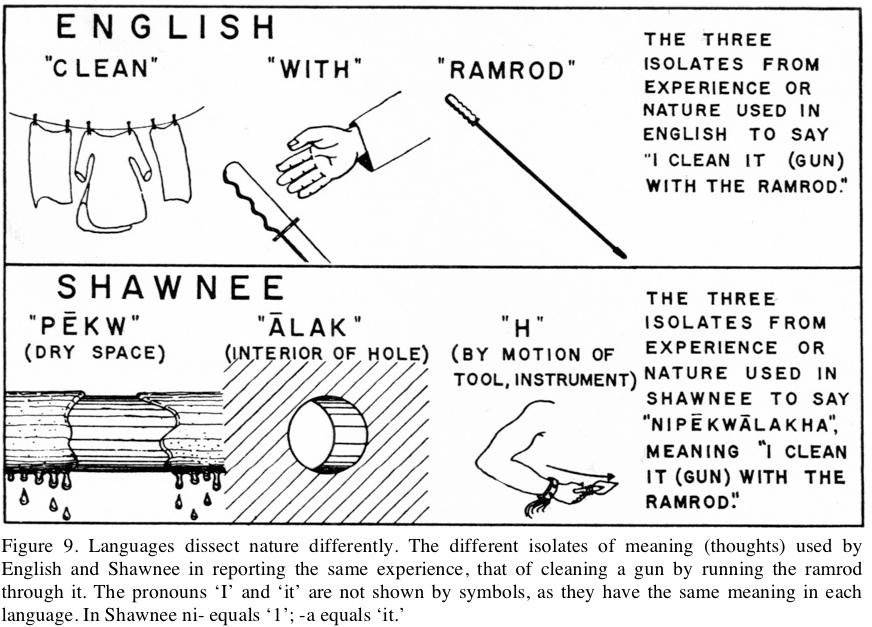
上の図は I clean it with the ramlod. と (I)(dry space)(interior of hole)(by motion of tool)(it) という英語と Shawnee 語それぞれの「世界の見方(=分節化)」の違いについての説明です。予め存在する何か(色名によって指示される光の波長等々)のうち、何を取り上げて、それにどんなラベルを貼るか(=色名で呼ぶか)といった次元の話ではなく、この図は認知体系に基づくもっと根本的な差異を表しています。
こうした異なる母語習得者間における認知体系の(言語の使用に限定された範囲での)相違によって生じる現象を、もしも計量的に扱うことができれば(不毛な水掛け論を脱して)ある程度信用できる言語相対論の実証研究も可能になると考えられます。逆にいえば、これが出来ないのならば言語相対論に学問としての未来はありません。
えーと、ぶっちゃけ言語相対論は(言語学としては)二十世紀末までには滅んだと言われています。たぶん「エスキモー語の雪語彙に関するデマ」の件はトドメになったか、またはその切っ掛けだったんじゃないでしょうか。
ですので、大学の言語学の授業で(先述のtweet発言者のように)「言語相対論は間違いなんやで」と学生を教え諭すことには形式上問題はありません。
>> インターネット言語学情報 : 言語的相対論(東郷雄二)
サイバー・スペースでも、言語相対論についてのサイトは数多い。最初にLinguistic Relativity Resouce Center (http://www.baylor.edu/~Erin_Greenawalt/relativity.html)を見てみよう。言語相対論の問題点の詳しい紹介とともに、著名な言語学者の賛成・反対意見が要約掲載されている。『言語を生み出す本能』(NHKブックス)の著者スティーヴン・ピンカーのように生得説に立つ研究者は、普遍主義に立脚している以上、サピア=ウォーフの仮説を頭から否定しているのは当然であろう。しかし心理言語学の分野でのカテゴリー化研究の第一人者エレノア・ロッシュのような研究者も、サピア=ウォーフの仮説には否定的であることがわかる。一方、レイコフのような認知言語学者は、この仮説に好意的であり、いみじくもそれぞれの言語観が言語相対論に対する態度に反映されていると言えよう。
2001年のこの文章にはこう書かれていますが、このページで紹介されたリンク先は現在はほとんどすべて消滅しています。この Linguistic Relativity Resouce Center に掲載されていたという内容も是非読んでみたかったのですけれど現時点では行方がわかりません。
上の引用に出ている『言語を生み出す本能』では Pullum(1991) を紹介し、そこであげられていた言語相対論批判の論点に則ってピンカーなりの解説を加えていました(補足するなら、今回とりあげた tweet の書き手もこれと同様の立脚点(言語生得説、普遍主義)からの批判であったと考えて良いでしょう)。
ピンカーらの批判点は大雑把にまとめると以下の二点です。
(1) 異質な連中は奇妙な言語を使ってるとか単なる偏見だよね?
(2) 母語とか関係なく興味があったら用語を細分化するよね?
これらについては機会をあらためて何か書きます(書かないかもしれませんけど...←!)。すごく簡単に反論しておくと、(1)も(2)も「普遍主義」的な前提で発想するために生じた問題でしかない、ということは言えると思います。
「エスキモーは野蛮人とかいう偏見に基づいて、アザラシの生の脂肪を喰うとかいうとんでもないデマ(そんな人間おるわけないやろ!常識で考えーや!)を言ったりするのの延長上やろが!変な世界の見方してて変な言語しゃべっとるとか!ひどいやないかーい」とかいってますけど、食べてはるやろ、実際の話。我々がアイスクリームを作るときに牛の乳から作った脂肪を使うところをアザラシのでやってはるだけで。「raw」の定義によりますけど。
「妻を他人に貸す」話なんかもこの部分だけを我々の文化の文脈を基準にして理解しようとするから「ありえへん!」てなるだけで、よーく話を聞けば案外理にかなっている感じもなくはないとかなるかもしれんし。
あと(2)に関してもそう。細分化が誰においても同じやり方で進むという前提でいってますよね、これ。根本から枝振りが変わるということは想定していない。ま、何をいっても水掛け論になるので控えますけど。
名前があがっている二人目のエレノア・ロッシュについてはすでに触れてありますので省略。
三人目で唯一言語相対論に好意的とされるレイコフですが言語学界では初めてレトリックを研究対象として本格的に取り上げた人物として知られています。普遍主義に基づいてレトリックの問題を扱う...というのは原理的に不可能な気がしますので、まあそういうもんかな、と。ここで注意すべきことは「認知言語学」と名乗っていてもレイコフのような立場でそういっている人と、ロッシュのように普遍主義に立脚しているのもいるという点です。
>> 『認知意味論』(ジョージレイコフ)
上記の著作、第18章で「Whorf and Relativism」について言及しているようです。私は読んでないので知りませんが(←!)。
結局のところ言語相対論そのものは実証に失敗し、非科学的な世迷い言として消えてしまったようです。しかし、その主張は「認知科学」や「科学哲学」の周辺に残留し、生き延びたらしい気配もあります。
また長くなってしまったので、適当にオチをつけて切り上げます。
確か先々月の中頃だったかと思うのですが radiko の放送大学で「言葉と発想」(伊藤笏康)という講義が放送されていました。偶然何気なく聞いていたのですが言語相対論的発想だと感じました。
第3回で「cat」と「ネコ」は同じだろうか、という話をしています。語が何を指し示しているのか、という次元とも(生成文法でいうような)文法のレベルとも違うところで生じている意味や認識のズレについて論じているように思ったのですが、いかがなもんでしょうか。
古くは『日本人の英語』(マーク・ピーターセン)でも指摘されていたのですが「chicken」と「ニワトリ」も同じではないようです。「I ate chicken.」の「chicken」は「鶏肉」のことを意味するので、まるごと一羽をイメージさせる「a chicken」を以下のような例文で使うと英語母語話者には「夜がふけて暗くなってきた裏庭で、友達が血と羽だらけの口元に微笑を浮かべながら、ふくらんだ腹を満足そうに撫でている(p.11)」という生き生きとした(?)情景が浮かんでくるそうです。
Last night, I ate a chicken in the backyard.
母語によって「世界の見え方」に(根源的なレベルで)違いが生じないのであれば、つまり人間誰しもがほぼ全く同じでありながら、どうやっても結局のところ英語学習者が(母語や個人の能力によって程度の差があっても)共通して冠詞の使用法を完全には習得できていない、という事実を普遍主義者はどう説明するのだろうか、という疑問があります。逆にいえば、この習得のできなさこそが言語相対論を裏付ける材料なのではないか、ということです。
概ね意思の疎通は図れているんだからこまけえことはいうなよ!と言われそうですし、そのこともあってあまり真剣に取沙汰されないのかもしれません。しかし、どれだけ学習した人であっても最終的にはネイティブにチェックして貰わないと公表できるレベルの文章は書けない、という事実は軽々に見過ごせることではありません。
習得の不完全性については学習者コーパスの研究などによって、もうすでに実証されているようにも思えますが、これを言語相対論と関連させる指摘はまだ存在していないのではないでしょうか。
また、日本語に関していえば、バイリンガルに見える帰国子女等々において「敬語」表現が不完全であることは(←安易な例で恐縮ですが、たとえば宇多田ヒカル氏など)日本語が「敬語」に代表される「待遇表現」に特徴がある言語であることを考えると、案外重要な、つまり多言語を完全に習得することの不可能性を示しているのかもしれないとか思ったり思わなかったり。
とりまそんな感じで。
しばらく前になりますが、こんな tweet をみました。
「エスキモーの言語には雪を表す単語がたくさんある」説がよぎりますね。あれも検索すると分かるんだけど、その数が数十個から数百個まで異様にばらついていて、ソースが全く示されない。
日本とアメリカの大学生では読書量に大きな差があって云々、という話を具体的な数値をあげつつ論じている人がいて、でもその数値の根拠は全く示されていない上に語る毎に違う数値になっているという事例が「エスキモーの言語には雪を表す単語がたくさんある」説(の都市伝説風デタラメ具合)と似ているとしています。
Wikipedia にもこれについての項目があって以下の通りです。
The claim that Eskimo languages have an unusually large number of words for snow is a widespread idea first voiced by Franz Boas and often used as a cliche when writing about how language may keep us more or less alert to the differences of the natural world.
英語では一つの語根「snow」の派生語や句や文でしか表されない雪の様々な形態毎に(雪原で生活しているため獲得された独自の世界観や認識が反映された)エスキモー語では個別の語根を割り当てているのでその数は膨大である、という説が流布しているのだとか(いつもの事情でクリシェをclicheで表記:汗)。(注:この説では「語根(roots)」と「語(words)」、「independent terms」などに関するややこしい区分などは大抵無視されて語られます。エスキモー語もグリーンランドからアラスカ北部までの東エスキモー語とアラスカ南西部の西エスキモー諸語では通訳が必要なくらい違っているのですが、それも無視されます。他にも「雪に関する」の範囲など、前提となる条件を示さずにこんな話を言い出す人間は言語について全く無知であるか極めていい加減なのだということが伺い知れます。つまりホラ吹きか愚か者のいずれかだ、ということです)
この状況に対して1986年に Laura Martin が調査を行ない、こうした説がどのように広がっていったのかを明らかにしました(実際には1982年に出来上がっていたのに "bonehead reviewers" のために世に出るのが4年も遅れたのだそうで...)。
その後1989年に Geoffrey K. Pullum が連載コラムでこのレポートを取り上げて解説したことでエスキモー語の雪に関する話がデマであるという主張が(それなりに)広く知られるようになったのだとか。
>> Pullum, G. K.:1989, The great Eskimo vocabulary hoax.
更に上記のコラムをまとめた本が1991年に出版される際に第19章に採録され、また代表的コラムとして書名にもなったようです。なお Pullum(1989)との異同は、冒頭に2ページ半ほどコラムの反響やら何やらについて言及しつつ Martin への情報提供を呼びかけたりしていることと末尾に「Yes, But How Many Really?」という付録が3ページ半ほど付け加わっている点あたりではないかと。
>> 『The Great Eskimo Vocabulary Hoax, and Other Irreverent Essays on the Study of Language』(Geoffrey K. Pullum)
さて、以下にPullum(1991)からちょいちょい摘んでみます。
そもそものはじまりは1911年に Boas がエスキモー語の雪概念を表す語根として「aput 'snow on the ground'」「gana 'falling snow'」「piqsirpoq 'drifting snow'」「qimuqsuq 'a snow drift'」の四つが存在すると書いたことのようです。(注:Pullum(1991)では falling snow に該当すると Boas が書いたエスキモー語が上記のように gana だと引用しているのですが Martin(1986)は qana ですし Boas の原論文でも qana です。snowflake にあたるのは qanik や qanuk ですので Pullum が Boas らの間違いを訂正して gana としたとも思えません。いいかげんな引用などを責め立てる文章のなかでこんなことができる生成文法信奉者のど厚かましさが羨ましいです...)しかしこのときは単に英語では water 以外にも水概念を表す liquid、lake、river、brook、rain、dew、wave、foam という separate roots が存在するが、雪概念に関しては snow の派生語などで処理しているという話の流れで紹介されていただけだったのだとか。
>> Boas, F.:1911, Introduction to Handbook of American Indian Languages.(1966年再刊版 Google Books pp.21-22)
Martin(1986)ではこういっています。
He intends to illustrate the noncomparability of language structures, not to examine their cultural or cognitive implications.(p.418)
言語構造の比較不能性(?)を指摘したのであって、文化だとか認知がどうのという話はしていないということかと(補足:Boas のものは「Grammatical Categories」という部分で「Differences in Categories of Different Languages」に続く「Limitation of the Number of Phonetic Groups Expressing Ideas」内での記述です)。
これを1940年に Benjamin Lee Whorf が自説を補強する題材として引用したことでおかしな流れが生まれたとしています。
>> Whorf, B. L.:1940, Science and Languages.(PDF)
Whorf(1940)では具体的なエスキモー語は示さず「falling snow」「snow on the ground」「snow packed hard like ice」「slushy snow」「wind-driven flying snow」という意味の語が存在するとしています。最初の二つは Boas と共通するものの後の三つは新出ですので、語(根?)は(最低でも)七つ(以上)が存在すると主張しているのと同義です。
Whorf は「the language we speak both affects and reflects our view of the world」(引用元:Wikipedia)というような言語観(Sapir-Whorf hypothesis、Whorfianism)を唱えていることで知られています。使用している言語が世界観や認識に影響し、またそれが言語にも反映されている...というような仮説ですから、エスキモーは英語話者と違った世界観や認識に基づいて雪の状況を細かく識別しており、それがエスキモー語に反映されているのだ、という証左(←?)と Boas の記述を捉えたのでしょう。それにしても Boas が英語とエスキモー語の類似性について述べた話を引用して対照性の証としたり、エスキモー語の知識もないのに語根を(創作して?)勝手に増やしたのは理解し難い行為です。
これ以降エスキモー語の雪の話は(英語の水概念の話の方は無視されつつ)最初の意図と異なった文脈でいい加減に引用されて歪みつつ広まっていき、たとえば Roger Brown による1958年の説では Whorf(1940)を引用しながら不思議なことに「three Eskimo words for snow」と主張しているそうです。
>> 『Words and Things』(Roger Brown)
なお Pullum はこの原因を「apparently getting this from figure 10 in Whorf's paper; perhaps he only looked at the pictures」と推察しています。参考までに示しますと「figure 10」は以下の通りです。
>> 
マルで囲んで例示された三つの雪の状態(降っている雪、積もっている雪、建材としての雪)を表す語が英語ではどれも snow だけれどもエスキモー語では別々の三つの語が該当する、という図解なのだと思われます。(確かに誤解しやすいかも...何も考えずに図しか見てなければ:笑?)。
Whorf(1940)の本文ではエスキモー語にはこれこれという意味の「語」が存在する、という例示であったので「語根」と「語」を取り違っていても影響は小さいのですが、Brown(1958) は端的に「語数」のみに話を限定してしまったため更に看過できない問題を発生させてしまいました。Martin(1986)には以下のような説明があります。
The structure of Eskimo grammar means that the number of "words" for snow is literally incalcuable, a conclusion that is inescapable for any other root as well.(p.419)
エスキモー語は屈折変化が複雑(名詞で273種、動詞がとる屈折接尾辞だけで400種以上)な上に、様々な概念を接尾辞で表しつつそれらを一つの語に盛り込んでいくため、ほとんど文として機能するような長大な単語がつくられるのだそうです。『エスキモー 極北の文化史』(宮岡伯人)によれば Yup'ik エスキモー語の qayaq(カヤック)を例にとると、qayar-pa-ka(俺のおおきいカヤック)といったものから果ては qayar-pa-li-yu-kapigte-l-qa(俺がおおきいカヤックをぜひ作ってやりたいこと)などという長大な単語に派生していくのだそうです。
日本語や英語で「雪」や「カヤック」という語を含む文の数が(いくらでも違ったものがつくり出せるため)計算不能なように、エスキモー語では語の数がいくつというような話は無意味ですし、雪に関する「語数」が三つだけということは有り得ません。
Brown(1958)のあとこれを引用するものが生じ、たとえば Carol Eastman による1975年の記述では「Eskimo languages have many words for snow」ということがエスキモー語の雪に関する語数が三つであるという引用のすぐ側に書かれているのだとか(three が many であるかは議論のわかれるところですが、実は英語にも snow の他に slush(partly melted snow)だとか sleet(snow and rain that fall when it is very cold)という別の語根があります。語義の引用は『ロングマン現代アメリカ英英辞典』から。あと日本語にもなっていてお馴染みの blizzard なんてのもあるので最低でも英語には雪概念を表す四つの語根があるため、エスキモー語より多いことになってしまいます)。もうこの時点で、ソースを引用はしてもそこから何を読み取るかべきかは考えられなくなってきていたのでしょう。
けれども、ここらあたりまでは典拠を示そうという姿勢は残っていたためか、語(根)数は3、4、7のいずれかという程度のバラつきです(典拠を示しつつそれを無視した主張をする人ばかり、というのも謎ですが...)。以降は全くソースに言及しないものが表れてきて更に滅茶苦茶になります。
中でも注目すべきデタラメとしてはニューヨークタイムズが1984年には語(根)数を100(←!)だとしてこの話を紹介していたのに1988年に同じ話を取り上げたときには48だとして五割近くも減らしている事例があげられています。
結局のところエスキモーの雪に関する語数デマについての Martin の調査結果としては最小値として3、最大値として400(1986の時点では200)という諸説が確認されたようです。
こうして Martin や Pullum による指摘がなされたあとでもやはりこの話は流布し続けます。たとえば少し前にベストセラーだった『国家の品格』(藤原正彦)にも出ていました。出版は2005年ですから21世紀になってもまだまだ生き残っているというわけです。
例えばエスキモーの間では、雪に関する言葉が百以上あると言います。東京でも、牡丹雪とか細雪とか粉雪とかドカ雪とか、色々あります。(p.103)
当然ソースは明示されていません。著名な数学者でも専門を離れればこの程度に過ぎないのだ、別に何でも正しく理解できるというわけでもないのだ、等々ということを身を以て示されている犠牲的精神には頭が下がります(←!)。
冗談はさておき、こうしたデマ話が根強く流布されていく原因の第一のものは単に人々は(研究者であってさえ)何かを人に話すときに典拠を(真剣かつ誠実に)確認したりはしない、そういう習慣はない、ということでしょう。インパクトの大きいウケル話をすることの方が正確な話をすることよりも(ずっと魅力的なので)優先されるのが一般的だというわけです。
the cautionary tale that serves to remind us of the intellectual protection to be found in the careful use of sources, the clear presentation of evidence, and, above all, the constant evaluation of our assumptions.(p.421)
Martin(1986)の最後に上記のようにあります。まともなソースの取り扱い、明確な証拠の提示、執拗な仮説検証などが行なわれなければ滅茶苦茶なことになるのだ、という教訓話として、つまりエスキモーの雪に関する話は(言語の違いで特定分野の語彙数が劇的に変わるというビックリ雑学ではなく)新たな文脈で語られるべきだということでしょうか。まあ、それはその通り。最初に引用した tweet の発話者もまさにこうした路線での発言だったと思います。
しかし、件の tweet では「その数が数十個から数百個まで」とありました。「数個から」じゃなくて「数十個から」となっています。ちょっとだけ正確さを欠いているとは言えるでしょう。「たくさんある」といえば普通は「数個」ではなく下限が「数十個」程度であろうと考えるのは妥当な推論ですが、意外にも事実は異なっていました。妙な揚げ足取りにきこえるでしょうが、これはこれで(デマ流布者のいい加減さのレベルを低く見積もってしまうという)先入観や思い込み、つまり bias から自由ではなかったという事例であるともいえます。
と、ここからが本題(?)なのですが枕の部分が長大になりすぎましたので、とりまこんな感じで次回に続きま...
おまけ:
『国家の品格』の著者がアレなのは、まあアレなわけですが、たとえば以下のような文脈で言及されたりすることもあります。引用は『「わかる」とは何か』(長尾真)から。刊行は2001年です。下線は引用者がつけました。
この記述的学問における問題は、分割がどのような観点からなされているか、同じ対象が他の観点から分割することはできないのか、という問題である。分割のしかたによって、分割されたそれぞれの部分の説明が異なってくるのはとうぜんである。たとえば人間という集団は、男女という立場から二分できるし、成年者と未成年者に分けることもできる。この場合に注意しなければならないことは、その判断基準は国によって違っているということである。私たちは虹は七色と思っているが、民族によっては五色であるところもあるし、雪でもイヌイットではひじょうに多くの種類を区別するという。明確に二分したつもりでも、そのどちらに入るかわからない場合もよく生じる。(p.44-45)
「divide and conquer」法についての説明の中でイヌイット(注:Inuit はカナダ・エスキモーの言語で「ヒト」を表す inuk の複数形を自称としたもの。他地域のエスキモーもそれぞれの言語に応じて動物や異民族と自分たちを区別する意味の語を自称としているのでエスキモー=イヌイットではない)が雪に関して「ひじょうに多くの種類を区別する」という話を紹介しています。
「語(根)数」が多いという話ではなく「多くの種類を区別する」という点に着目して語られているものの、いずれにせよ多寡の問題ではないはずですので、その点では残念ながらデマ話の流布に荷担してしまってはいるといえそうです。しかしせっかく分類基準の違いに関する話題の中で触れられているのですから「雪でもイヌイットでは qanik(降雪、雪片)、aput(積雪)、aniu(溶かして水にする雪)、auviq(切り出した雪塊)、pukak(きめ細かな雪)、piirtuq(吹雪)というように私たちとは異なった種類に区別する」というように(クドイですけども:笑?)書いていただければヨカッタノニナーなどと思わなくもありません。
上記のエスキモー語とその意味は前出の『エスキモー 極北の文化史』からの引用です。この本の著者は東エスキモー語にはこのように六つの語根があるとしています。Pullum や Martin の論述したところによれば、語根数について専門家の見解としても諸説あるものの「降っている雪」と「積もっている雪」の間に明確な区別があるという点では一致をみているようです。
ということは、少なくともこの点でなら(英語や)日本語話者の多くとイヌイットが異なった感覚を持っていると考えてはならない理由も無いように思えます。両者の世界認識に「違いがある」という考えはエスキモーへの偏見や先入観によるのだ!異なる言語話者間の差は個人差より小さいのだあああ!!と執拗かつ強引に主張する Pullum の方がよほど歪んでいるようにみえなくもありません。
Whorf らはソースを無視したり牽強付会で「すっごく違う!どんなに変な言語も有り得る!」と言っててサイアクですけど、それを攻撃する Pullum やピンカー(←次回ちょっと触れる予定)らの「みんな同じやって!違いなんかないんや!」というのも彼等の学術上の信念(というか自己都合)に基づく強弁なんじゃないんですかね...って話がしたいわけですが、先述の通り長くなりすぎましたので、今回はこんな感じで。
つらい。断捨離決行中でありまするがほんとにつらい。
特にリーフレット等々のよくわからん紙書類、古くなった服とかとかの処理でかなり苦しむ。で、苦しみつつも微妙な発見(?)をしたので(現実逃避しつつ)御報告です。下記の写真を御覧下さい。
>> 
『kNOB』(vol.5)というなにやら非売品らしきのに載っていたのですが、そこに書いてある通り「ボニーピンク」さんらしいのです。1995年9月に発行されたものだとか。
だいぶん白トビしているのでアレですけど現在のお顔とは結構違うような...(←普通に加齢による変化じゃねーの?←どーかなー...)。
>> 
まあ、女性の顔の見分けに関してはダメダメなことに自覚はありますので変な詮索はしませんが、それより上記二枚目の写真を御覧下さい。不健康そうな以外特に問題はなさそうに見えるかもしれませんけろ...。
>> 
この三枚目と比較すると...どっちかが「裏焼き」ですね。ホクロの位置が逆になってます。この冊子の中にはホクロの位置が確認できる程度に鮮明な写真が4枚あって(こっちから見て)「頬が右、顎が左」のが1枚、他3枚が「頬が左、顎が右」です。多数決でいうとボニーピンク氏のホクロ配置は後者かと思いきや...『Even So』のジャッケットなんかで確認すると正解は前者だったりします。ひどい。
現在はデジタルカメラで撮影するんでしょうから意図的にやらない限りは「裏焼き」は発生しないとは思うんで、これは1995年ならではの現象かな、っと。20年近くも昔なんですね...。
1995年といえばいろんな大事件があった年です。
>> 1995年(Wikipedia)
7月1日 - 札幌・東京地区を皮切りにPHSサービス営業開始。
これは知らんかった。ま、大事件とはいえませんけど。
真面目にいうと阪神淡路大震災、地下鉄サリン事件、Windows95の発売といったのが目に付くところでしょうか。時代の変化を感じさせます。「村山談話」とかいうのもこの年ですね。
ところが『数字からみた日本人のこころ』(林知己夫)はこの年の7月に出版されているものの、なぜかこんなことをいっています。
私は、日本の歴史はほぼ一五年をひと区切りとして周期的な変化を繰り返しているとみている。(略)私はかつての著作で、持論の一五年変動説から考えて、昭和六十五年ころには必ず大きな変化が訪れるはずだと記したことがある。一九八九(昭和六四)年の昭和天皇崩御、そして平成という新しい時代がスタートし、この時期を境に国際化と環境問題が錦の御旗となって第二の文明開化とでもいうべき現象が始まった。そして、もしも私の説が正しければ、次の大変化は平成一七年、西暦二〇〇五年頃に起こるはずである。(pp.130-131)
ちょっ w w w 95年にすでに大変化は起きてたやないですか!...と思ったのですが、これは90年頃から始まった変化の一環ということなのかもしれません。2005年に大変化ってありましたかね...
>> 2005年(Wikipedia)
3月18日 - 旧声優陣によるテレビ朝日系列「ドラえもん」が放送終了。次週より、新声優陣バージョンが放送開始。
確かに大変化...(笑?)。というか、自民党が所謂「郵政選挙」で大勝した年なんですね。そのほかには「惑星探査機はやぶさが小惑星イトカワへの着陸と岩石の採取に成功」というのもあったのか。「日本の人口が1899年の統計開始以来初の自然減となった」というのも大きいかな。
最初はハズレに見えてたんですがなかなかアレですね。さすがは林先生、なんとなく納得させられてしまった...。この本では、この他にもたくさん「質的なものを数量化して把握する方法」を用いて得られた知見について言及されています。どれも興味深く示唆に富んだものばかりなのですが、中でも「!」となったのは「"古い"="悪い"時代の終焉」という話です。
そうした近代化の努力を重ねるうちに、日本人の意識の中に、どんなものに対しても、伝統と近代を対比させて考える、考え方の筋が定着してしまったわけである。(略)「家庭をそういうものだと考えるのは古い」という場合と、「社会をそういうふうに考えるのは古い」という場合の「古い」は、海外ではなんら関連がない。家庭には家庭の、社会には社会の新旧の判断基準が存在しているのである。つまり、あらゆるものを「伝統---近代」という筋で一律に切ってしまうのは日本人だけなのである。そして、こうした考え方の筋の存在が、日本の国民性の特徴だったわけである。(pp.88-89)
ちょっとわかりにくい書き方にみえますが、「新しい・良い・近代」と「古い・悪い・伝統」という対比が「考え方の筋」になっている日本人が多かったということのようです。これに対して、他の国の人達は例えば「新しい」と「古い」の対比はあっても、それが「良い」と「悪い」だとか「(進歩的で文化的な?)近代」と「(悪しき?迷信に凝り固まった有害無益の?)伝統」という対比と常に連動させて考えているわけではない、ということかと。
私自身は(日本生まれで日本育ちのコテコテの純ジャパですが:汗)この「日本の国民性の特徴」は持ち合わせていません。そして「あー、相手はこれに基づいて話をしてたから噛み合なかったんだな」というふうに思い当たる事例がいくつかあります。「これは新しいんだよ!」というのが「これはすばらしいんだ!」という意味だったのか...とかとか。
それと、「反日」とか「売国」と批難されるような行動を積極的にとっている人々(←国籍は日本)こそが、むしろ「日本の国民性の特徴」とされる考え方に忠実なのかもしれません(注:より正確には、この「考え方の筋」に加えて日本的な「情」を普遍的なものだと勘違いしての「アジアは一つ」という思い込みがあるのでしょう。本書pp.173-178で東南アジアからの留学生と日本人学生を対象にした比較調査について言及してます)。
日本人の伝統と近代を対比させる考え方の筋が、若い年齢層において動揺を始めたのが一九七三(昭和四八)年であり、それ以降、次第にその崩壊が上の年齢層に這い上がってきて、全体的に揺らいでいることは先に述べた通りである。注目すべきなのは、「しきたり」に対する意識と先の四つの道徳観の順位が混乱をみせ始め、そしてかつてとは異なる形に安定していく時期が、この考え方の筋の崩壊とピッタリ重なることである。(p.117)
ここでいう「四つの道徳観」というのは「親孝行」「恩返し」「自由の尊重」「権利の尊重」のことです。前二つが「日本的、伝統的な道徳観」で後ろの二つが「アメリカ的、戦後的な道徳観」なものになっています。1963年から一位は常に「親孝行」なのだそうですが、最初は「権利の尊重」が二位だったのに1978年に四位に落ちてしまい、以降ずっと一位と二位が「伝統的」な道徳観で占められているのだそうです。
また、「しきたり」に対する意識、というのは「自分が正しいと思えば世のしきたりに反しても、それを押し通すべきだと思いますか」という問いへの返答傾向に関する話です。1953年から1978年の直前までは「押し通せ」がもっとも多い回答であり、1978年には「(しきたりに)従え」が一瞬逆転して最上位になるものの、それ以降こうした両極端の意見は減って(1953年にはぶっちぎりでドベだった)「場合による」がトップを維持していきます。
一九五三(昭和二八)年といえば、終戦からまだ八年しか経っていない時期であり、まさにアメリカ的民主主義、アメリカ的教育理論が猛威をふるっていた時代である。この時代のとらえ方は、「しきたり」イコール「旧来の陋習」であり、つまり「しきたり」イコール悪だったわけである。かつての日本的なるものすべてを否定し去ろうという時代にあっては、こうした意識が生まれるのも当然のなりゆきだった。また、「正しかったら押し通せ」という、これまたアメリカ的な自己主張も、おおいにマスコミが煽っていたのである。(p.111)
ここでいう「正しかったら」は現在の(私の感覚で考えるような)「正しい/正しくない」とは違った基準の話だと思われます。おそらく「日本的ではない」くらいの意味かと。
紋付袴や白無垢での結婚式、茶道や華道などといったものが終戦後にはもっともダサイものとして排斥されていたのだとか。感覚的にはなかなかわかりにくい部分があります。もしかすると「ビートルズ」だとか「ロック」とかいうのに妙に思い入れがある人達とかならそういう感覚もわかるのかもしれません。
「新しい」と「良い」はイコールではない(新しいということは不安定だったりして信頼性が低く見通しが立たないということでもある)し、「古い」「しきたり」には、改善されるべき問題点だけでなく、それが続いて来た要因となる何らかの利点もあるはずです。古いか新しいかで自動的に「正しい」かどうかが決まる、何かが「正しい」かどうかはそれが「新しい」かにのみ依拠しているのだ!...(実際にどうであるかは関係ない!)というキ○ガイじみた考え方が主流だった時代があったなんて恐ろしい気がします。
フツーに考えたら、やっぱり「場合による」としか答えようがない。
ところで昨今の「学校での英語教育にTOEFL導入!まったなし!!」的な人々の心(?)に真っ当な反対意見が全然届いてないっぽいのもやっぱしコレ系のアレですかね。おーこわ。
そんな感じで。
震災のあと「絆」という文字を目にする機会が増えたように思えました。ただこの漢字は日本語と Mandarin(a.k.a.北京語、普通話etc.)という異なる記号体系で使われた場合に著しく意味が異なってしまうという問題を抱えていたようです。
他にも偲咄掟沖萩鵺串唄森呆淋預調儲砌...etc.といった漢字でそうした違いは顕在化します。もともと違う記号体系で使用されている文字なので意味も異なっているのが常態のはずですが、そうしたことは普段あまり意識されていません。それで面食らってしまうのでしょう。
旧正月明けの社内の年頭あいさつで、同氏は、日本の震災後の「絆」の尊さに触れつつ、日本人と中国人との間でも「絆」を大事にしながらビジネスを今年もがんばっていこう、とスピーチしようとした。事前に、中国人スタッフに中国語訳を頼んだところ、彼女は原稿に出てくる「絆」の意味が理解できないとの困惑を見せた。嫌な予感がした同氏が中日辞書を開いたところ、中国語における「絆」の意味が全く異なることに気付き、冷や汗が出たという。
『デイリーコンサイス』をみるとこの語が動詞で「つまずく、つまずかせる、邪魔をする」という語義であると書いてあります。「絆他一交」で「足をからめて彼をつまずかせる」意なのだとか。「絆脚石」で「障害物、邪魔物」とか悪い意味しかないようです。
『中国語小辞典』によれば ban(aは第四声)と発音して「つな、馬のきずな、わな、足が障害物にぶつかる、からみつく、わななどにひっかかる」という意味だとか。「絆倒」「絆脚」「絆子(わな)/使絆子(わなをかける)」などが用例として出ています。
しみじみひどい(笑)。 pan(aは第四声)と読んで「ボタンかけ、ひもどめ、とって」の意とする用法もあるようですが...(←これは「袢」のことだという説も...←後述する『広韻』の「袢」項目では詩経から「是紲袢也」を引用していて「紲」も訓が「きずな」で...ああっ!!めんどい!!!ksg)。
しかし、この問題は漢字に惑わされさえしなければどうということはないはずなんです。「きずな」という言葉が日本語にあって(その記号体系内の)他の共存する語との関係の中で自身の意味の領域を持っているわけですから、ただその語を(Mandarin という別の体系において該当する語に)翻訳して貰えばよかっただけのことじゃないでしょうか。
漢字「絆」とは切り離して単に「きずな」を「情義」とか「親情」と訳せばいいだけのことです。
「絆」という字とその語義がもともとどういうものだったのかについて『説文解字五音韻譜』をみてみます。これは『説文解字』と同じ解説が載っているものの、部首ごとの漢字の配置が韻書のような順になっているという非常にコンセプトがおかしい字書なわけですが。
>> 許氏説文解字五音韻譜(早大古典籍総合データベース)
註:上記サイトに「本データベースに収載された画像、書誌情報を当館に無断でテレビ放映、出版物(各種電子媒体を含む)、ホームページ等で使用することは一切認めておりません」と書かれているのに気づきましたので念のため引用画像を削除しておきます。リンクは「学術目的のホームページへのリンク」に限り無断でも許してくださる御様子なので上のリンクは残しておきます。「へのリンク」となっているのがやや「?」ですけれど。
「糸」は最後の十二巻に出てきます。
>>  (3枚目の見開き画像参照)
(3枚目の見開き画像参照)
篆書なので何がなんだかよくわかりません。しかしなんとか「絆」を見つけました。
>> (29枚目の見開き画像参照)
「馬(執+糸)也 従糸半声 博幔切」(註:「(執+糸)」は「繋」に見掛けが似た「絆」と同じ意味の字らしいです...ていうか日記ツールをUnicode対応に変えないとダメだぬ:滝汗)というようなことが書いてあります。語義は「馬の(執+糸)」らしい(註:語義の最後、大抵は「也」の前になるのですが、そこに書かれている送り仮名らしき字が読めません。頻繁に出てくるのですが...←うーん、右下がりなので変ですけど「ソ」かなあ...「馬(執+糸)ゾ」「馬の(執+糸)である」?)。「糸に従い半の声」は意味(意符)が「糸」の系列(?)で発音(声符)は「半」だということかと。「博幔の切」は声母が「博」と同じで韻母が「幔」と同じだということです。「絆」の母音より前の子音部分の発音と「博」の同じ部分の発音が一致し、「絆」の声母以外の残りと「幔」の同様の部分の発音が同じだ...という、この方式で発音を表記したのを反切といいます。
『説文解字』は普通の(?)字書なので(五音韻譜であっても)部首でまとめられていますが、別の種類の辞典として韻書というのもあります。漢詩で韻を踏むのに使う字書です。科挙の勉強には必須だったとかなんだとか。
>> 
これがそのタイプの字書『広韻』(陳彭年 1986 『校正宋本廣韻 附索引』 藝文印書舘)に載っている「絆」です。白黒スキャンにしてみたんですが見辛いかも。「半」と(声母も韻母も声調も)全く同じ発音をする七字のうちの一つとされています。
なので「半」の反切は先述した『説文解字』と同じ「博幔切」になって...ませんね(汗)。「博慢切」と書いてあって「慢」という字にバツがついてます。間違いってことかな?
『広韻』は韻母を206韻に分類しています。Mandarin と違ってこの時代の声調は同じ四声であっても「平/上/去/入」なのですが、このうち「去声」に属する第29番目の見出し字「換」と同じ韻母を持つ字の中に「半」という小見出しが設けてあります。小見出しの下にまとめられているのは声母も一致する字です。
「幔」は「換」に含まれる「縵」という小見出しの下にあるので「絆」や「半」と韻母が一致しますが「慢」は第30番目の「諌」という大見出しの下に含まれる字なので韻母が異なります。おそらく校正の結果バツが入れられたんでしょう。
さて、肝心の語義ですが「羈絆」と再帰的なことが書かれています。一応「きはん」と読む熟語で「牛馬をつなぐロープ」の意みたいです。転じて「束縛する」的な語義を持っているのだとか。「羈束」だと「きそく」。「羈」は単独では「たづな」。
そういえばスマホをつかってパソコンをインターネット接続することを指す「テザリング(thetering)」の theter も同じようにもともとは「牛馬をつなぐロープ」の意味で、「足枷」「限界」だとか「縛られる」的なマイナスの用法が主のようです。
「きずな」に悪い意味はありませんが日本語でも「絆す(ほだす)」「絆される(ほだされる)」「絆し(ほだし)」だと Mandarin や英語の用法に近いようです。ただ比喩的に使った場合の束縛の理由は策略的なものではなく「情愛」に関するもののようですが。
あとついでなのでもうひとつ『韻鏡』(龍宇純 1982 『韻鏡校注』 藝文印書舘)で調べた結果も載せておきます。発音だけしかわかりませんが。
>> 
『韻鏡』は日本語の五十音図のように漢字を分類したもので全43枚の表から出来ています。タテに声母(各項目に該当する「三十六字母」が指定されています)をとり、ヨコは韻母です。五十音図での仮名文字にあたるのが『広韻』の小見出し字なので「絆」という字そのものは出てきません。
「半」が上から三つ目の(去声の)枠組みの中の右端一番上にあります。それから左にずーっとみていった先にある「換」は『広韻』去声第29韻の見出し字です。
引用した表からは「半」が「唇音」で「清」に分類されていることから、声母は具体的には p (唇音重)か f(唇音軽)のはずです(← p みたいですね、よくわかりませんが:汗)。ところが Mandarin の声母 b(唇音重で濁)は先述の通り発音が異なります。
とはいっても当時 p という音価の声母を持っていたとされる(三十六字母のうち)「唇音重で清」に該当する字(←見た目が「幇」に似ていて Mandarin での発音が bang で a が陰平のヤツ←ちょっ w)自身の音価も p から b に現在変わってしまっているようなので音韻における関係性の構造自体はさほど変化していないのかもしれません。
『韻鏡』(と、ついでに『五十音図』:笑)は「悉曇学」というサンスクリット語(というか梵字)研究から生まれたものらしく、こうした複数の記号体系を背景とした音韻論的アプローチが存在していたことから、相互参照等々によって当時の音韻や音価を探るのに今日では役立っているようです。
漢字を巡る問題ということで『本居宣長』(子安宣邦)へ話は飛びます。
天地は、阿米都知(アメツチ)の漢字にして、天は阿米(アメ)なり。かくて阿米てふ名(な)の義(こころ)は、いまだ思ひ得ず。そもそももろもろの言(こと)の、しか云ふ本の意(こころ)を釈(と)くは、甚だ難きわざなるを、強ひて解むとすれば、必ず僻(ひが)める説(こと)の出で来るものなり。(p.85)
孫引きですが、これが『古事記』上巻「神代」の冒頭部分に『古事記伝』において宣長がつけた注釈なのだそうです。
「天地」は「アメ」と「ツチ」という日本語を表記した漢字である、としているにもかかわらず「アメの意味はわからない」ともいっています(註:もちろん「ツチ」もそうです)。凡人(←たとえば俺ちゃん w )であれば「天」という漢字に与えられる意味と「アメ」のそれも同じと思い込んでわかった気になるところですが、やはり彼はちょっと違う(感嘆)。
『古事記』というのは漢字表記で漢文混じりの日本語という非常にやっかいな文体で書かれています。宣長の時代にはもう誰にも判読不能だったのだとか。
>> 
これを解読するのは「漢文訓読」とは勝手が違います。日本語の(音声による)記号体系に基づいた叙述を、全く別の記号体系で使用されている文字(というよりも語彙)を使って記録したものが対象だからです。漢字表記であっても漢文ではありません。
天地初発之時(漢字表記和文)
heaven earth first begin of time(英単語表記和文?)
感覚的にわかりやすく(?)するため該当部分を「英単語表記和文」(?)でも書き記してみました。『古事記』の解読とはこうしたものから「あめつちはじめのとき」という日本語を復元する作業を指すのです。
一般的な日本語母語話者にとって(現在はおろか宣長の時代の人間でさえ)漢字はその意味も含めて日本語の一部として全く違和なくシームレスに受け入れられており、たとえば日本語における「天」の意味を知ろうとして「天」という漢字の語義を様々な文献資料で調べることが実は見当違いである、ということには思い至りません。
「絆」と「きずな」を切り離して考えることがなかなかできなかったりするのも根は一緒です。
「きずな」の意味を知ろうとして「絆」という漢字そのものを調べてもかえって混乱してしまいます。Mandarin(つまり別の記号体系)での意味を参照することも無意味というか有害です。「牛馬をつなぐロープ」の意味、そしておそらく「牛馬」に対する日本語話者の感情のあり方等々が影響して(Mandarin とは異なる用法の変化を経て)「絆」という字に現在の日本語内での意味が与えられているのでしょう。
儒学者の荻生徂徠はこのことに(反対方向から)気づき、日本人が吉備真備以来行なって来た漢文訓読法では漢文が実は理解できていないはずだ、という指摘をしたのだとか。
一方、同様の理解のもと宣長は「国学」の見地から「漢国(からくに)」の記号体系に起因する影響を排除して上代(奈良時代あたり)の日本語を復元しようとします。
そもそも意(こころ)と事(こと)と言(ことば)とは、みな相称(かな)へる物にして、上つ代は、意も事も言も上つ代、後の代は、意も事も言も後の代、漢国(からくに)は、意も事も言も漢国なるを、書紀は、後の代の意をもて、上つ代の事を記し、漢国の言をもて、皇国(みくに)の意を記されたる故に、あひかなはざること多かるを、此の記はいささかもさかしらを加へずて、古へより云ひ伝へたるままに記されたれば、その意も事も言も相称ひて、皆上つ代の実(まこと)なり。(p.73)
またしても孫引きですが『古事記伝』の総論から。
「意(こころ)」と「事(こと)」と「言(ことば)」の三つはセットになって用いられている、という認識が示されています。これはまさしく記号論です。それもソシュール系の記号論(記号学)に近いタイプだと思われます。ソシュールの(講義をまとめた)『一般言語学講義』の百年以上前に言語の恣意性に気づいていたわけです...二百年後でも口先だけで実際は理解してないのが多数派なのに(笑?)。
『日本書紀』は後の時代の「意(こころ)」で上代の「事(こと)」を記述している点がまずズレていると指摘しています。また、漢国(これは漢王朝に限定しているわけではありません:汗)の「言(ことば)」で皇国(=日本)の「意(こころ)」を記述したためやはりズレているともいっています。
どうも単純に「言」には「シニフィアン signifier」が該当します、というものでもないようです。文法的なものも含めての「言」だと見なしているように読めます(『日本書紀』は漢文で書かれているので)。また表記に使われた文字が何であるか、という点には頓着していないようです。
こうした様子から、逆になぜ(デリダによる音声中心主義批判とかもありますが)ソシュールが文字を二次的なものとし、彼の記号学で扱う本来の対象を音声(sound-image)だと主張したのかもわかるような気がしてきます。
『日本書紀』において漢文で記された日本語の「意」とは、とりあえず時代や場所によって変化するもののようです。上代と後の時代では異なり、また漢国と日本でも違う。
『本居宣長』の著者は下のように解釈しています。
ここで「意」とは「皇国の意」とか「漢意」と宣長がいうように、ある思想とか思想形態をもって考えた方がよいことばである。そこからすれば、「意と事と言とは、みな相称へる物」ということばから浮かび上がってくるのは、むしろ時間的、空間的な規定を負った言語の相対的な姿である。まさしくそれは、それぞれの時代のそれぞれの国の「言語のさま」である。この「言語のさま」に、ソシュールが「ランガージュ」に対していう「ラング」をあてて考えることもできるだろう。丸山圭三郎氏は「人間のもつ普遍的な言語能力」であるランガージュに対して、ラングを「個別言語共同体で用いられている多種多様な国語体である」と説いている(『ソシュールの思想』岩波書店)。あの「意」と「事」と「言」との相即をいう宣長のことばが指し示しているのは、それぞれの思想や習俗の厚みをもった「言語のさま」、すなわち「国語体」であるだろう。宣長はやがてそれを「敷島のやまとことば」として成立させるだろう。(pp.73-74)
宣長における「意・事・言」三点セットの「意・事・言」を知ろうとして上記の文章を参照すると、更にその「意・事・言」がわからなくて混乱をきたすという再帰的悪循環が...。
たとえば「事(こと)」は「シニフィエ signified」だろう、なぜならモノではなくコトなので抽象的な何か、つまり概念であると理解できるからだ...とかいうのも「甚だ難きわざなるを、強ひて解むとすれば、必ず僻める」事例になりそうですしおすし。
これ系の案件をまとめあげるのってホント至難の技だぬ。上田秋成との論争とかソシュールがサンスクリット語の専門家だったこととか色々書きたいことはあるんだけど。ていうか、いったいいつになったらロンドン学派の理論にまで辿り着けるのか...そもそもテクスト論の準備というか整理でやってるんだけど、あーもーあーもー!
体力も気力も尽きたし時間もないので、とりまこんな漢字、いや感じで。
前々回および前回の続きです。ひとことでいうと『記号と再帰』の欠陥は「羊頭狗肉」ならぬ「semiotics 頭 semantics 肉」である点から生じています。
semiotics が「記号論」で semantics は(所謂)「意味論」のことです。
「意味論」は狭義には形式意味論ですが記号論理学風言語論の数々および生成文法とその周辺なども含むと考えてよいでしょう。集合論や論理学に基づいて言語を階層構造で捉えたものです。コンピュータの仕組みもこの延長上にあるので計算機言語には当然のように「論理演算子」などが備わっています。
なので「semiotics の知見を計算機言語に適用する」というのなら非常に画期的な試みですけれども「semantics の知見を...」ということでは特に新たな価値は見出せません。
『記号と再帰』では「semiotics の知見を計算機言語に適用することでアホな文系どもがグダグダやっている問題をスッキリ解決したったわ w w w 」と高らかに宣言しています。ですが実際の内容は「ソシュールやパースに関する引用などを使って semiotics を扱っているように装いつつ semantics の話に終始する」というものでした。
驚くべきことです、これは。『バカの壁』(養老孟司)を想起するほどに。
ソシュールによると「言葉が意味しているもの」(シニフィアン)と、「言葉によって意味されるもの」(シニフィエ)、という風にそれぞれが説明されます。この表現はわかったようなわからないような物言いです。実際、ソシュールは難解だとされています。
が、これまでの説明の流れでいえば、「意味しているもの」は頭の中のリンゴで、「意味されるもの」は本当に机の上にあるリンゴだと考えればよい。ソシュールも、やはり言葉の二つの側面に注目したのだ、と考えられます。(p.70)
『バカの壁』からの引用です。シニフィエが「本当に机の上にあるリンゴ」だというのはよく見かけるタイプのありふれた間違いなのですが、シニフィアンを「頭の中のリンゴ」だとしたのは斬新です。なんでこんなことになっているのでしょうか?
「ソシュールによると」の次がまず嘘です。後で言い換えたみたいに「意味しているもの」だけであればまだよかったのですが、その場合でも「指し示している側」ではなく「指し示されている側」ともとれる曖昧な表現です。事実それもあってかシニフィアンをシニフィエ的な「頭の中のリンゴ」とするちょっと見ない間違いをやらかしています。
いずれにせよ勝手に「言葉が」を付け足すことで「リンゴという文字列や発話」部分が登場しない独自のテレパシー言語学(?)にソシュールを荷担させているのです。
この引用部分前後にも英語の冠詞や日本語の助詞について「聞き齧った話を調べもせず理解もしないまま自己流の思いつきと混ぜ合わせたグチャグチャのデタラメをいい気になって語る」内容が垂れ流されていました。
さて、話を戻します。
『記号と再帰』の著者は『バカの壁』のそれほど無防備ではありません(たぶん『バカの壁』の著者ほどはまだ無敵ではないからでしょう)。でも通底する姿勢は似た様なものです。特にソシュールの扱いに関しては同レベルといってもよいかもしれません。
強引な自説への誘導のために細かく改変や付けたしを混ぜ込んでくる手法に類似点がみられます。
「関数型言語」「オブジェクト指向型言語」と並ぶ人工言語側の重要項目に「LG」というのがありますが、この用語はなぜか唐突に出てきます。引用は『記号と再帰』から。
本章の残りでは、この文法とそれに基づいて生成される言語を LG と記述する。(p.60)
ラムダ計算に関する記述の中で言及されますので LG の L は lambda のことかもしれません。また「この文法」云々とあるので G は grammar である可能性はあります。それにしても「文法」や「言語」はラムダ計算そのままですので LC(lambda calculus)でよかったんじゃないでしょうか。
なにはともあれ、この LG を介することによってソシュールの「記号」とパースのそれとが等価であることが示されるそうです。加えてソシュールの「記号」が持っていた逆説も解消されるのだとか。
ソシュールの転回は、記号が「名称のリスト」であることを否定したことである。具体的には、シニフィアンに、名前付与の機能だけでなく、分節の機能も持たせることにより、この転回を行なった。つまり、ソシュールにおいてはシニフィアンがシニフィエを分節する。ソシュール以降の多くの二元論では分節の機能は指示子が持つ。(p.65)
ここでいう「指示子」というのは「シニフィアン」及び「表意体」にあたるものとして『記号と再帰』が採用した用語です。
「シニフィアンがシニフィエを分節する」と「ソシュール以降の多くの二元論」の二箇所に関しては典拠が明らかにされていないのが気になります。特に「ソシュール以降の多くの二元論」というのは(上記『バカの壁』に類する間違い事例以外に)思い当たるものがありません。三元論なら色々あるのは知っていますし、「名称のリスト」であることを否定したのは本当ですけれど。
ソシュールの二元論以降は、指示子が名前付与と分節の両方の役割を担っているとされた。また、指示子は恣意的である。しかしながら、なぜ、指示子が分節の機能を果たし、同時に恣意的でありうるのか、という、本章の最初の節で示したソシュールが逆説とした点については、この時点ではまだ全く明らかとなっていはいない。(p.69)
先に引用した部分と同じ内容ですが「ソシュールが逆説とした点」と述べているところに変化があります。
今まで無かった指示子が(借用語などとして)新規に現れたせいで、従来からあった語との間で新たに「分節」が起こることはあります。たとえば...女性ファッション誌などはそうした作用を見越して頻繁に新語の提示を行なっています。具体例についてはその方面は疎いのでご勘弁を(汗)。
以前読んだことがある研究論文でいうと magnate と tycoon についてのものがありました。
ちなみに両語を Google Ngram Viewer でみると以下の通りです。
>> 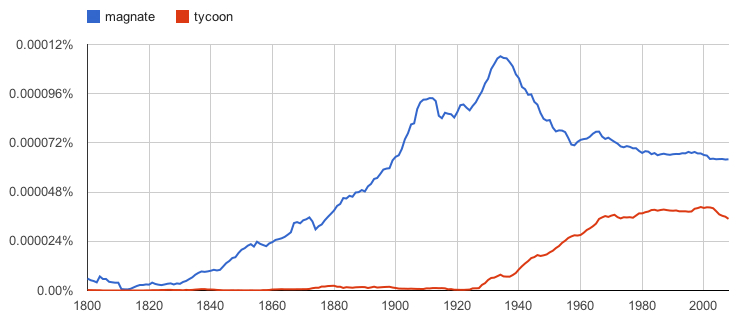
もともと magnate という語が使われていたところに日本語から tycoon(大君)が入り込んできて、現在ではどちらも概ね「a successful man in business, a man of wealth」という意味で使われているのだとか。Ngram の結果からもそんな使用状況であろうことは推察できました。
これらは語意が重複したまま併用されているものの「使用」を調べると差異が見つかるのだそうです。つまり別々の記号として機能しているということがわかります。ソシュールの説によると「記号」は他の「記号」との「差異」によってのみ規定されるのだとか。
magnate は tycoon という(英語内では新たに生じた)シニフィアンによって自身のシニフィエに変容を受けました。こういう意味では「指示子が分節の機能を果たし」ているのかもしれません。
けれどもソシュールの記号学に則るならば分節機能を果たしているのは「ラング」とされるはずです。個々の記号ではなく体系全体に関わる規約的な何かのレベルでこの現象は起こった、と考えるべきでしょう。
この場合なら英語において magnate 周辺部分での再分節が起き、それによって英語全体が再構成されたことになります。magnate と tycoon は他の語すべてと新たな関係を構築し直すことになったのであって magnate のシニフィエが分割されただけで済んだ現象ではありません。
また、その契機であり新たな分節部分でシニフィアンとなったのが単に偶々 tycoon だったということです。絶対に tycoon でないといけなかった理由は見当たりません。
シニフィアンが自身を部分として持つ「記号」にとってのシニフィエを分節する機能を果たすにもかかわらず、シニフィアンとシニフィエの関係が恣意的であることを『記号と再帰』では「逆説」であるとしていましたが、そのような逆説は LG の助けを借りるまでもなく解消されます。と、いうよりも元々存在していません。ラングについて全く言及していないためと、故意の誘導によって擬似的に生じた「逆説」なのだとみなすべきでしょう(補足:近年 MMO ゲームなどの利用者から広まったとみられる「課金する」を「有料サービスを利用する」つまり従来とは逆に「料金を課す」のではなく「料金を支払う」意味で用いる事例があります>> ソーシャルゲームの課金と現状認識。このように今までに無かった新しい状況に対して分節が先に起き、既存の語のシニフィアンを転用する現象もあります。シニフィアンだけが分節機能を果たすとはいえないでしょう)。
擬似難問の提起とその解消によって成果を捏造する、という繰り返しが『記号と再帰』の正体です。それによって実際に名声と評価を得(るのと引き換えにソシュールに関するトンデモ説を広めて記号論を貶め)てしまっているのが困りものですが。
シニフィアンとシニフィエの二つがあれば、シニフィアンが先かシニフィエが先か、同時かのいずれしかない。ソシュール以前はシニフィエが常に先であるのに対し、ソシュールの記号においては同時である。一方、ラムダ項ではシニフィアンとシニフィエはバラバラに導入され、指示子と内容を同時に導入することは、これまで見た LG の枠組みでは、そもそもできない。シニフィアンとシニフィエを同時に導入するには、LG を拡張する必要がある。(pp.69-70)
「指示子と内容を同時に導入することは」とあるように『記号と再帰』では「シニフィエ」や「(直接)対象」にあたるものを「内容」と呼んでいます。こうした用語の対応は p.51 の表3.1にまとめられていて概ね以下の通りです。
| 二元論 | シニフィアン | シニフィエ | 全体論的価値 |
| 三元論 | 表意体 | 直接対象 | 解釈項 |
| 新仮説 | 指示子 | 内容 | 使用 |
「対象」ではなく「直接対象」なのは記号に外在する「動的対象」を除いて心的なものだけを残したからなのだとか。
さて、ラムダ項ではシニフィアンとシニフィエがバラバラに導入されるそうです。これは何をいっているのでしょうか。
『記号と再帰』によれば λf.f (f 3) と λx.x+1 の二つのラムダ項はシニフィアンを持たない状態で分節済みなのだ、とされます。
これが並置されて、つまり計算される状態になったときにはじめて右項に左項から f というシニフィアンが付与されるのだとか。それによってβ簡約が起きて左項の f がすべて右項に置き換えられたら(計算は右から左に行なわれるので)次にカッコ内にある λx.x+1 3 の 3 に x というシニフィアンが与えられて 4 になり... と最終的には 5 という結果に至る過程を何やら記号の「使用」と言いたいようです。
このような、二つの記号を関係付けるための名前という観点は、二元論に基づくどの現代記号論の記号モデルにも直接的には言及されるものではない。ソシュールは、記号同士の関わりについて、差異や、また連辞(syntagm)として間接的に言及しているが、記号が具体的にどのように関係しうるのかについては述べていない。(p.67-68)
「二元論に基づく現代記号論の記号モデル」がラムダ計算のような(単純で決定論的な)事例を扱っていないのは、それが記号論とは直接関係のないものだからです。何度か述べてきたようにラムダ計算は semantics に関するものであって semiotics とはほぼ無関係といえます。特にソシュール系の記号論とは全く関係ありません。
関係ないものだから言及しない、というのは極めて当然のことではないでしょうか。逆にいえば semantics でなら幾らでもそうした事例が見つけられるのかもしれません。客観的にいってソシュールの記号学とラムダ計算が同種のものであるという認識は極めて異常なのですが、この点に関する考察や論証が全く行なわれないまま議論が進行していきます。
本章で提案する新しい仮説では、直接対象こそはソシュールのシニフィエに対応し、そしてパースの解釈項は、ソシュールの差異、つまり記号を使用することによって生まれる価値を担う、と考える。すなわち、パースの解釈項を記号モデルに外在させることによりソシュールの記号モデルが得られ、二元論・三元論は互換である。(pp.50-51)
正しいことを言ってそうなのですが「記号を使用することによって生まれる価値」が「解釈項」や「差異」のことだと直結しているあたりに大きな綻びがみえます。「記号を使用する」といったときに、それを LG における(内包関係に基づく)簡約のようなものと考えてしまったため、計算機言語と記号論の対応に関しても滅茶苦茶な強弁をしなくてはならなくなっているようです。
またついでにいえば、ラムダ項にも普通の意味でのシニフィアンが無いわけではありません。 Emacs Lisp の例ではそれは式そのものとしてトートロジー的に提示されました。Perl でもラムダ計算は可能です。その際には無名関数ならぬ「無名サブルーチン」を使います。このときのシニフィアンはリファレンスと呼ばれる参照値です。Haskell や Java でも同じような仕組みがあるのではないでしょうか。
計算機言語ではなく LG を出して説明を始めた理由には実際にどのような処理がなされているか、という点からの批判をかわそうという意図もあったのかもしれません。補足:f = λx.x+1 だとか x=3 と言った単なる「代入」でしかない処理をさしてシニフィアンがどうの、と論じているのは(関数定義と同じだと考えられないこともないけど)適切とも思えません。簡約過程と具体的な引数が与えられての計算結果を混同させるように示して「使用」と言っている点も疑問です。
この仮説はプログラム中に現れる識別子を二元論・三元論の観点から捉え直すことにより検証され、二元論・三元論は関数型ならびにオブジェクト指向というプログラミングパラダイムとして表れ、少なくともプログラム上の対応においては、新仮説の正当性が論じられた。(p.51)
「プログラム上の対応」に関して全く納得がいかないことはこれまで述べてきました。二元論と関数型言語については『記号と再帰』がどんな主張をしているかについて考察しましたが、OOP言語が三元論であるという説については未検討です。
どんな考え方なのかここでエミュレートしてみましょう。
鍵となるのは、ラムダ計算での内包関係とよく似たユーザ定義関数同士での包摂関係ではないかと考えられます。プログラミング言語では関数定義の中に別の関数が含まれるということはよくあり、それによって関係性のネットワークのようなものが出来ていきます。
OOP ではこうしたユーザ関数的なもの(=メソッド)のうち、特に関連性が高いものをクラスにまとめているので、そうではない場合にくらべて一段分入れ子構造が深くなっています。この状態を「関数同士の依存関係=使用関係」(?)が「内在」している、と言いたいのではないでしょうか。この「使用」(?)によって「価値=意味」(?)が生じる場所がクラス内部である...クラスを「表意体」に対応させれば三元論であると。
「使用」が記号内部で起こる等々という(そしてそれと等価なのが「全体論的価値」や「差異」「解釈項」だという)摩訶不思議な主張にもこう考えれば一応の辻褄はつけられます。
ソシュールと関数型ではデータ名や関数名はシニフィアンに対応し、データ構造や関数の内容はシニフィエに対応した。また、パースとオブジェクト指向においては、クラスの名前が表意体に対応し、データ構造がパースの直接対象に対応し、それを使う関数が解釈項に対応した。(p.48)
対応関係は滅茶苦茶であるようにみえます。一方では「関数」が「記号」そのものであるのに、他方では同じ「関数」が全く別の何かという位置づけになっているなどの点に納得できません。
私の考えでは対応関係は以下のようになります。
| 二元論 | シニフィアン | シニフィエ | ラング | 価値 | OOP型 | メソッド名 | 機能 | クラス | 戻り値 |
| 三元論 | 表意体 | 対象 | 解釈項 | 意味 |
| 関数型 | 関数名 | 機能 | 関数定義 | 戻り値 |
OOP型のところで「メソッド名」とありますが、Perl においてはメソッドはクラス内サブルーチンであり、このサブルーチンには戻り値があるので関数と同じものです。メソッドの使用にはクラスへの参照値とほぼ同義であるオブジェクトが必要となります。「メソッド名」は「参照値付きクラス内関数名」と言い換えてもよいかもしれません。
また明記はしていませんが「使用」は計算機言語では単にユーザ定義関数を実際に使うことです。自然言語であれば言語活動の中で記号を使うことです。「相互に使用されている状態」の略称という無理矢理なものではなく「使用する」という普通の用法です。
こうした「使用」の結果、自然言語では記号が「意味=価値」を発生します。つまり「意味」には「文脈的意味」しかあり得ないということです。「字義的意味」は存在しません。計算機言語ではこれらは「戻り値」として表れます。
あと、シニフィエにあたるものを計算機言語では「機能」としました。これは「副作用」ともいわれたりします。関数の定義(に関する具体的な叙述)そのものとは別というニュアンスで、関数の使用によって期待される効果を抽象化したようなものです。
関数型では関数定義の中に別のユーザ関数名を含み(前回の prime と sub_prime の関係のように)関係性のネットワークを形成します。これは三元論の解釈項に相当すると考えられます。『記号と再帰』では「使用」と呼ばれている部分です。
OOP型のクラスは二元論のラングに相当し、その内部では関数定義が関数型言語と同じように行なわれます。関数定義の有無ということでは両者は等価に見えるかもしれません。関数同士の包摂関係であることによって「機能」を実現している点では同じなので LG の考察を通して二種類の記号を等価とみなす、という『記号と再帰』の主張に理があるかのようです。
しかし二元記号と三元記号を等価であると認めるわけにはいきません。
関数定義がひとまとめにされているかどうか、つまり「記号」にとって「解釈項」が外在するのか内在するのかは重大な違いです。これが「等価」だと言い切れるのは「記号」がどう機能しているかに実は全く関心がないからだとしか思えません。
記号ごとに関数定義が直接埋め込まれているタイプでは解釈項ネットワークの瞬時切り替えはほぼ不可能です。しかし非埋め込みタイプなら参照先を変更(Perl の例でいえばコンストラクタメソッドを使う箇所でクラス名を変更)するだけで劇的な変化が起こせます。
この性質の違いが記号論に二系統あって両者が相容れないことの原因であると考えられます。
パース系は semantics に近く、決定論的で人工言語と親和性があります。記号について考察する上で「人間」という要素を取り除いたものを扱いたがる傾向があって「動物記号論」などということも言い出したりします。
逆説的な言い方になりますが論理的で分析的な特徴を持つ「人工」言語は「人間」を排除することで成り立ちます。余計な「connotation(言外の意味)」が発生するのを極力制限して「denotation(明示的な意味)」だけによる言語をつくるということです。
計算機言語はもちろんこういうもの(我らが Perl はちょっと違いますが:笑)ですし、その背景にある記号論理学自身も自然言語に極端な使用制限をかけたこの種の人工言語と見なせます。記号論には分類されませんが前期ヴィトゲンシュタインの『論理哲学論考』もこうした意味での人工言語を指向していたと考えてよいでしょう。
英訳版『論理哲学論考』は独語版よりもヴィトゲンシュタインの意を汲んだすばらしい出来だったそうですが、この編集を担当したのはオグデンだったと言われています。オグデンとリチャーズは『意味の意味』の著者でパース系の記号論者としても知られています。彼等は Basic English という英語のサブセットとなる人工言語を考案して普及させようとしました。現在でも VOA で使われている Special English はこの系統のものだとか。
語の意味は語に埋め込まれている(べきである)という論で、所謂「言語学者」に好まれる考え方です。
これに対してソシュール系はラング問題を抱えていることもあって所謂「言語学者」からは無視される傾向にあります。たとえば『Dictionary of Linguistics and Phonetics』の「semiotics」の項目にはソシュールの名前は出てきません(かなり偏った事典ではあるのでアレですけど)。
Particularly in Europe, semiotic (or semiological) analysis has developed as part of an attempt to analyse all aspects of communication as SYSTEM of signals (semiotic systems), such as music, eating, clothes, dance, as well as language. In this area, the French writer Roland Barthes (1915-80) has exercised particular influence.
最後近くにこのような形でソシュール系統の記号論について少しだけ言及していました。ヨーロッパでは言語研究とは別の表象文化研究のような文脈でも使われている、というようなことが書かれていてバルトの名前があがっています。
言語全体にとってのラングにあたるものを、こうしたジャンルの研究では「コード」と呼びます。ラングの全貌をどうにかすることは現時点では不可能に近いのですが、もっと限定されたコードであれば取り扱いは可能です。
研究対象の「使用」について「差異」の状況を調べ上げ、それによってコードがどういうものであるかを推察することができます。このときコードは複数あるのが普通です。
所謂「言語学者」からの評判はよくなくても、こちらが(フランス現代思想などと関係して)広く知られた記号論です。ネット上でも以下の入門サイトがあります。
こっちの記号論を計算機言語で云々...という触れ込みでありながら『記号と再帰』が実際には別物をこれだと偽っていたにすぎなかったことは倫理的に許されるものではないでしょう(補足:私は純朴なので以前ストレートに「学者としての矜持や良心はないのですか?」とこうした人達に尋ねたことがあります。客観的に言い逃れが不能な証拠を突きつけても「正当であると(根拠はいわないが)考えているので(どう考えているかは)答えません」という官僚答弁を繰り返すだけで処置無しでした)。作為的にやったのかどうかはわかりませんが、この種の攻撃によって記号論は傷つけられ続けています。
「記号論は終った」「昔はあんなに盛んだったのにこんなことになるとは想像もつかなかった」というような発言を耳にすることがあります。少なくとも国際記号学会は論文誌編集長自らアレを絶賛・後押しするようでは本当に終っているのかもしれません(Wikipedia の Computational semiotics に紹介されているものの中では最新の研究ということになるんですね)。
しかし別の流れもあります。
先述した論文 "Magnate and Tycoon" のようにコーパス言語学では言語における「記号」の「使用」の「差異」について調査することが可能になってきました。ソシュール系統の記号論とコーパス言語学は互いに補完しあって発達できるもののように思えます。
ただそう上手くも行かないのが世の中です。
コーパス言語学者の中にも所謂「言語学者」は多数入り込んでいます。そして彼等が理解できず、わかりたくもない考え方や手法で研究がなされることを日々妨害し続けています。残念ながら私もそれに引っかかり人生が大きく毀損されました。
もし何かの縁でココをお読みになったココロあるヤングのみなさんはよく気をつけて身を守ってくださいね。オッチャンからのお願いやで。
そんな感じで。
オマケ:チャーチ数における定義と使用と戻り値
ネット検索で Perl Mongers なパイセンたちの解説を拝見しつつやってみました。
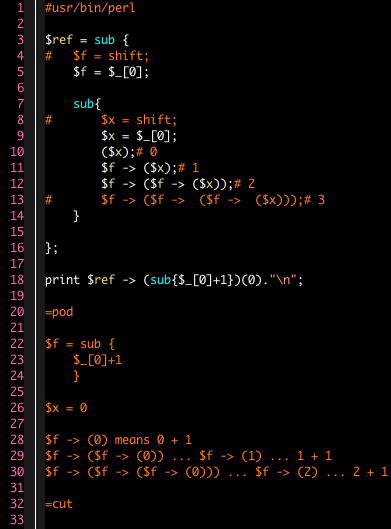
3から16行目までがチャーチ数の「定義=解釈項」です。10から13行目には「0」「1」「2」「3」に相当する式が書いてありますが、この状態では「2」と定義されたことになります。最後の式を評価した値だけが戻り値となるためと「3」の式がコメントアウトしてあるので無視されるからです。
18行目がこの「記号」の「使用」にあたり、$ref に入っている参照値を使って無名サブルーチン(=無名関数)に二つの引数を送っています。最初のカッコ内は外側のサブルーチンへ、あとのは内側のサブルーチンに渡されて $f と $x に代入されるのです。
具体的には $x が 0 に、$f には sub{$_[0]+1} という無名サブルーチンへの参照値が入ります。「変数=無名サブルーチン」という式ではそういう処理がなされるのです。参照値と引数をアロー演算子を介して結びつけると関連付けられた無名サブルーチンにそれが送られます。
あと度々出て来る「$_[0]」という変なのは、この文脈では与えられた引数を意味しています。ですから、$f -> ($x) というのは $f -> (0) ということで、0 という引数を $f に入っている参照値を頼りに $_[0]+1 というサブルーチンに送り、0+1 を計算した結果を戻り値として得てきます。
$f -> ($f -> ($x)) は上の結果から $f -> (1) となって同じく 1+1=2 を戻り値とします。チャーチ数で「2」に相当する「記号」は使用によって初めて「2」という「戻り値=意味」を得たのです。
別の「使用」において、たとえば引数の一つ目を sub{$_[0]+2} とすれば戻り値は「4」になります。「意味」は「使用」によって様々に変わるということです。ただ一定の傾向は「記号」の「構造(関係性ネットワーク)」によって維持され続けます。
戻り値の傾向から構造を推察することが場合によっては可能なように、現象から構造を抽出する研究手法も有り得ます。ソシュールの記号学が構造主義を生んだ、というのはこういう点から言われているのでしょう。
とっぴんぱらりのぷう。
前回の続きです。学界から高い評価を受けている『記号と再帰』が実はデタラメな内容である、というあまりヒトに信じてもらえなさそうなことについて書いています。「アンタの方がデタラメなんでしょ!」と思われちゃう。
本書の謝辞を読むと錚々たる方々がこの論考を是としていることがわかります。東京大学の西垣通先生と影浦峡先生、記号論の国際誌「Semiotica」の編集長である Tronto 大学の Marcel Danesi、情報記号論の第一人者 Loughborough 大学の John H. Connolly 等々...。また著者は『ソシュール 一般言語学講義:コンスタンタンのノート』の訳者でもあります。
これじゃあ誰でもコチラでなくてアチラ陣営を信じますわな(笑?)。
なので、クドクドモタモタ説明していても誰も聞く耳もたんでしょう。一発で簡単に納得してもらう方法を考えないといけません。相手の間違いの核心を誰にでもわかる形でエグってみせなくては。
今話題の『進撃の巨人』でいえば(←にわか)立体機動装置で巨人の背後に回り込んで唯一の弱点である再生不可能の「うなじ」に超硬質ブレードによる斬撃を加えるみたいな。

うむむむ...よしっ!いったるで!
このセンセは関数型言語の「記号」を「識別子」だというた。そして「識別子は、ユーザにより定義され使用される(p.21)」って書いてはる。それでいて関数型言語の「記号」はソシュールの二元的構造の記号に該当するっていうた。
つまりっ、シニフィエとシニフィアンの関係は「定義」やと思ってるいうこっちゃ。
いこーるっ、「シニフィエが概念である」ちゅーことをわかってへん!!文字面ではそういうことも書いてはったけどもっ、ほんまは理解してへん、身についてないんやっ!!そやからソシュールの記号学のショホノショホノ初歩の基本の第一歩から間違っとる!!!いうてることが根本からおかしい!
どやああ! がっつしエグったったわ。会心の一撃やな。え?意味ワカランて?そんなせっしょうな...。

・・・ええと、冗談はさておき、もう少しまともに上記の内容を説明します。ソシュールの二元的記号がもしも「定義」だとするなら以下のようにソシュール型(?)定義集をつくることができます。
人間:人間という概念
犬:犬という概念
階乗:階乗という概念
素数:素数という概念
自動生成スクリプトも簡単に書けますが誰も必要としないでしょう。普通はこういうものを定義とは言いません。同語反復を可能な限り避けて別の語を使って言い換え(置換)をしたものが定義であり解釈です。たとえば以下のように。
人間:理性的動物
犬:ネコ目イヌ科の哺乳類
階乗:nが自然数ときの1からnまでのすべての自然数の積
素数:1およびその数自身のほかの約数を有しない正の整数
上記二つの定義集(?)においてコロンで区切られた右項と左項のセットは一つの「記号」だと考えられます。そしてソシュール型定義集の「記号」はそれだけからは何もわかりません。これに対して非ソシュール型定義集は不完全ではありつつも「記号」だけからわかることがあります。
この状態よりもっとちゃんと「わかる」には「人間」の例でいうと右項にある「理性」「-的」「動物」の定義がまずは必要になります。それらを左項とするときの右項の中にまた定義を必要とするものがあり...とどこまでも(置換が)連鎖していくはずです。
ではソシュール型定義集ではどうすれば「わかる」のでしょうか。
人間:人間という概念...詳細はラングを参照
犬:犬という概念...詳細はラングを参照
階乗:階乗という概念...詳細はラングを参照
素数:素数という概念...詳細はラングを参照
先述した定義集を補足すると、こういうことです。すべて「記号」の外にある「ラング」を参照しろということになります。こういう仕組みであるなら「人間という概念」が何であるかは「記号」そのものをどうこうしても知る術がありません。ラングへのアクセスがすべての鍵です。
関数型言語における「記号」が「ユーザ定義関数」のことである以上、それを二元構造の記号であるとは見なせず、むしろ三元構造と考えるべきだと述べました。ラングにあたるものは全く見当たりません(ちなみに『記号と再帰』では「ラング」について全く言及していません)。
しかし対置されるオブジェクト指向型プログラミング言語(以降「OOP言語」)が全く二元的な要素を持っていないのであれば(そもそも扱う題材としてどうだったのか、ということになりますけど)『記号と再帰』の主張も間違いとはいえないことになります。ですので確認のため、OOP言語での「記号」とはどういうものと考えられるのか以下で検討してみます。(補足:関数型言語とOOP言語の対比ということになっていますが関数型プログラミング言語でもOOPが不可能とは限りません。先方の論考に則ってアレコレするに際してこのあたりも悩ましい感じです...)。
一般的にいってOOP言語の三要素といえば「クラス」「メソッド」「オブジェクト」です。
a data item that has procedures associated with it. See OBJECT-ORIENTED PROGRAMMING.
引用は『Dictionary of Computer Terms』の「OBJECT」から。自身と関連付けられたメソッドが存在するデータ項目のことだとかなんとか書いてあるようです。OOPを参照しろとあるので以下に一部を引用しときます。
Many programming languages let the programmer define new data types such as records, arrays, and linked lists (see DATA STRUCTURES). In object-oriented programming, the programmer can associate a set of procedures (methods) with each type. Types with procedures associated with them are called classes.
普通のプログラミング言語ではレコード(a collection of related data items)や配列や検索可能化されたリストなどというデータタイプを定義できるみたいなことが書いてあります。OOPでは各タイプごとのメソッドのセットを関連付けることができるとかなんとか。ちなみにメソッドはプログラム内プログラムというか単純な処理を担当する小型プログラムのことです。そんで、ひとまとめに関連付けられたメソッドのタイプをクラスと呼ぶみたいです。よくわかりませんが。
簡単な例で試してみましょう。『記号と再帰』に出て来た Java は全く馴染みがないので Perl を使います。
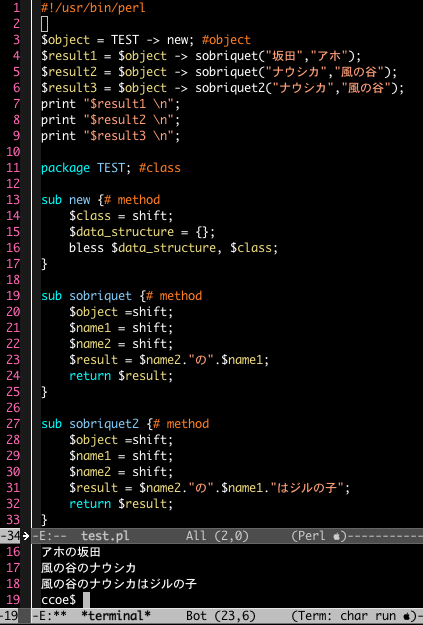
たぶんOOPの条件は満たしていると思われます。エライ人に見つかったら正座させられて小一時間以上説教を受けそうな色々問題のある書き方ですけど(...ていうか *sigh* って感じかな:汗)。
3行目でまずオブジェクトを作成というか関連付けというか、何かそういうことをしています。具体的には TEST という名前のクラス(Perl では package)の new というメソッド(Perl ではサブルーチン)への関連付けです(...と思う)。
この new というのは特殊なメソッドでコンストラクタと呼ばれ、クラスメソッドというタイプに属します。4と5行目はオブジェクトを使って sobriquet というメソッドに引数となる文字列を送っています。こういうメソッドのタイプはインスタンスです。あと、6行目は別メソッド location に対して同様の処理をしています。
これらの文字列データは各メソッドで処理されて結果が返されてきます。結果は各式の左端にある変数に格納されますので7行目でそれを表示します。
このプログラムのメイン部分は以上の7行だけです。実行結果は分割したウィンドウの下に表示しています。9行目以下をまるごと削除して別ファイルにコピーしたあと、このプログラム2行目あたりに use TEST; などを書き足して(そのファイル=「モジュール」へのパスを通して)実行すればそれでも同じことができます。
さて、sobriquet ("ナウシカ", "風の谷") を関数型言語のときと同じく「識別子」であり「記号」と考えた場合、これは二元的/三元的のどちらと見なせるでしょうか。 つまりこの「記号」の値は内在するものと外在するもののどちらによって決定されているのか、ということです。
OOP言語は二元的だと考えられます。
なぜなら「記号」の評価はオブジェクトを介してクラス内のメソッドに送られてそこで決められるからです。このときのクラスはラングに相当します。
メインプログラムの内容に全く変化がなくてもメソッドの処理内容が変わってしまえば、全く違った結果を得ることになります。また、別のクラスに関連づけたオブジェクトを使った場合にも同様のことが起きます。シニフィアン的な部分には何の改変も加えられないのに、です。
『記号と再帰』は(書かれた過程や評価を巡る状況からは信じ難いことですが)根本から間違った議論に基づいていると判断せざるを得ません。少なくとも「シニフィエは概念なので定義(=言い換えに使った記号連鎖そのもの)と見なすことはできない」とか「ラングへのこだわりが(ソシュールの)記号学と(パース系統の)記号論の間に相違を生んでいる」といった初歩的な常識さえ無視しているのは確かです。
なぜこうした状態のまま知の巨人たちの目を潜り抜けて世に出たのか、という点でも十分理解には苦しみますが、それ以上に謎なのが、そもそも一体どうしてこんな内容を著者は書いたのか、ということです。
その鍵はおそらく「再帰(的定義)」へのこだわりにあるのだと私は睨んでいます。チョムスキーの生成文法、記号論理学風言語論、形式意味論等々への多くの人々の執着の理由もこれに関係しているのかもしれません。
まあ、面白いといえばそうかもしれないけど別に...と、私などは感じます。よく出て来る階乗の例 (n-1)!n 以外ではたとえば素数なんかもこうした定義が可能です。
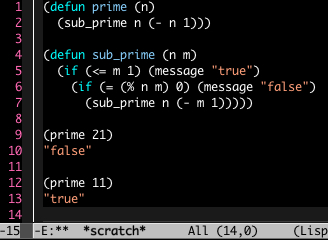
1と2行目で関数 prime を定義しています。4から7は prime が使う sub_prime を再帰的に定義しています。9と12で prime を実行、見ての通り素数判定関数です(Ruby で作られたこちらのプログラムを参考にしました)。
ちなみに Emacs Lisp での実行では問題が発生します。max-lisp-eval-depth の制限にすぐひっかかってしまうのです。これは再帰計算の深さ制限みたいなものと考えられます。初期設定だと話にならないので 1000 にあげても 23 のチェックでリミットに。10000 まであげても 25 でエラー。以前コンピュータ将棋に関して考察したときにも出て来た問題ですが、この手のものは計算量があっという間に膨大になってオーバーフローするのでやっかいです。Emacs のこの仕様に関してはビビリすぎな感じですが(笑?)。補足:上記の prime 関数が再帰的定義を含みつつ、なぜ無限後退していかないのかといえば「境界条件」(それ以上再帰させないための条件)が設定してあるからです。ここでは「m が 1 以下」と「n が m で割り切れる」の二つがそれにあたります。つまり再帰的定義には「計算のための再帰パターン」に加えて「再帰を止めて値を決定する境界条件」も必須なのです。果たして自然言語はこうした要件(特に後者)を満たすのでしょうか?
・・・うーんと、などと書いているうちに(リアルで)頭が痛くなってきたのでざっと結論みたいなことだけ書いておきます。
たぶん変な言い方ですし正しい用語の使い方じゃないですけど「唯物論」なんだと思います、これって。宇宙を全知全能の神が作りたもうた...というのが「唯神論」(?)だとすると、単純な規則みたいなものから勝手に発生した構造体がどんどん複雑で巨大なものになっていく過程で宇宙はできたんだ...みたいな。
『記号と再帰』ではラムダ計算のところで「チャーチ数」に言及していました。何にもないところからラムダ計算(?)だけで自然数やら四則演算やらが可能になっていって...うん、すごいね(棒) (てか、『記号と再帰』の説明読んでもネットで検索しても dankogai のブログを読んでさえ何してんのかサッパリだよ)。
ラムダ計算はこのように単なる置換に基づくにもかかわらず、高い記述力を有しているため、プログラミング言語の理論的研究の基盤として用いられてきた。そればかりか、自然言語についてもその形式的意味論において活用されてきた。自然言語の形式的意味論は古くはラッセルやフレーゲの論理式による記述に遡る。論理式を用いた意味の形式的な記述にラムダ計算の枠組みが取り入れられ、この記述形式がカルナップやクリプキが提唱した可能世界の枠組みと融合し、モンテギュー文法では自然言語の意味を形式化する。(略)このように言語の系の形式化が、プログラミング言語ばかりでなく自然言語ですらもラムダ計算により行なわれることの背景には、言語の本質としての記号の原理がラムダ計算に備わっているからではないだろうか。(pp.63-64『記号と再帰』)
「記号論理学」は頭三文字をとったら確かに「記号論」なので名前は似てますが別物です。Wikipediaで恐縮ですけど a subfield of mathematics と書いてあるように「記号論理学」は数学じゃないかな。「自然言語ですらもラムダ計算により行なわれる」の証左には使えませんよね。
あと形式意味論が本当に自然言語における意味を取り扱えているかどうかについては強い疑念を持ちます。トートロジーを説明できなかったりとか致命的な問題を多数抱えています。ラムダ計算や再帰云々が「言語の本質」だなどと断言してしまえるような根拠はどこにも見出し得ません。
ソシュールの記号学は、シニフィアンとシニフィエの関係が(宗教的正しさに則った?)本質的な規則によって必然的に関連付けられているのではなく単に恣意的に結びついたものにすぎず、それはラングによって規定されていると主張した、というように私は理解しています。
唯一絶対的に正しい(自然科学が見出す法則のような)規則が存在するわけではないので、それを探究することに意味はない、と示した点が画期的であるものの、どうやってラングを人々が共有しつつ言語活動を行なっているのか、が全く説明できないという問題も新たに生じました。ですので、多くの批判が「ラングなんてものが存在し得るのか?」という点に集中したのでしょう。
この点を回避する有力な方法として記号自身にその機能を分担させるというモデルがあった... つまりそれが再帰によるものだったんじゃないでしょうか。このとき記号自身に「定義」や「解釈」機能をある程度持たせ(置換連鎖の各段階で値の処理を局所的に完了・確定して事後的変更も拒否するので)ないと、このモデルは成立し得ません。
それもあって「字義的意味」の存在を否定できない事情がある(ため恫喝や強弁、無視といったアカハラを繰り返して延命保身を図っている人が割といる)ということかと。この系統の言語学者が「言語本能」や(それよりは穏当な)「人間に共通する認知の枠組み」の存在を唱えるのも同様の事情ではないかと推察できそうです。
唯神論も唯物論もどちらも決定論に過ぎず、そんなもので人間の営みの結果である自然言語が扱えるものか、と私などは思ってしまいます。数学の知見を利用するにしても統計学なら非決定論なので人間寄りですけど。
と、だらだら書いているうちに、うーむ、むむむ、頭痛がマックス状態なのでとりまこんな感じで次回につづく...(←ほんとかよ!)
オマケ:整理用メモ
三元的記号
関数名(表意体):関数定義(解釈項):機能(対象)
戻り値(評価)
二元的記号
オブジェクト+メソッド名(シニフィアン):機能(シニフィエ)
クラス(ラング)
戻り値(評価)
そんな感じ。
『記号と再帰』(田中久美子)を読み始めました。
ですが最初の50ページくらいで認容の限界に到達。「関数型言語とオブジェクト指向型言語の捉え方が逆じゃないんですか?」等々、つぎつぎと「ええーっ?」とか「そ、それは...」が湧いてきて精神衛生上「もうむりっ!むりなのよ...」状態です。
>> 著者インタビュー
>> サントリー学芸賞 選評
内容や世間というか学界での評価、この研究の背景にある考え方などは概ね上記引用リンク先を御参照いただけば感じがつかめるのではないかと思います。
だが、記号論にはソシュールとC.S.パースという二人の創始者がおり、バビロンの混乱にある。ソシュールの記号論は、記号を指し示すもの(シニフィアン)と指し示されるもの(シニフィエ)の結合体とみなす「二元論」であり、パースの記号論は、記号とは指し示すもの(表意体)が解釈項を通して指し示されるもの(対象)に至ることであるという「三元論」になっている。
選評の第二段落にはこのように書かれています。微妙に違和を感じる書き方ですが記号学/記号論で扱う記号というのは確かにこういうものです。記号の捉え方をどうしたらよいのか、という点で意見の一致をみていないという状況を指して「混乱」といっているのでしょう。
この「混乱」を整理するために著者は自然言語ではなく人工の記号体系である計算機言語を対象として記号論の知見を使ってみるとどうなるのか、を試みます。
それによって明らかになるのは、「関数型」と「オブジェクト指向型」というプログラミング言語の二つのパラダイムがそれぞれ二元的と三元的な構造をもっており、しかもその対立にも関わらず、形式的には同値だということである。これから田中氏は、ソシュールの二元論とパースの三元論は、記号の二つの表現形態にすぎず、記号論としては同値であるという仮説を導くのである。
選評の続きから引用しました。「関数型」言語は記号の「二元的」な構造の捉え方に対応しており、「オブジェクト指向型」言語は「三元的」構造であるといっています。具体的には前者としてHaskell、後者として Java を例示して論述していました。
計算機言語を通して記号論について考察する、というアイディア自体は色々な可能性を切り開くすばらしいものだと思います。この点では異存はありません。しかし、議論の内容については疑問点だらけと感じました。それと結論にも納得はいきません。
以下、簡単にですがそうした部分について述べてみます。
まず関数型言語について。
残念ながら Haskell については全く馴染みがありませんので、別の関数型言語 Emacs Lisp を使って考えてみます。つまり記号論的に見たときに Emacs Lisp における「記号」の構造が二元的であるのか三元的であるのかを再検討してみようということです。
で、その前段階としてここでもう一つ『記号と再帰』に同意できない点について述べます。それは計算機言語における「記号」とは何か?ということです。この本でそれは「識別子」であるとされています。
識別子は、ユーザにより定義され使用される、それ以外の記号である。識別子は主としてデータと関数を表現する。識別子の名前はユーザが自由に選ぶことができる。(p.21)
句点・読点は変えてあります。「それ以外の記号」の「それ」は「リテラル」「演算子」「予約語」のことです。
本書で主な議論の対象とするのは、この識別子である。他に三種類の記号があることが述べられたが、これらも言語を定義する言語内でやはり識別子として一旦は表現され定義されることが多く、このあたりのいきさつは第11章で論じることとなる。(p.23)
計算機言語において「記号」の役割を議論・考察する際に「識別子」以外の三種類を排除したことは正しい判断だと思います。ですが「識別子」に「データ」を含めてもよいのでしょうか。(もちろん関数もひとつのデータ型ではあるので、厳密な意味でデータを扱わないことはできませんけど。)
Emacs Lisp で具体例を出しつつ話をしてみます。
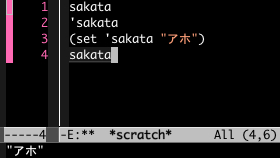
画像の1行目を「評価」するとエラーが出ます。それは sakata という変数が何にも関連付けられていないためです。何かを指し示さなければならないのにその対象が指定されていないことが問題になります。
ですが2行目はエラーになりません。「'」が前につけられると指し示す先のチェックがされなくなるので、そのまま sakata が評価結果として下欄に表示されます。
3行目では変数 sakata が指し示す対象を文字列「アホ」に指定しました。関数 set は予約語です。一般的な計算機言語では set (sakata, "アホ") などと書きます(もっと簡単に sakata = "アホ" とするのが普通かもしれません)。 Lisp ではカッコの内側左端にあるものを関数と解釈します。
4行目は1行目と見た目は同じですが評価結果は「アホ」です。3行目で指示対象がセットされたのでエラーにはなりません。
さて、この事例で出て来たもののうち「記号」的なものとはどれでしょうか。「sakata」がシニフィアンで「アホ」がシニフィエなので二元識別子としての記号だ!...と『記号と再帰』の著者や評価者たちは考えるかもしれません。もしそうなら、それはとてつもなくひどい間違いです。
シニフィエは概念でなくてはなりません。
『講義』が全体として主張していることは、「言語を名称目録と混同してはならない」ということである。この二つを混同したことが、言語の体系性を理解する上で一つの大きな障害になった、とソシュールは理解していた。(p.238 『言語学のランドマーク』(ハリスとテイラー))
「sakata」が「アホ」を指し示す...というのは計算機言語上では単に「名称目録」の項目として機能しているだけであって、これは「記号」とはみなせません。「アホ」が記号として意味を持つのは我々が自然言語の記号としてそれを受け止める次元においてです。(補足:識別子が「記号」だとすると、関数型言語における記号論的な記号の体系とは識別子によって構成される体系です。このとき識別子以外の排除された三種類のものたちは当然記号外の存在と考えなければなりません。下の引用でいうところの「非言語的性質の他の何か」にあたります。これのみを直接指示している変数、たとえば上記の sakata は「アホ」の代用物でしかありません。)
このような混同が、西洋の言語論の伝統において古い歴史をもち、「言語代用説」とも呼ばれている主張の中心にあったのである。言語代用説を唱える人たちの考えでは、言葉というのは代用物であり、非言語的性質の他の何かの「代わりを果たす(指し示す)」ことによって意味をもつ。(p.238)
「言語代用説」と違ってここでは sakata というシンボルが「アホ」という文字列を指し示しているだけで、どちらも記号っぽいものだからいいんじゃないの?と思われるかもしれません。
でも「イヌ」というシニフィアンが(そこらへんで見かける個別の犬じゃなくて)「イヌという概念」をシニフィエとして記号を構成するのだ、というときにまさか「イヌ」が「イヌという概念」という文字列そのものを指し示していると理解する人はいないですよね。
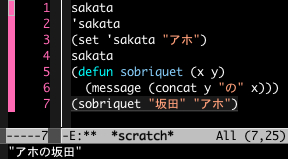
5行目と6行目で予約語 defun を使って sobriquet という関数を作りました。シニフィアン「sobriquet」はシニフィエ「二つの引数を取り、その順序を入れ替えて助詞を挟んでくっつけて下欄に表示するという概念」(?)と結びついています。こうした関数は「記号」的な性質を持っているとみなしてよいでしょう。
これを「評価」すると下欄に「アホの坂田」と表示されました。こうした関数とそれが定義する内容の組み合わせを指して『記号と再帰』では二元(構造を持つ)識別子だとしています。
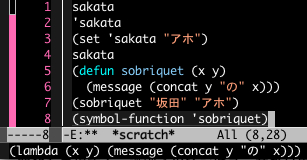
8行目で sobriquet という関数識別子のラムダ式(無名関数)を表示しています。
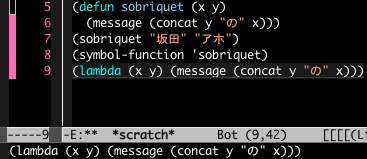
5と6行目の式を評価すると結果は sobriquet という文字表記が返ってきます。しかしラムダ式を評価するとラムダ式そのものが返ってきます。
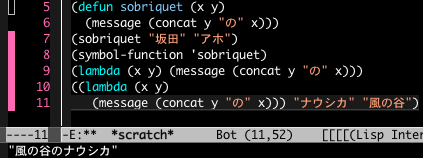
上記のようにラムダ式は sobriquet という関数を表すシニフィアンと同じ働きができます。だから何なんだよ、という感じですが(←!)。
ちょっと話を変えます。
『記号と再帰』ではパースの記号概念を先行研究を踏まえつつ独自の解釈であるとして下記のように述べていました。
パースの考えでは、ある記号の表意体は解釈項を呼び、これは実は別の記号なので、その表意体が解釈項を呼び、その記号の表意体が解釈項を呼び、というように、無限に記号過程が生成される。パース自身は解釈項を記号の「解釈」(interpretation)[80, 8.184]であるとも説明している(p.40)
しかし、広く読まれている一般的な入門書『記号論』(コブリーとジャンス)でも以下のように書かれています。
そのため、解釈項には記号の三項関係のなかで果たすべき重要な役割がある。解釈項を装ってはいるが、記号はさらに進んだ記号/表象の衣裳をまとうこともできる。
これが、さらなる対象への関係性のなかにその記号/表象を置く。その対象はというと、ある解釈項を含み、その解釈項はある記号/表象へと転換し、その記号/表象はさらなる対象への関係性のなかにあり、その対象は別の解釈項をもたらす、といったことが無限に続くのである。(p.25)
パースはどうやら「解釈項」というものの中に「記号」が含まれ、その記号にも解釈項があるのでその中に記号が含まれ...と無限の入れ子構造を持つものが記号なのだと考えていたようです。「表意体」と「対象」の間に無限の解釈項(における記号置換の連鎖)が挟まっていて二項の間は永遠に繋がらない(遅延されていく?)みたいな感じでしょうか。「ゼノンのパラドクス」っぽい話ですが。よくわかりませんけろ。
ところで例示したユーザ定義関数 sobriquet では予約語である「message(下欄に評価結果を表示する)」「concat(文字列をくっつける)」を自身の定義に含んでいました。予約語は「記号=識別子」ではないことになっていますのでこの例は「記号の連鎖」とはいえませんが、同様にしてユーザ関数の定義の中に別のユーザ関数を含んでいく方法でいくらでも複雑な関数を作ることは可能です。
パースは、記号過程は表意体が記号の解釈項を想起し、それが別の解釈項を呼び出すことを繰り返すことによって生成されると考えていた。記号を使用することにより生まれる価値はその記号の解釈項の中に含められており、記号モデルに含まれる。一方、ソシュールにおいては、それがまた別の記号により使われ、それがまた別の記号により使われることを繰り返すことで生成される。そして、記号が使われることで生まれる価値は、記号モデルには入れられておらず、全体論的な系の中の価値として存在する。(p.42)
下線は引用者がつけました。『記号と再帰』からです。
三元識別子では「記号を使用することにより生まれる価値」は記号自身によって決まるとしています。一方、二元識別子では外部の状態だとか、とにかく記号そのものではない何かに依存していることになっています。これが両者の相違点だというのでしょう。
Emacs Lisp での事例においてみてきた識別子(関数)は個別の式、つまり局所において「評価」を実行するだけで「値」(ex. "アホの坂田")を返していました。関数が何をしてどんな(種類の)値を返すのか、については関数自身によってのみ規定されていて外部の基準には依っていません。
関数型言語における「記号」構造は二元的なのではなく三元的なのではないですか?
Lisp の起源は計算機科学内の基準でいえば恐ろしく古く、また人工知能研究に資するために作られたという話もあります。無数のカッコで括られたプログラムが書かれることでも有名です。
このカッコの使われ方によってマトリョーシカのように入れ子構造が作られていっています。入れ子構造は実はツリー構造と同じです。つまり Lisp で書かれた式は(論理的には)ツリー型の階層構造を持つわけです。
そして『記号と再帰』で重要な事項として言及されている「ラムダ式」ですが、ラッセルが「プリンキピア・マテマティカ」で使った x の上にキャレットを付けた記号で用いたのが最初なんだとか。ところがこれだと表記や印刷が不便だとかで形の似たギリシア文字を使って後にΛxと表したと。でもそれだと集合論の「AかつB」の「かつ」の意味の記号と紛らわしいから...となって小文字を使って現在のようなλxとなったんだとか。補足:ネタ元は『Paradigms of Artificial Intelligence Programming: Case Studies in Common Lisp』(Norvig, P.)via『対話による Common Lisp 入門』(栗原正仁)です。
いいかげんつーか、なんつーか。
ま、余談はさておき(←!)要するに(私からみれば:笑)忌まわしき記号論理学風言語論の計算機への実装、というのが関数型言語の正体なのです。もともと所謂「(命題/真理値/形式)意味論」用の計算機言語なのだと理解してよいでしょう。
自然言語に関してこうした考え方を導入してチョムスキーが提唱したのが「生成文法」なのだ、と私は理解しています(『チョムスキー 9.11 Power and Terror』にデカデカとラッセルの肖像写真が飾ってあるチョムスキーの研究室が映っているのでファンなのは間違いないと思われます:笑)。生成文法の考え方との類似点ならすぐにも指摘できそうです。
ということは、もし『記号と再帰』の主張が正しくて、関数型言語の「記号(=関数)」が二元構造なのだとしたら、ソシュールの記号学とチョムスキーの生成文法は同じものだということにならざるを得ません。
そんなバカな話があるのでしょうか?
落ち着くために(?)ここでちょっとラムダ計算と再帰について確認しておきます。
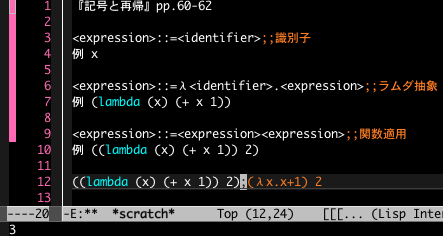
Emacs Lisp で計算するとどうなるのかを示しました。『記号と再帰』では60ページあたりに「ラムダ計算」に関する記述があります。
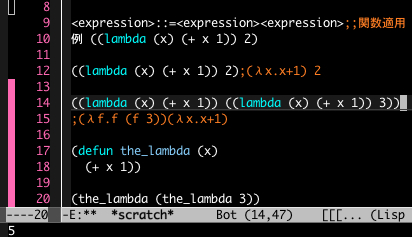
14行目は識別子がラムダ式自身である場合の計算です。下欄はこれの評価結果です。17から20行目ではラムダ式に the_lambda という名前を与えて再帰関係がわかりやすくなるようにしています。評価結果は14行目と20行目では同じになります。
この「ラムダ計算」や「再帰」こそが、関数型言語「記号」の「価値(...というか値、意味)」は「全体論的な系の中の価値として存在する」ことの証拠(?)である、のだとか。
まさかとは思いますが(ゴ、ゴクリ...)ある関数の値が他の関数を引数にしたりして決まるところなんかを指して「全体論的な系の中」だのなんだのが価値をどーのこーのって言いたいわけではないですよね...(滝汗)。
・・・と、ここまで書いたところでどうしても時間切れなのでとりまこのまま更新しときま。
最近機会ある毎にお勧めというか話題にしている本が『トートロジーの意味を構築する』(酒井智宏)です。「トートロジー」そのものには格別興味があるわけではないのですけど(←!)。
ここでいうトートロジーは日常会話で使われる「XはXである」(ex. ネズミを捕らなくても猫は猫である)とその派生形(ex. ネズミを捕らない猫は猫じゃない)のことで、本書は以下の結論に至るまでの長く険しい(?)旅の様相を呈しています。
トートロジーとは、同じ対象に対してXの二度目の命名を行なう言語行為である。この行為の背後にある動機やこの行為がもたらす効果により、さまざまなトートロジーの用法と称されるものが生まれる。(p.341)
結論は上記引用部分にあるように非常にシンプルです。トートロジーが発せられた時点を(二度目なので)T2とし、それ以前をT1とすると以下のようになります。
トートロジーとは、T1においてXと名づけられた対象に、T2において再びXによる命名を行なうことにより、T1における対象aと、T2における同じ対象bのあいだの類似性を主張する文である。(略)同一物であるaとbのあいだに類似性を見出すのは、aとbの側の類似ではなく、aとbを見る側の関心のあり方の持続にほかならない。(pp.260-261)
「類似性ははじめから存在するのではなく、観点に応じてその都度設定される」(p.265)とも書かれています。対象間の類似性は観点や関心のあり方によって生じるものであって、なにか確固たるものが存在するわけではないということが指摘されています。命名者(=発話者)の認識や意識によるのだということかと。
トートロジーとは、言語表現が確定した意味をもたないという事実を前提として成立する言語現象である。表現の意味を定めるのがその表現の使用であるならば、同じものに対してXによる再命名を行なうことは、Xという名前の意味を部分的に仕上げることにつながる。(pp.254-255)
言語表現には文脈から独立した特定かつ固定された意味など存在しない、という考え方に基づいているようです。この前提を受け入れて上記のようにトートロジーを捉えることで(論理学の恒真命題と日常言語のトートロジーを同一視する)従来の考え方ではパラドックスだったものが全て解決されます。
と、いうことは所謂「言語学」が依拠していた所謂「(形式/命題)意味論」は全く棄却されるか、限定的な条件下で(これは間違った考え方なんですが簡単のため...的な)但し書き付きで用いられるほかないはずです。(補足:所謂「意味論」では「日常言語における発話や文は命題である」と考えます。この前提に従えば「XはXである」も命題であり恒真命題と見なさざるを得ません。しかしそれだと矛盾が生じます。これまでこの問題を解決しようという試みが色々と行なわれてきましたが、すべて不首尾に終っていました。こういう経緯のもと上記のように別の前提から妥当な説明が可能であると示されたのですから「文は命題である」という認識によって構築された所謂「意味論」は出発点から間違っていた理論であったと結論できます。)
しかし、この主張に対するリアクションは「間違いを認めて悔い改める」(←?)という理にかなったものではなく、恫喝だったようです。
批判を受けて議論を入念なものにしても、ついには研究テーマを変えても、返ってくるコメントはいつも同じである。鈍感な(あるいは鈍感を装うことが得意な)私はそれになんとか耐えられているが、平均的な感受性をもった若い研究者であれば、こうした恫喝によって精神的に潰されてしまうこともあるだろう。(p.366)
「恫喝」や「批判」は以下のような形態をとるようです。
誰かが研究を発表する。それに対して、「例文の数が少ない」と言うだけで、一つの批判が成立する。このとき、例文の数が少ないことが全体の議論にどのように影響しているかを指摘する必要さえない。そして続けて「問題設定が明確でない」「議論が明確でない」と言うだけで、もう一つの批判が成立する。このとき議論の中身を理解している必要はなく、自分が理解できない(あるいは理解したくない)議論は明瞭でない議論であると決めつければよい。(p.365)
「例文の数が少ない」という批判については他でも聞いたことがあるので定番の難癖なんでしょう。「明瞭でない議論」というレッテル張りに至っては、むしろ批判者の「明瞭でない思考」を明らかにすることの方が多いのではないかとさえ思います。
おそらく「意味は使用によって更新され続けるものだ」という考えに依らないことと「自分の慣れ親しんだ研究(こそが未来永劫真の研究と呼べる唯一のものであり、それ)と異質なものは気に入らないし理解出来ないし理解したくもない」という態度には通底するものがあるんじゃないでしょうか。
私はなんとなくフランス語系の学会ではそういうことはないんじゃないか...と期待していただけに結構ショックです。たぶん若干の程度差はあれ、どこでもこうなのでしょう。ガッカリするというよりは諦観に達していっそ清々しい気さえしてきます。
ところで、展開される議論やその前提となっている考え方に異議はないのですが『トートロジーの意味を構築する』を読んでいてずーっと気になっていたことがありました。
それはたとえば例文の「A woman is a woman.」や「Une femme est une femme.」に対応する日本語が「女性が女性だ」ではなく「女性は女性だ」とされている点です。もちろん「女性は女性だ」の方が自然な例文であることはわかります。(補足:ゴダール映画の邦題は『女は女である』です。)
トートロジーは、二つのXが、繋辞によって結びついた構文である。典型的には「約束は約束だ」のように、「XはXだ」の形をとる。とはいえ、「は」の代わりに「が」「も」が使われたり、様々な表現がある。そこで二つのXが繋辞によって結ばれた構文を、便宜上[X is X]と表す。(p.259 引用:緒方隆文「トートロジー---背景化による強調」2006, p.32)
引用を引用したのでややこしいことになってます。
緒方(2006)では「は」「が」「も」のいずれが使われていても「X is X」とするとしています。日本語での助詞選択における差異は無視するという方針ですが、これに関して『トートロジーの意味...』の著者は特に意見を述べていませんでした。
ちなみに日本語における助詞「は」と「が」の使い分けについて国文法では前者が「係助詞」で「主題や対照」を表し、後者は「主格の格助詞」で「総記や中立叙述」の用法があるなどとされます。日本語教育文法でも「が」は格助詞ですが「は」や「も」は副助詞に分類されるようです。
また、「は」や「も」といった副助詞は、どこに入れても適切な場合が多いので、格助詞の定着をみたいのであれば、「『は』と『も』は使わないこと」といった制限を与えることが必要である。(p.138)
引用は『よくわかる教授法』(小林ミナ)から。「これ(が)兄(に)もらった時計です」と適切な格助詞を選択させるつもりで作成した空所補充問題に「これ(は)兄(も)もらった時計です」等々と解答されてしまった場合、非文ではないので扱いが難しくなるという注意です。
「は」(と「も」)は格助詞と根本的に性質が違っているもの(であるから置き換えも可能)であり、「は」と「が」の区別はこの二者間だけの問題ではないことがわかります。
さて、話を『トートロジーの意味...』に戻します。p.114の9行目「もう十分だろう」に付けられた註36で以下のように書いています。
特に藤田(1990)はフランスのトートロジーにおける冠詞の制約を考察したものである。(略)しかし、冠詞の問題を重視するあまり、冠詞についての考察がないことをもって、本書の価値を部分的に、あるいは全面的に否定するとなると話は別である。実際にそうした立場があることは承知しているが、私としては、冠詞のことを考えなければ動き出さないようなトートロジー論を構築することにこそ問題があると言いたい。理由は単純で、冠詞のない日本語にもトートロジーは存在するからである。(p.390)
「藤田」の後ろは漢数字でしたが算用数字に直しました。この論文は「X ETRE X 構文再考」(最初のEにはアクサンシルコンフレックスがつきます)です。
引用部分最後に「冠詞のない日本語」とありますが、これを読んだとき「!」と思いました。藤田論文は読んでいませんし、たぶん読んでもフランス語が全くわからないのでなんともならないでしょうけれど、「冠詞の制約」ということと日本語での助詞の選択には何か関連があるのかもしれない、という気がしてきました。全くの気のせいかもしれませんけど(←!)。
そういえば「は」と「が」の使い分けには「(情報が)既知/未知」というのもありました。なんとなくこんな感じ(「は」の前が既知で後が未知、「が」の前は未知で後はどっちもアリ、 etc...)というのはわかるような感覚があるのですが実際にその基準を色々な用例に当てはめると混乱して使い物にならなかったような...。
これって文法範疇の「定性 definiteness」に関わるものという捉え方はできないんでしょうか(←質問か!)。
そういえば今手元で見つからないので確認できないのですが『日本語と日本思想』(浅利誠)では助詞「は」の機能について興味深い指摘がなされていました。
すでに三上章の文法論には馴染んでいたが、柄谷の文字についての論考を読んだのをきっかけにして、私の中で、三上章の言う「ハ」の「ピリオド越え」と本居宣長の係り結び研究における「は、も、徒」による係り=結びが相互につながって見えだしたのである。私には、まず、三上と宣長の著しい類縁性の確認がやってきた。その後に、時枝における包摂のテーマと、西田の場所論における包摂のテーマの間にある類似性と差異性について考えることになったのである。この二つがある程度自分の頭の中でつながるようになってから、ようやくにして、私は宣長の「詞と辞」の語学説を時枝の「詞と辞」の言語論と重ねて考えるという方向に向かったのである。
引用はアマゾンの「著者からのコメント」欄から。
三上章先生といえば『象は鼻が長い』が有名です。しかしアマゾンの「商品の説明」にはおそろしい記述が...
>> 
二重主語問題の代表的例文「象は鼻がない」を書名に、「ハ」は 「ガノニヲ」を代行(兼務)するという鮮やかな変形操作と、1,000以上の生き た例文を駆使し、「ハ」の本質を明らかにしたベストセラー。序 佐久間鼎。
「象は鼻がない」て...(あるやん、どうみても...)
ええと、気を取り直します。
「本居宣長の係り結び研究」とありますが「係り結びの法則」を発見したのは本居宣長です...というのはよく知られた事実なのでしょうか(←質問か!)。「ぞ、なむ、や、か」という係助詞が使われるとそれに呼応して文末が連体形になり「こそ」だと已然形になる、と習うやつです。古典文法でも「は」「も」は係助詞に分類されるのですが、これらが使われても文末は連体形や已然形にはなりません。
ところで宣長は「は」「も」および「徒(助詞がない)」の場合でも文末が終止形になるというかたちで係り結びが起きていることを看破していました。本来終止形で終るところが已然形や連体形になるのと違って気づくのが難しい現象だったはずですが、さすがです。
『日本語と日本思想』では、このタイプの係り結びが現代語でも生き延びているのではないか?という説を唱えていたように記憶しています(←疑似記憶だったらゴメンナサイ:汗)。つまり係り結びは無くなったのではなく、むしろしっかりと根を下ろして不可視となっただけだという意見だったような。
日本語には非常に「〜は〜である」という表現が多く、これをそのまま英語などに訳そうとすると不自然な文になってうまくないということがよく起きます。一文単位でもそうですし、それがつらなったテクストとしてもやたらとbe動詞が使われた文ばかり連続することになって不自然とみられるようです。
パラグラフライティングのような文章全体を構造化する作法がなかなか定着しないのも、頻繁に主題を(係り結びによって強調?しつつ)提示しているためじゃないかと思えてきます。もともと文における語の機能分化を順序に頼っている英語と、接続する助詞の種類で区別できるため語順が比較的自由である日本語の特徴がテクスト構成についても反映されているのではないかと推察しますが、これらについては特に根拠も何もないので妄想の域を出ません。
などと暢気に書き散らしている場合ではないので、とりまこんな感じで。
前々回、前回の続きです。樹形図による説明もちゃんと省略しないでやれば問題なさそうなことがわかりました。そのあたりのことと絡めてモンテカルロ法などの話も。
全探索およびミニマックス法の事例を「3マス二目並べ」という超単純化したゲームで図示してみます。先攻が二目並べると勝ちで、後攻はそもそも一目しか置けないので引き分けが最高の結果となります。
>> 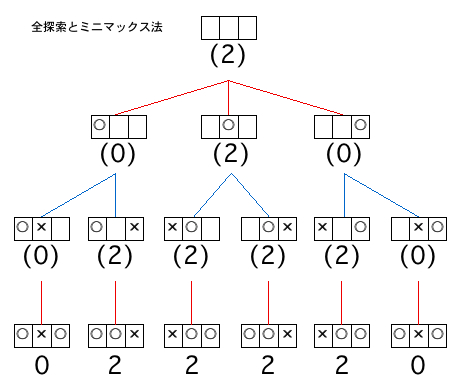
3マスを埋めていくので起こり得る全パターンは3の階乗です。3×2×1 で全6パターン。赤い線で結んだ部分では選択可能な局面のうち最大値がつけられたものを選び、その値が上位局面の値となります。青い線では最小値が選ばれます。
最下段の数値以外にはカッコがついていますが、これは下位局面の値が決定されるまで各局面の評価が決定されないという構造であることを示しています。樹形図で表される構造そのものは決定されていますが、それを構成する各局面パターンがどういう値を持つかは決定されていない、ということです。
「局面をどう評価するか」という部分と「各局面パターンがどういう繋がり方をしているか」という別の層に関する問題の区別を明確にしないで(要するに局面図を省略して)樹形図が描かれると読み手が混乱する説明になってしまうのではないかと。
ちなみに一番上の局面(空のマス)に「勝利=2」という評価値がついているのはこのゲームが「先攻必勝パターンあり」であることを示しています。
「三目並べ(a.k.a. マルバツゲーム)」程度のものであれば、試合終了に至るまでの全パターンを割と簡単に把握できるので確実な評価値(=勝敗値)が得られました。しかし、もっと広大なボードを使う複雑なゲームでは現在使用可能な計算機の能力では試合終了までの全探索は不可能です。
パターンを全部調べ上げるのも、それを元に「ゲーム木 game tree」最下段から遡って各局面に値をつけていくのも、両方無理ということです。もしかすると将来に渡って無理な計算量かもしれません。そこで「どうやって計算量を減らしつつ効果をあげるか」が問題になります。
これは言い換えると「いかにして単独の局面図を正確に評価するか」ということです。ある局面の値を知るためにはそれより下位の値が必要で、その値を知るには更に下位の...という先送りされる連鎖を一番下まで辿らずに適切に評価できるのであれば、計算量を劇的に減らしつつ正確な判断が可能となります。
たぶん囲碁での「モンテカルロ法」や将棋の「評価関数」というのはそうした目的で研究されているのでしょう。モンテカルロ法(っぽいやり方?)で先述した「3マス二目並べ」を図示してみます。
>> 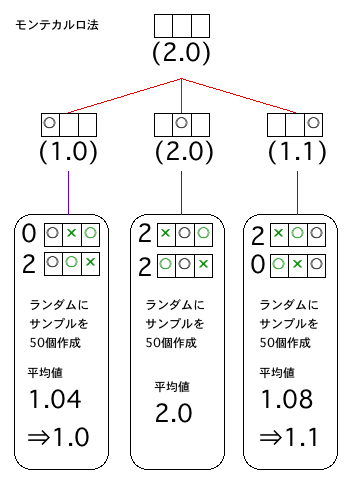
後に続く打ち込みを試合終了までランダムに決定することで初手の各局面パターン値を計算しています。図示した例では二つのパターンしか有り得ないところに無理矢理50個分のサンプルを作成して平均値を出すという若干狂気じみた(?)ことをしているので「完全解析」よりもかえって手間が増えてしまいました(汗)。ここでの数値は再計算すれば一定程度変化していきます。
もう少し複雑な事例、たとえば「三目並べ」で三手目以降にモンテカルロ法を適用すると9の階乗(362880)のうち 9×8×7(504)を除いた6の階乗(720)分の計算が 50 で済みます。つまり処理するパターン数が 504×720=362880 から 504×50=25200 に減少するのです。
どうせやるなら二手目以降でいっとけ!という意見もあるかもしれません。それですと 72×50=3600 なので扱うパターン数はなんと百分の一以下!すばらしい!!
でも問題はないのか?...といえば当然あります。(というか、ちょっとググってみたら、どうやら正式なモンテカルロ法では100万回とか1000万回とかやるみたいです...サンプル...なのか、それ?)
「モンテカルロ法 Monte Carlo method」でも将棋の「評価関数 static board evaluator」でもそうですが、これらによって求められた局面パターンの評価値はあくまでも近似値や推定値であって「完全解析」によって得られた揺るぎない値とは異なります。
そのためミニマックス法を併用して数手先までを処理しておかなければ相手の妨害による影響を全く量ることができません。局面パターン同士の連鎖では理論上選択できても実際には不可能な経路があるため、勝ちルートに乗って選択していたつもりなのに「可能な選択肢が敗北ルートしかない」場面に嵌り込むということも有り得ます。
ええと、以上の話をまとめますと「単独の局面パターンを的確に評価するアルゴリズム(ex. モンテカルロ法、評価関数)」および「できるだけ深く全探索とミニマックス法で局面パターンの階層構造を調べ上げる計算力」の二つが強くなるポイントみたいです。今回の電王戦では前者が十分に正確であったこと、後者がついにプロ棋士の読みを上回る深さに達したことが「コンピュータ将棋」側の活躍に繋がったのかもしれません。
で、私自身は「コンピュータ将棋」とは縁もゆかりも無いので色々考えてみたところでアレ(ぶっちゃけ時間と労力の無駄←!)だったんですが微妙な収穫もありました。それは「樹形図で描かれる決定された階層構造と、その各ノード等々に関する非決定的(で再帰的?)な評価値のあり方」という概念です。(手元にあるのにまだ読んでいない『記号と再帰』ってこのあたりの話と関係あるんですかね?←読めよ!)
自然言語に「試合終了=終り」はありません。起こり得るパターンの「全探索」も不可能です。なので「発話された音声の連続」だとか「書かれた文字の連続」において限定的な範囲で「決定された(階層)構造」は得られますが、これに関する「意味=評価値」はどこまでも先送りされていきます。何らかの方法で一時的に仮の値を決定しても、探索が次の段階へと移って行けばこの値も変化していくはずです。
つまりフレーゲに端を発する記号論理学風の意味論に(ある程度)則ったとしても、やはり彼等が間違っている(=文は命題ではない)ことがこうした事例からも看取できるように感じました。ほんまあいつらまじであほやで。
ま、そんな感じで。
オマケ:ハム将棋との死闘(笑)。
>> 
いつものパターン...(てか、この戦法?しか覚えてない)
>> 
ボロッボロに...(damekoさんよりも攻撃的な気が)
>> 
ハムやん、あんた強敵やったで...
自分で自分に説明できてたら理解するのに3秒かからなかったな。
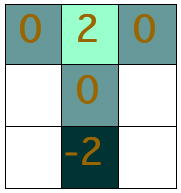
Rスクリプトで前回の「T字型5マス二目並べ」に関してミニマックス法部分を表記するなら以下のように書けます。
result1 <- result;
result2 <- apply(array(result1, c(2,60)),2,min);
result3 <- apply(array(result2, c(3,20)),2,max);
result4 <- apply(array(result3, c(4,5)),2,min);
result5 <- result4;
マス目が埋まるまで交互に打っていくと五回選択をすることになります。初手は五択、二手目は四択、三手目は三択、四手目は二択、最後は一択です。
このうち先攻は五択、三択、一択において自分が望む値を選べます。値は「勝利につながる=2」「引き分け=0」「負け=-2」なので、できるだけ大きな値を選ぶことになります。後攻は四択と二択を行ないますが、このときは自分が勝利するように先攻と逆で小さい値を選びます。
事前に行なった全探索によって試合で起こり得る全120パターンに関する勝敗値(2 or 0 or -2)からなる 1×120 の行列(result)を得ていますので、これを処理していきます。
まず一択では変化の余地がないのでそのままにします(result1)。次に後攻が二択を行なうときは result1 の先頭から2個ずつを取り出して繋ぐ...という作業をして 2×60 の行列を作り、各列の値を比較して小さい方を選択していきます。これによって 1×60 の行列(result2)ができます。
あとは同じ様に先攻が三択から選ぶときは 1×60 を 3×20 に変換して各列から最大値を抜き出して 1×20 行列(result3)を作り...などとやっていきます。この作業順だと一番最後になる五択については人間にそのまま 1×5 行列(result5)を提示しますので処理はしません。
仮に同じことをマルバツゲームでやるのであれば以下のようになります。
result1 <- result;
result2 <- apply(array(result1, c(2,181440)),2,min);
result3 <- apply(array(result2, c(3,60480)),2,max);
result4 <- apply(array(result3, c(4,15120)),2,min);
result5 <- apply(array(result4, c(5,3024)),2,max);
result6 <- apply(array(result5, c(6,504)),2,min);
result7 <- apply(array(result6, c(7,72)),2,max);
result8 <- apply(array(result7, c(8,9)),2,min);
result9 <- result8;
規則性があるので一般化した式が書けそうですけど。
ググってみつけた説明は英語でも日本語でもみんな樹形図を描いていました。たぶん書籍とかで読んでも状況は同じじゃないかと思います。大概の人達はあれでわかるんですね。ちょっと不思議。
樹形図による説明では「選択」を行なっているタイミングがどこなのかがわかりにくく、最大値と最小値のどっちをとればよいのかでひどく混乱しました。ここまでに示した処理スクリプトから顕著に伺える規則性みたいなものもそうした説明の類いからは全く看取できませんでしたし。
樹木に喩えて「枝を刈る」とかいうよりも「評価値が書かれたマージャン牌的なものがズラッと並んでいるのを並び替えて取捨選択していく作業を繰り返す」という物的イメージの方が実際の計算作業とも整合性があってわかりやすいんじゃないでしょうか。樹形図を使った説明や、それに付随する(枝がどーのー、みたいな)メタファー(?)の是非について、一度理解への貢献度の点からきちんと検討すべきではないかと。かとかと。
で、折角ですので(?)マルバツ用のRスクリプトも書きました。
>> ttt.R
計算機の性能によってはけっこう時間がかかるかもしれません。一応動作確認はしているのでバグってはいないと思います。
0 0 0
0 0 0
0 0 0
結果としては上記のように 0 が並んだのが表示されるだけですけど(笑?)。先攻が初手をどこに置いても後攻が最善の受けをした場合には引き分ける...という御神託です。
でもたとえば「array(result7,c(8,9))」とやると以下のような結果も得られます。後攻が二手目に八択を行なう際の 8×9 行列です。最小値を選択するので 1×9 行列は 0 並びとなります。
3 0 3 0 0 3 3 3 3
3 0 3 3 3 3 3 0 3
3 3 3 3 0 0 3 3 3
0 0 0 0 3 0 3 3 3
3 3 3 0 3 0 0 0 0
3 3 3 0 0 3 3 3 3
3 0 3 3 3 3 3 0 3
3 3 3 3 0 0 3 0 3
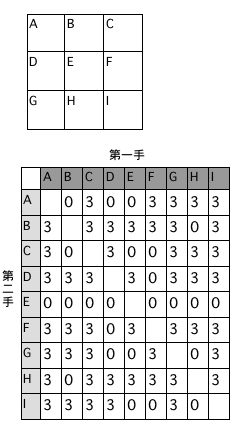
後攻が聡明でなければ初手を四隅に打つと7/8の確率で勝利する(勝率が一番高い初手は四隅だ!)ということを示しています。残りは中央のマスも含めて一律1/2です。なんとなく中央のマスが有利そうとか思ってたのですけろ...。
>> 
計算結果から得られた 8×9 行列を補足して見やすく書き直すと上の図になります。後攻には勝利(-3)に繋がる道は無いけど先攻がどんな手を打っても第二手目に中央マスへ打てば引き分けには持ち込める、ということがわかります。そして初手四隅に対して二手目が中央マス以外だとその時点で詰んでしまうということです。むむむ、そうだったのか。
ついでに「後攻が勝つ可能性」についても調べました。
「array(result6[1:56],c(7,8))」とやると第三手に関する 7×72 行列(result6)から最初の56個分を取り出して 7×8 行列に整形したものが出力されます。初手が左上隅だったときの第二手と三手に関するクロス集計表です。
>> 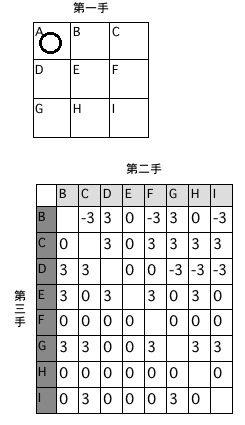
前と同じように図にするとこんな感じ↑になります。二手目は中央マスでなければ必敗ルートですが、それだと三手目に先攻が何を選択しても引き分けルートにしかならないことも判明しました。勝ちを狙うなら後攻は右下隅に打って勝負にでるしかありません。
とはいえ、そうしたところで先攻が上段真ん中や中段左端に三手目を打つとも思えず、無駄な足掻きでしょう(萎)。それよりは相手に「先攻は有利なんだから初手は中央と四隅以外に打つべし」という条件を飲ませた方がいいかもしれません。
>> 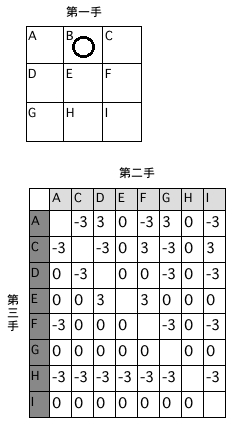
初手上段真ん中に対して後攻が右上隅に打てば先攻の勝ちが無くなることがわかります。しかし、後攻が勝つには先攻が三手目で左上隅か中段左端か下段真ん中に打つという、ランダムでなければありそうにない打ち込みを期待しなくてはなりません。現実的には無理っぽいです。
それよりは危険を承知で左下隅か右下隅に打って四箇所に増やした先攻必敗ルートへ誘った方が...ま、無理かな(笑?)。ちなみに初手が中央であれば二手目がどうあっても「-3」へ繋がる経路は現れません。そういう意味でなら確かに初手中央マスは有利な手と見なせるのかも。
と、ここまで後攻の立場で考えてきましたが、逆に先攻からすれば「わざと初手で中央四隅以外へ打つ→後攻が山気を出して非隣接隅打ち→無慈悲な返り討ち」というのが一番勝率が上がる戦法なのかもしれません。そういえばハスラーってこういう手でカモから荒稼ぎしてたような(参照『ハスラー』『ハスラー2』)。将棋でも「真剣師」と呼ばれる人達なんかが昔はいたようですしおすし。(ググったら1997年にYSSが元真剣師と対戦してたんだとか。YSSってそんな昔からあったんだ...)
そんな感じで。
あと、前回の変な結果がでるスクリプトは差し替えておきますね(汗)。
オマケ:電王戦に触発されてコドモ時代以来の将棋をやりました(笑)。
>> 
「最弱棋士damekoさん」相手になんとか勝ちましたが上記画像以降はグダグダ展開でした。それと「gest」が何語か気になります...。
いろいろたいへん。
現役プロ棋士のかなり上位の方が負けたとかで電王戦が盛り上がって(下がって?)ましたが、一方そのころオイラはなんとなく「ああいうのって、どういう仕組みなんかな?」とか思ったりしてました。別に知らなくてもいいような気がしますが全く知らないというのもなんか気持ち悪かったり。
で、ちょっとググってみて、なんとなーくの雰囲気みたいなもの(の一番初歩っぽいやつ)は掴んだような気がしないでもないです。将棋だとか五目並べだとかオセロみたいなゲームの類いというのは根本のところでは似た仕組みで計算機に手を探させるのだとか。へー。
チェッカーだとかオセロ(6×6盤)はすべての起こり得る試合パターンが解析されてしまっていて無敵のプログラムも作成されているようです。すげ。こういうのは「全探索 full serach」が現在の計算機でも可能になったからできたんですね。量子力学とかが出て来る前の「ラプラスの悪魔」っぽい。
そんで、そのわかっちゃってる結論の知識をもとにして今現在これから指す手をどうきめるのか、については「ミニマックス法 minimax method」とその仲間達みたいのがあるんだとか。ふむふむ。(将棋は全探索できないので局面から評価関数というのを計算しているそうです。この関数を機械学習で作り上げたところに画期的な進歩があったのだとか。囲碁はモンテカルロ法というのでとにかくランダムに打ってプレイアウトさせてから云々...あたまいーひとはいるもんだぬん)
色々読んでてもあんまりピンとこないので手を動かしてみました。
この手のゲームで一番シンプルなのは...というと「マルバツ」なわけですが、これが案外うまくないんです。3×3つまり9マスあるゲーム空間における指し手の全パターンは9の階乗ということになるので 362880 パターン。これは勝負がついても全部のマスを埋めるという想定での数値ですけど。362880 行×9列の行列はイヤーンな大きさなのかどうか。
最新の計算機であればどってことないのかもしれませんが、結構「あー、そういえば目の前のコレって計算する機械やったなあ...」と感慨にふけるというか、Rで計算してすぐ答えが出て来ないのとか初めて経験したっす。
それと、マルバツは最初の一手をどこにおいても引き分けが狙えることは産まれて10年くらい経過した人類なら大抵知っているので、なんというか面白みがないわけです。(大昔の映画『ウォー・ゲーム』で人類を核戦争からアレしたのもコレのアレなところだったりしましたし...)
そんなこんなで「T字型5マスのボードで戦う二目並べ」というのを考案してみました。まあ、聡明な我々人類であればすぐに必勝法が見出せるレベルのものではあるので、なんだかなーですけど。
>> 5masu2moku.R(一応まともな結果が出るスクリプトに差し替えました...20130426)
さっそく上記のようなR用スクリプトを書いてみました。順列パターンを調べるために e1071 というパッケージを使っています。結果はただ数字が5つ出るだけですが、イメージとしては以下のような感じです。全知全能の立場から先攻が初手をどこに打てばよいか教えてくれるはずなのですが...
>> 
えーっと...全探索のパートはちゃんと処理出来ています。でもミニマックス法がどうやったらいいのかよくわからんちん状態。ていうか、分析結果がメチャクチャすぎます(笑?...じゃなくてコレはアカンやつや)。上の両端は先攻でも打っちゃったら引き分けじゃなくて必敗となります。一番下のマスは実際には必勝です。その上のマスも引き分けじゃなくて勝てますね。(二目の並びはタテヨコだけです。ナナメはナシで。)
正しい評価は結局1マスだけ...なんというか、ほんとひどい(涙)。ま、このマスに打つのが確かに最善手ではあるんですけど。
ええと、最初は某巨大掲示板の電王戦スレでどなたかが作って貼ったMATLABスクリプトをもとにMATLAB文R訳(←注:MATLAB用スクリプトをR用に書き換えること)をやりつつアレコレやってみたんですが、もう途中でわけがわからなくなって自己流に改変しつつ行き詰まった感じです。
>> ttt_2ch.m
ちなみに大元のスクリプトはコレ↑です。マルバツゲーム用で、たぶん Octave でも問題なく動くのではないかと。中身のアレコレについては言及しません。自己流でしばらくいじってからじゃないとピンとこないんじゃないかな、っと。
話を悲惨な自作R用スクリプトに戻します(汗)。
問題のミニマックス処理ですが、ぐるぐるループされてるところの数値をできるだけ固定しつつジワジワと理解を試みています。5マスなのでパターンは総数120。初手で5マスの中から一つ選んだときにそこから派生するパターンは24。二手目の4つの選択肢からはそれぞれ6パターンが派生していきます。
プレイヤーは交互に打つので二手目は先攻プレイヤーにとって不利な手が選択されるはず。なので、6行4列の行列から各列においてミニマムな値を選んで1行4列に変換します。次にこの中のマキシマムな値を取り出して初手に選択する各5マスの値として判断に使い...って何か自分で書いていてわからなくなってきました。
機会があったら考えよう...。(アレコレ考えたらわかりました。こちらで言及しています。)
そんな感じで。
TOEFLを色んなところに導入するとかいう話と関連して「そもそも国語力がないのが問題なわけで」みたいな会話がなされているのを目にしました。
仕事上で「文章能力」と言われるもののほとんどは、積み木みたいな論理の作業だと思う。本来、現国ってそういう論理思考と、言いたいことを的確に人に伝える作文作業を教える授業で、作者の意図とか何に感動したのかなんてのは別の時間にすればいい。
上に引用したのはTwitterでの発言です。この後「論じ方」を学ぶことが大切だとか本を読んで「読みどころ」を捕まえる日本語力を身につけさせないといかん云々と会話が続いていました。
国語教育で「作者の意図とか何に感動したのか」みたいなクダラナイことをやっているというのはよくネタになっていますが、実際のところはちょっと違うんじゃないでしょうか。評論文で「書き手がこのように論じているのはどういう意味なのか」を尋ねたり、小説を題材にして「登場人物がこれこれという行動をとったと描かれているが、その含意は何か」を答えさせるものなんかが主だと思われます。
ところで現在のiBTでは勝手が違うのかもしれないんですけど、私がTOEFLの特徴としてまっさきに思いつく典型的な設問って「What does the man imply?」みたいなのだったりします。
>> Listening Comprehension Practice Questions
ナレーターの発言を追っていくとわかりますが「What does the man mean?」とか「What will the woman probably do?」とかとかを答えさせています。「読む」と「聞く」で違った題材に対してですけどこれは「現国」と同種の能力について問うているのじゃありませんか?
新書くらいの分量の日本語を読んで要点を掴むだとか、自分で何かを論じる文章を書くだとかという技量はその前段階であるこうしたことが出来ていなければ当然修得不可能だと思われますので「別の時間にやっとけ」っていうのもちょっと乱暴じゃないかと。(あと、上で引用したETSの日本語版サイトは意外にも結構アレな感じです。「イランのいる受験者」とか。英語サイト指南役にはこの手の「ひどい間違い」は日本人がつくる英語サイトに固有のしょーもなさであるとありましたが、天下のETSでも他言語ではこんな調子なんですね...)
9GAGというお笑いサイトがあるのですが、そのネタでたとえば以下のようなのがあります。
Looks like someone hate the ninjya turtles
とりま英文の意味は「誰かが忍者タートルズを嫌っているみたいだ」くらいでしょうけど和訳できただけでは笑えません(コメント欄で誰かが「Looks like someone *hates* grammar.」って書いてますね...)。「忍者タートルズ」とは何か、それが「誰かに嫌われているらしい」となぜ「歩道に半分埋め込まれてしまったマンホールの蓋画像」から推察できるのか、について知っている必要があります。「カワバンガ!」の意味は知らなくても大丈夫です。
同じような事例ですが、以下のようなものもあります。
>> Yoda I.P.R.
「YODA I.P.R.」と刻まれた墓碑が描かれた画像です。これで笑うためには「YODA」がスター・ウォーズに出て来る「マスター・ヨーダ」のことであり、通常の「R.I.P.(Rest In Peace)」ではなく「I.P.R.」なのはヨーダが劇中で話す英語が不自然なものだったことを揶揄しているとわからなくてはなりません。
ヨーダの英語がダメだ、というのは定番のネタらしいです。
裁判官の「What say you?」という発言を咎めて「The judge can't speak proper English!」と文句をいったら相手はヨーダだった...というオチです。ちなみにタイトルは『Return of the Jedi』にかかっています。
スター・ウォーズ(の古いヤツ)についてならちょっとは知っているのでなんとかなりましたが、オチがわからないのもあったりします。
>> Choose life
上でリンクしたものも一応最後の1コマ以外は理解できているように思えるのですが「Drawer me like one of your French girls!」と叫びながら引き出しの上に座っている意味がわかりません。
唐突に『タイタニック』を見よう、と言っているあたりが鍵かと思って調べてみると(映画をみていないのでなんともいえませんが)「I want you to draw me like one of your French girls」というセリフ(「フランスの女の子みたいに描いて」かな?)があるようです。ということは「draw me」を「drawer me」というダジャレ(?)にしたってことでしょうか。「drawer」には名詞としての用法しかないようですけど。
「draw me like」で画像検索してみると無数の変な画像がヒットします。このセリフが映画の中で使われた状況と異なるコンテクストに投入されて醸し出す面白さというのが多くの人を引きつけてやまないのかもしれません。素直に笑いにくいような凄まじい画像もありますが...。
>> 
>> Google画像検索
ところで劇中でこのセリフが使われたときの「意味」は、現在のように無数のパロディ(?)が作られている状況でも以前と変わっていないと言えるでしょうか。1997年当時の観客と、これから初めてこの映画をみるような人(たとえば私にはその可能性があります)は該当するシーンでこのセリフが発せられたときに違う受け止め方をしそうです。
端的にいえば吹き出すんじゃないかな、と。
世に出た順番でいえば『タイタニック』でのセリフが一番最初にあったわけですが、それから16年もたってしまうとパロディから逆流してくる影響も排除できなくなります。新たなネタ画像をつくる人達の中には元が映画のセリフだってことを知らない人だっているかもしれません。
史実によるとタイタニックの事故は1912年です。このことから映画のセリフにある「French girls」云々はその当時モンパルナスにいた画家たちが描いた女性風に、という意味だと受け取れます。そうなってくると今度は(実在する)彼等による「横たわる裸婦」をテーマにした作品を鑑賞するときにも先述した珍妙な映像群が脳内をよぎることでしょう。つまり突然美術館で笑いの発作に見舞われる危険があるのです。(道立近代美術館はエコール・ド・パリの作品を蒐集しているので札幌在住者などは要注意かもしれません)
こうした相互参照によって起こる意味の関連は「間テクスト性(intertextuality)」と呼ばれたり、それだと用語の使用法が違うとかなんとか文句を言われたりします。んー、でもいいんじゃないかなそれっぽいのはみんな「間テクスト性」で(←テキトーか!)。
文学研究だと(「間テクスト性」と認識するかどうかは別としても)たとえば和歌の解釈を考えるような古典研究でさえ何はともあれ『国歌大観』を参照するなど非常に馴染みがある手法・概念なのですが、他所では案外そうでない向きもあっていろいろ大変だったりします。
とりあえず、そんな感じで。
この日記スクリプトも作ってからもう7年になるんですね...オドロキを隠せません。小学校に入学して卒業しちゃってオツリが来るくらいの期間だもの。「永遠の初心者」であるオイラでさえオブジェクト指向(モドキ)プログラミングっぽいことをはじめてしまうくらい長い時間がすぎたんだなあ...と感慨深い。
そんなこんなで以前公開(?)したデモ版分析ツールを手直ししてみました。日記の方は手直しするくらいなら最初から完全に作り直した方がいいレベルなので放置です。2006年から「暇ですることない(けど生活は超安定していて何の不安もない)から日記ツールでもいじりたおしますかねえ」みたいな日々が来るのを待っているのですが全然気配もないし。こんなはずじゃなかったのになあ...。
>> tptb英語デモ版
JavaScriptとかわかるともっとオシャレで今風にできるんでしょうけど素朴ですんまそん。「Anat.」で生成したファイルをローカル環境にダウンロードしてRに読み込ませれば(英語なので)誰の環境でもそのまま動作するとは思うのですが、さほど確認はとれてません。こういうのって頼んでもなかなかヒトはやってくれないんですよね「ボタン押すだけだから!」とかいっても。あんまりシツコクするのもアレだし。人徳の問題かなあ...。
tptb英語デモ版の右端にアクティブになっていない「Textuality」という項目があります。これに関するツールは一応出来てはいるのですが現在調整中です。具体的に何をするツールなのかは書くのもシンドイのでアレなんですが、この「テクスト性 textuality」とか「テクスト」っていう部分が上で述べた私の窮状の主原因のひとつなんですよね。
昨年もポツポツと愚痴っぽく言及してましたが「テクスト」という概念に全く縁がない言語研究者というのがものすごくたくさんいる、という恐るべき事実に驚愕したり憤慨したり悲嘆に暮れたりして悪戦苦闘していた数年間だった気がします。文系の研究者よりもむしろ工学部とかの人達の方が自然言語処理での談話分析みたいな方面からテクスト論のようなことに取りかかり始めている気配があるので、今後話が通じる期待が持てそうな予感。しかしそれまで研究が続けられるかどうか。
というか、「テクスト」どころか「記号学/記号論」や、そもそも「一般言語学」さえも「知らんがな、なにそれ?」という研究者がむしろ多数派なため、何か主張しようとするとおよそ100年くらい前のレベルから説明を求められるのはホント勘弁して欲しい気がします。通年で講義しろ、というのだったらなんとかできるかもしれませんが「3分で説明しろ!」とか言われても無理でんがなまんがな。
ずーっと昔に「演劇弁当猫ニャー」という劇団の芝居でみた、慈悲深い女王が立派な孤児院を作ると言い出して工事を命令するんだけれども資材としてはレンガ2個(3個だったかも?)しか渡さない、というのを思い出します。頑張ろうが工夫しようが限度があるというか。
フランソワ・レカナティの『ことばの意味とは何か』ですけど、これってそういえば邦訳版は2006年に出てるんですね。最近ググったら英語版がアレな感じでアレだったんですけどアレはいいのかな?(←なにいってるだよ!)
この本が何について書かれたものなのか、というところで私の理解と他人の見解に結構食い違いがあります。たぶんそれは上で書いた「テクスト」「記号学/記号論」「一般言語学」みたいなものに関する理解といいますか、言語現象とはどういうものか、という点についての考え方の相違なのかな、と思えます。
上で(オイラのアフィつきで!)リンクしたアマゾンのページには一件カスタマーレビューがついてますので、それをネタにちょっと語ってみます。
言葉の意味について意味論と語用論の関係から探っている著作。原題は「字義的意味」であり、言葉の文字通りの意味がその言葉使用の文脈とは独立にあるといえるのか?を問題にしている。
semantics vs. pragmatics という内容と捉えているようです。うーん、そうともいえるようないえないような。この場合の「意味論 semantics」は「形式意味論」的なアレですね。フレーゲが源流でラッセルとかカルナップとかDavidsonとかとかの。(余談になりますが『A Dictionary of Linguistics and Phonetics(第三版)』の semiotics(記号論)のところでカルナップがどーのという話をしてるんですけど、どーなんですかね。そういう意見(?)も並行世界のどこかではアリなんでしょうか。)
コンテクストと独立した「文字通りの意味(literal meaning)」などというものが有り得るのか?を問題にしている、という解釈はその通りだと思います。
著者のレカナティはその方面では著名な研究者で、個々の具体的な議論は専門的にも意義のあるものだと思われるが、残念な事に、全体的に内容が十分に整理されて構成されている訳ではあまりないので、この本だけでこの問題を巡る文脈主義(コンテクスト主義)に関する議論を理解するのは難しいと思われる。個々の議論の評価は専門家に任せるとして、次はこの著作の全体の構成を論じたい。
「残念な事に、全体的に内容が十分に整理されて構成されている訳ではあまりない」とあるのですが、この点についてはちょっとひっかかります。このレビューの書き手は本書前半で「字義主義」に関する議論がなされ、後半では「文脈主義(コンテクスト主義)に関する議論」が展開されているが後者は不十分だ、と批判しています。上記引用箇所以降でもこのレビューでは基本的にそういう論調です。
この見立てに従った場合にレカナティの記述がわかりにくく妙なものに思えるのであれば、その見立てが間違いである可能性を考えないのでしょうか。想定した枠に嵌らない部分が大きいのであれば枠自身の正当性をまずは疑うべきだと私は思います。
少し嫌みっぽい言い方になりますし、このレビュワーがそうだというのではなく一般論ですが、自分の能力をやたらと高く見積もっているのかなんなのか唯我論的世界観に浸り切った研究者がこの手の思い込みからくるトンチンカンな批判を何の衒いも罪悪感も責任感もなく展開する姿には辟易させられています。なんちて。
ちなみに私が7年ほど前に読んだ記憶ですと(←ちょっ!読み返せよ!←うるせーそんなひまもよゆうもねーんだよ!)「文脈主義(contextualism)」そのものを直接論じる目的で書かれた本とは思えませんでしたし、当然それについては語られていませんでした。あくまで「字義主義(literalism)」についてのみ議論し、根こそぎ全否定していた内容だったはずです。
ですので「文脈主義に関する議論が不十分だ!」というのは確かにそうでしょうけど、それは見当違いの批判なんじゃないかと。
後半の議論では、文レベルの文脈依存性(サール)と単語レベルの文脈依存性(パトナム)が分けられて論じられていないのは不親切。極端な文脈主義である意味排除論の説明に至っては、この立場が意味を使用場面(源泉状況)の類似性に還元する説明は(文献参照がないけど)許すとしても、その後に出てくるトラヴィス的な対照集合の事例は類似性そのものが文脈によって変化する話だけど、議論としては発話レベルの前半と単語レベルの後半がどう関連しているのかさっぱり分からない。極端な文脈主義ってのは極端な意味の使用説だと思っていたが、レカナティの説明は独特にすぎるように感じた。この著作の他所の具体的な議論がしっかりしてる分、文脈主義に関する一般的な説明が連想的なのは頭を抱えるし、内容も明らかに文脈主義に甘い
細かい内容はすっかり忘れているのでアレなのですが、この本では前半で誰がみても明白な「字義主義」について言及し、それらが成り立たないことを説明してるようには読めました。その点ではレビュワーと同意見です。ですが後半の議論で書かれていたのは、前半で問題にしたような点をなんとかできているかのように振る舞って延命をはかっている「字義主義」についてだったと記憶しています。これは「文脈主義」ではなく「文脈主義」に偽装した「字義主義」に関する議論です。
(論理実証主義者のような)極端な字義主義と(日常言語学派のような)極端な文脈主義を採用する人は今やほとんどいないのだから、それらを先に説明してから中間的なグライスの理論に触れれば分かりやすかったと思う(ただし字義寄りなグライス説はレカナティの批判対象)。また、含意を論じた関連性理論と(記述的)内容を扱った状況意味論との対比ももっと強調した方が読者には親切だと思う(極端な文脈主義は内容と含意をろくに区別しないはずだから…)。
「字義主義」と「文脈主義」には原理的に中間は有り得ないのではないでしょうか。「字義通りの意味は存在する」という考え方から出発して、それでうまく説明できない現象について部分的に「文脈に依存する意味」的な考えを導入したとしても、それは「字義主義」です。
「この世は全知全能の何者かが意図的に作り上げたものだ」という考えから出発して、それで説明がつかない事象について部分的に「それに関しては偶然かもしんない」みたいなことを言ったとしてもそれは「全知全能の何者かが世界をつくりたもうた説」に変わりありません。
「文脈主義」的立場から「ことばの意味」を考えるのであれば「字義的意味」に見えるものも「なんらかの文脈」によってそうなっているとみなせます(cf. "sentences themselves express a determinate content only in the context of a speech act."『Literal Meaning』 )。その「なんらか」が何かという詳細について論じるのは本書での議論とは別の話です。「文脈主義」というのはそれ自体では「ことば」と「意味」の結びつきに関して何も明らかにしません。ただ「字義通りの意味」などというものは存在し得ないのだ、ということを言っているだけです。
・・・などと書いてはみたものの、あとで読み返してみると全然記憶してたのと違ったりするかもしれませんけど、ま、とりあえずそんな感じで。
Copyright(c)2006-2014 ccoe@mac.com All rights reserved.