
![]()
![]()
1226 1213 1205 1127 1125 1123 1119 1113 1013 0927 0924 0903 0817 0730 0721 0710 0612 0603 0522 0511 0505 0429 0423 0419 0411

前にちょっと触れた件について山口二郎先生が12月15日に tweet なさってたようです。
朝日・東大谷口研究室共同調査:第46回総選挙 t.asahi.com/8yq1 結論は極めて当たり前の市民的常識。わざわざ大仰な調査によってエビデンスを探すほどの話か。政治学は凡庸な事実を科学的根拠で語る作業と市民に思われたら困る。
朝日東大調査についての感想続き:民主主義を否定しようとする政治家が国民を扇動しているときに、淡々とデータを集め、政党を適当な座標平面にプロットする作業に没頭する人種を、私は政治学者と呼びたくない。
「結論は極めて当たり前の市民的常識」「凡庸な事実を科学的根拠で語る作業」「政党を適当な座標平面にプロットする作業」というあたりがダメな点ということでしょうか。もっと絞ると「適当に当たり前のことをいってるだけ」ということかな。この場合の「適当に」は「根拠もなく当て推量で」という意味かと思います。
座標平面へのプロット、については「なんとなくカンで」似たような図を作る人もいるのでそれと混同なさったのかもしれません。
因子分析では「軸が何を意味しているか(どんな因子 facter を反映しているか)」という解釈と「アンケートの各設問が妥当かどうか(得点が偏るような問題点はないかどうか)」、つまり出口と入口にやや恣意性が紛れ込む可能性があります。その点で(因子分析を含む林の数量化理論でいうところのIII類は)「半科学」だといわれたりもするのですが、得点行列からその特徴を強く反映した軸を見出して項目をプロットする仕組みは完全に数理的なものです。適切で妥当、という意味では「適当」ですが当て推量ではありません。
次に「凡庸な事実しか提示していないかどうか」ですが少なくとも私にとっては当たり前ではない事実が浮かび上がっているようにみえました。
>> 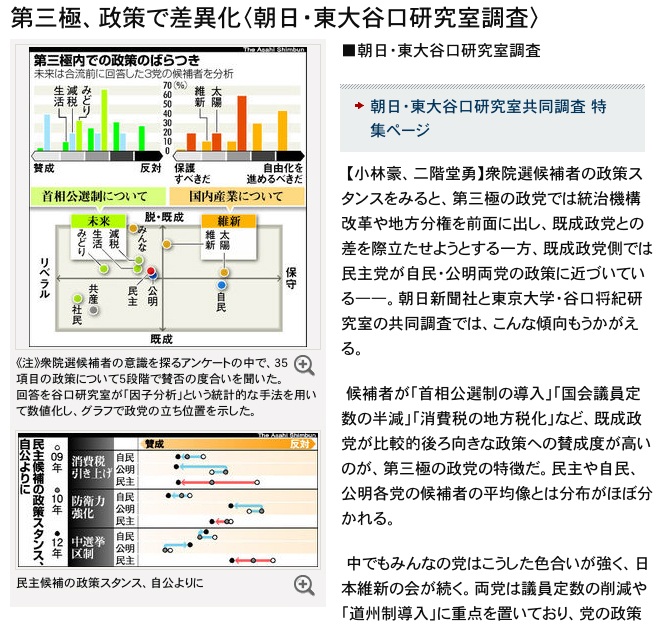
上の画像には政党をプロットした図が載っています。
パッと見てすぐ気づくのは第2象限(左上)に多くの政党が固まっていることです。逆に第4象限(右下)には自民党しかありません。選挙結果では民主党と未来の党が議席を激減させました。一見するとx軸に沿って右の方、つまり「保守」が勝って左の「リベラル」が負けたように考えてしまいますが、必ずしもそうとはいえません。
x 軸でみると未来とさほど変わらない「みんなの党」は議席を延ばしています。第3象限(左下)の2党はどちらも「リベラル」側ということもあり議席を減じましたが、共産党は踏みとどまった感じがあります。原因には色々あるのでしょうが、これは y軸、つまり「脱・既成/既成」という因子も争点になっていたからではないかと思えます。
それなりに多数の人々が「脱・既成」政策を支持し、多くはないが存在している「既成」派が共産党に(投票するという心理的ハードルさえも乗り越えて:笑?)票を集中して彼等を生きながらえさせた、というような分析もできそうです。
引用した図では x軸を「保守/リベラル」、y軸を「脱・既成/既成」としているのですが、私はこれをそれぞれ「national/international」「global/local(経済)」と解釈します。因子分析結果の図からは反global経済を政策とする政党が少ないという傾向が見て取れます。
今回の衆院選を離れて「national/international」「global/local(経済)」という2軸による構図を歴史的な政策の変遷(?)みたいなものにあてはめてみることもできそうです。national で local な政策...といえば「鎖国」ではないかと。江戸幕府による鎖国政策は第4象限(右下)に該当しそうです。
それが明治維新以降 international で global な方向(第2象限)に進んでいきます。ところが、この傾向がどんどん強まって行くと石原莞爾の『最終戦争論』のように「日本国民は天皇を中心とする新たな世界帝国(?)建設のために犠牲となるべきなのだ!」みたいな主張がなされていきます。
現時点からみると「キ○ガイ」としか思えません(←そうでもない、という意見もあるかもしれませんのでアレですが...)が、そこまでいかなくても国内経済が疲弊し国民が困窮しているのにそれを無視して対外投資に驀進していく状況があったのは確かです。
すると当然反動がきます。しかし反動は反globalという形ではなくnationalな方向での極端化(第1象限)へと進みます。大体80年くらい前に起こったのがそういう流れだったんじゃないでしょうか。そして破滅的な戦争へと突入しました。
戦後は冷戦構造のもと基本的には第4象限に収まって自民党政権が続いていたんじゃないかと理解しています。
global と international の間、それと local と national の間は独立ではないような気がします。このことが第2象限から第1象限への流れを生み、大変な事態を引き起こすのではないでしょうか。
例を出してみましょう。たとえばネトウヨさんたちのフジテレビ反韓流デモなどを指して「右傾化」だというのは間違っていないと思います。ですが、そうしたナショナリズム風の主張が起きた背景というか本当の原因は反グローバリゼーションなんじゃないかというのが私の意見です。
テレビ局をグローバル企業と呼ぶのはちょっと変かもしれませんが、現在の在京キー局は地域生産地域消費なローカル経済を指向していないという点ではグローバル企業なんじゃないかと。
グローバル企業は一見 internationalな...多文化共生的な価値観を持っているように見えたりもします。しかしその実体は「誰であっても金を(それなりに)支払ってくれるのが客」「誰であっても労働力を提供してくれるヤツには(できるだけ少なく)金を払う」(ので差額が利益になる)という意味で相手の出自や所属している文化を問題視しないだけであって、認めているわけではありません。
むかし『左とん平のヘイ・ユウ・ブルース』という曲があって、労働者を「すりこぎ」に喩えていました。でも昨今言われるのは「燃料」です。「すりこぎ」なら山椒の木でつくったのがいいとか、まだ色々ありますが「燃料」なら安くて可燃性であれば素材なんてどーでもいーのです。
反韓流デモに対してテレビ局側の関係者と思しきひとが「安くて視聴率がそこそこ稼げてコスパがいいから放送しているだけだろ...なにわけわからんこといってんだ?」みたいに反応していたのを見かけました。つまり韓国の芸能人であれば支払う金額も少なくて良く、韓国製のドラマなどであれば日本製よりも相対的に安価である(できるだけ少なく支払う戦略)が、それで放送枠が埋まればスポンサーからの広告費は以前と同じだけ入るので差額が儲かる、という寸法です。
民間営利企業なんだから儲かるようにするのは当たり前だろ?って主張です。
直接割を喰うのは日本のドラマ制作会社や日本の芸能人でしょうからネトウヨさんが文句をいうのはおかしい!という理屈ももっともです。ですが従来仕事を請け負っていた人達がニューカマーとの価格競争に勝てなければ廃業・失業せざるを得なくなり、また仮に価格競争で生き残ったとしても以前とは比べ物にならないくらい酷い環境での労働となる...という構図はいずれ誰の身にも起こるだろう、という推測はできます。それへの反発が真の原動力なんじゃないでしょうか。
第1象限(national/global)の政策が支持されるようになると危ないというのは簡単にわかると思います。しかし第2象限(international/global)もやはり危ないのです。利益は社会には還元されず、巨大企業間の生存闘争に消費されていくだけなので、社会には不満と怒りがひたすら充満・蓄積されていきます。グローバリゼーションの先に「勝者」となる存在はあまりにも少なく(もしかしたらいないのかもしれません...)人類のほとんどは酷い目にあう側ですから。
グローバル企業は安い労働力を見つけ出しては消費することで利益を蓄え、他のグローバル企業との戦いに備えます。企業間にも下請け/元請け関係がある(つまり労働力の提供側とそうでない側がある)ため階級闘争(?)に負ければ、消滅するか酷い環境で喘ぎながら生きながらえるほかないのです。彼等もまた必死なんですね。
私は読んでませんが『帝国』という本では、グローバリゼーションの先に「平和」がくるようなことが書かれてあったっぽいのですが、読んでないのでなんともいえません。グローバル企業、たとえばマクドナルドが進出した地域同士では戦争が起きないとかなんとか。
大規模な国家間戦争は確かに抑えられるのかもしれません。内戦や地域紛争とテロが頻発しても大戦が起きるよりマシという見方もアリといえばアリかもしれません。でも膨れ上がった怒りや不満は結局過激なナショナリズムを捌け口として求め、やがて制御不能となり国家間の全面戦争が可能になるような政体を招来してしまうんだと思います。
一応「まだ」この悪夢は実現していませんが、このままだと早晩それは起きそうです。
じゃあどうすりゃいいんだよ? となりますが政治学者じゃないのでわかりません。ただ「ネトウヨは愚か!」と罵倒していれば解決する問題じゃないことは確実だと思います。
ローカル環境で消費も雇用も自給自足できる経済システムを構築しつつ、まともな福利厚生(出産・育児に関するアレコレ等々)を充実させ、その中で社会に充満した不満や怒りを解消していこう...などという穏当で現実的な政策(つまりヤマギシ会とかヒッピーとか極端じゃないヤツ)をかかげて実践していくような人物がいればすばらしいのですが、そういう人は政治家や官僚様になりそうにはありません。
じゃあどうにもならんのか!といえばそうでもないかも。
読んでないのでアレですが『東日本大震災と地域産業の復興II』という本などで取材されているような地域産業と地方行政の連携みたいな中に微かに希望はあるのかもしれません。
そんな感じで。
いいかげんシツコイ気もしますが、対数尤度比・相互情報量・PMI 関連の話です。
>> 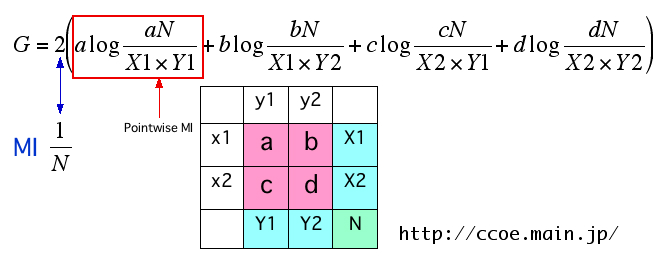
以前考察(?)した結果を一枚の画像にしてみました。よく(文系ちゃんの)世間で相互情報量(MI)と呼んでいるものが実はPMI(Pointwise Mutual Information)で、その正体は対数尤度比(G、G2、log-likelihood ratio)や本物の相互情報量に共通している数式の一部分であることなんかを示しています。
対数尤度比と相互情報量の違いも結局はこの共通する数式部分に 2 をかけるか 1/N をかけるかの差でしかないのですが、そういうこともあまり語られていないような気がしないでもありません。なんでですかね。余計な説明が省けるような気がするのですけど。
で、対数尤度比の算出についてはこの他にも色々とバリエーションがあります。その中で割と(くどいようですが文系ちゃんの)世間でよく使われるのが以下の式です。
G = 2(aloga+blogb+clogc+dlogd-(a+b)log(a+b)-(a+c)log(a+c)-(b+d)log(b+d)-(c+d)log(c+d)+(a+b+c+d)log(a+b+c+d))
これは Adam Kilgarriff がつくったという話を聞きました。どういう意図でやったことなのか(というか、なんでこれが必要なのか?)を確認したかったのですが、それについて書いてある文献にうまく到達できません。聞いた話というか、まあ、読んだ話なんですけど、Kilgarriff2001 を参照せよとのことだったのでググったらヒットはしました。ところが、どうもこの「Comparing corpora」というのはワークショップの予稿らしく、数式についての記述は見当たらないのです。
しかたがないので更に適当にググってみたところ Pouliquen et al. 2006 に以下のような記述がありました。
choice of measure to identify associates in texts, such as pure frequency (TF), frequency normalised by average frequency in the training corpus, TF.IDF, chi-square, loglikelihood. Following Kilgarriff’s (1996) study, we used log-likelihood. We set the pvalue as high as 0.15 so as to produce long associate lists.
残念ながら Kilgarriff1996「Which words are particularly characteristic of a text? A survey of statistical approaches」の PDF ファイルはネット上に存在しないようです。「もう(どうでも)いいか...」とは思いつつ、いくつか目に入ったモノを眺めてみると Kilgarriff2009 というのに対数尤度比などについての見解が出ていました。
The literature starts with Church and Hanks (1989) and other much-cited references include Dunning (1993), Pederson. Proposed statistics include Mutual Information (MI), Log Likelihood and Fisher’s Exact Test, see Chapter X of Manning and Schutze (1999). I have argued elsewhere (Kilgarriff 2005) that the mathematical sophistication of MI, Log Likelihood and Fisher’s Exact Test is of no value to us, since all it serves to do is to disprove a null hypothesis - that language is random - which is patently untrue.
「Schutze」の u は umlaut が必要ですが諸般の事情(?)でアレです。すんまそん。で、どうやら対数尤度比やらなにやらをひとまとめにして全否定してますね...。中身を読まないで書いているので(←読めよ!)アレなんですが、まあ、でもぶっちゃけ確かにそうです。語彙というのはもともとランダムに使用されるものでは絶対にないので帰無仮説が成り立たないのは最初から明らかというかなんというか。
なので、高度な数学じゃなくてシンプルで十分ですよ!ってことが言いたいような気配を感じます。
Sophisticated maths needs a null hypothesis to build on and we have no null hypothesis: perhaps we can meet our needs with simple maths.
よくわからんけどマンセー!...じゃなくてサンセー!といっておきたい。高度か否か、とすると多次元尺度構成法とかどうなんだよ、ということになりそうですがアレは別に null hypothesis には依存してないので問題ありません。
若干入り組んだ(そして飛躍混じりの)話になりますが、null hypothesis を前提にした理論の問題の核心には、フツーというかフラットな状態が存在していて(そしてその状態は割と簡単に把握できて)それとの比較において個別の「特徴」というものが見出せるという考え方があるのだと思います。物事の意味や価値というのが規準との比較で「しか」決まらないという考えだともいえます。いつも世間の動向や他人の顔色をみて自分の意見を決めるようなそういう腐った人格が自然と選択する考え方だといったら言い過ぎですかね。言い過ぎですね、すんまそん。
でも、この邪悪で愚かで虚無的な考え方(←だから言い過ぎやろ...)が割と根強く蔓延っていることには難儀します。冒頭に示した対数尤度比なんかの式を載せた画像ファイルでの N にあたる数値を使わない指標、たとえば Dice係数なんかの方がそれなりに使い勝手が良かったりするのはやはりこの考え方が間違っているからなんじゃないのか、と思えてならないのですがどうなんでしょうね。
ええと、話は微妙に戻ってひとつ前の引用にでてきた Kilgarriff2005 ですが「Language is never, ever, ever, random」とかいう人柄が伺い知れるようなタイトルです。中身は読んでませんが(←オイ!)。
今更に新しい何かに取り組む余裕は全くないのですが、日本語における基本動詞みたいなことを調べた関係でちょっとメモっておきます。
>> 語彙概念構造辞書
日本語における語彙概念構造については影山1996『動詞意味論』が始祖らしいです。「語彙意味論」という用語もまた「意味論」のアレさ加減のせいでややこしいことになりそうではあります。
とりあえず、そんな感じで。
普通の因子分析に対して激しい罵倒が行なわれていて驚愕しています。ヒトゴトながらちょっと心臓パクパクいってる。
>> 
第三極、政策で差異化〈朝日・東大谷口研究室調査〉 t.asahi.com/8yop こんなものを見せられると、政治学者というのは塗り絵が趣味のおバカな連中と思われかねない。尺度のあいまいさ、位置づけの恣意性など、およそ学問とは言えないお遊戯である。
Twitter で見かけたこの発言。「ふーん、そんなひどいんかい...」と思ってリンク先をたどったら別に何もおかしくないように見えるのでしばし考え込んでしまいました。今これを書きながらまた読んでいるのですが(少なくとも記事からわかる範囲では)やはり別にどこもおかしくないとしか思えません。何がそんなに問題なのか。
「塗り絵が趣味のおバカ」「尺度のあいまいさ、位置づけの恣意性など、およそ学問とは言えないお遊戯」とまで罵ってるんですけど、そこまでいう根拠ってなんなのでしょう。記事だけからだと具体的にどういう質問票を使ったのかはわかりません(←35項目の質問内容および各候補の回答は「第46回総選挙」ページで確認できました。このデータを使った因子分析の検証も手間はかかりそうですが可能です。自分が投票する選挙区の候補についてアレコレやってみるのもよいかもしれません。ていうか、なんでこの仕事がバカだのなんだの言われるのか全く理解出来ません。なんで?)が、叙述されてる分析内容からは特に異常なものが使われた形跡も見出せません。
分析手法についてリンク先ではこう書いてます。
>>
《注》衆院選候補者の意識を探るアンケートの中で、35項目の政策について5段階で賛否の度合いを聞いた。回答を谷口研究室が「因子分析」という統計的な手法を用いて数値化し、グラフで政党の立ち位置を示した。
「ごく普通の、どこにでもある、誰もがやっている」アンケートをもとにした因子分析に見えます。上で引用した tweet の発言者が独自に同様の調査を行なった結果や、実はこの記事のもととなったデータを入手していて同様の(あるいは別の統計手法等々で)分析をした結果だとかが朝日新聞の記事と著しく違っていたので偏向や捏造に怒っているというわけでもなさそうです。
僭越ながら申し上げれば、これは単に「統計なんてものはよー学問じゃねーよー」とか「多変量解析なんてーのはよー塗り絵なんだよー」「線形代数なんて恣意的プゲラウヒョー」と難癖をつけてるだけにしか見えません。「量的研究なんてーのはお遊戯だろハズカシー」とおっしゃってるんだと思います。
うーん...「政治学」というのはそういうものなんでしょうか。著名な政治学者がそういうのならそうかもしれません。しかし「およそ学問とはいえないお遊戯」呼ばわりが、因子分析の利用に際して不手際があったという指摘ではなく、統計手法を使ったこと自体への批難ならば、この発言は妥当とはいえません。また前者であるなら相応の論拠を具体的に述べる義務があると思います。
幾人か同調する発言者も目にしますが、訓練をうけていない知性が統計手法への無知から発する(素直な?)感想の域を出ないものばかりです。そういう人々が存在し、そういう発言をすることはある程度は仕方がありません。
しかし、この tweet は素人ではなく山口二郎先生の発言です。朝日新聞社は統計手法を用いる研究者全般の名誉の問題もありますので、この件については曖昧にせずキッチリと公の場でケリをつけなければなりません。ま、今はそれどころじゃないんでしょうけど。
追記:一応現段階では留保をつけておきますが「量的研究は学問とはいえない」という(無根拠で誤った)信念を持つ教員は、量的手法を使おうとする学生に対してアカデミックハラスメントを行なう可能性が(私の経験からいっても←!)非常に高いと推察できます。この点も心配です。
なんか似てるんだよなあ...と思ってたのですが、実はほとんど同じものだったんですね。ビックリしたのでメモっときます。
| y1 | y2 | ||
| x1 | 10 | 190 | 200 |
| x2 | 90 | 710 | 800 |
| 100 | 900 | 1000 |
抽象的な話だとワケワカラン状態になるので具体的な数値の入った表を作りました。まず、こいつで正式な方の相互情報量を計算します。
I (X; Y)
= (10/1000)*log((10*1000)/(200*100))
+(190/1000)*log((190*1000)/(200*900))
+(90/1000)*log((90*1000)/(800*100))
+(710/1000)*log((710*1000)/(800*900))
= 0.004011542
MI = 0.004011542 と計算できました。上の計算では対数の底を e にしています。もし 2 を使えば 0.005787431 になります。なんで 2 じゃないのかといいますと対数尤度比の計算では底が e の対数を使ってたからです。
対数尤度比は以前使ったスクリプトで計算します。Rに読み込んでから G.ccoe を実行すると...
>> Dunning's loglikelihood ratio test and G-test
> G.ccoe(10,190,90,710)
G = 8.023083 p-value = 0.004618488 (G-test)
当たり前ですが MI と G の数値は異なります。しかしですよ...
N =1000
MI = 0.004011542
G = 8.023083
MI*(2*N) = 8.023083
G/(2*N) = 0.004011542
おおおおおっ!!
上でリンクしておいたR用の log-likelihood ratio 計算スクリプトに Mutual Information 計算機能も付加しておきました。それを使って以前対数尤度比について色々計算したところのネタ(『Foundations of Statistical Natural Language Processing』や「Dunning1993」)で MI との一致具合を確認しておきます。
> MI.ccoe(150,12443,782,14294293)
MI = 4.512682e-05 PMI = 5.208712
> 2*sum(150,12443,782,14294293)*MI
[1] 1291.319
> G.ccoe(150,12443,782,14294293)
G = 1291.319 p-value = 0
MI = 0.004259714 PMI = 1.824183
> 2*sum(110,2442,111,29114)*MI
[1] 270.7219
> G.ccoe(110,2442,111,29114)
G = 270.7219 p-value = 0
MI = 0.004152321 PMI = 4.972244
> 2*sum(29,13,123,31612)*MI
[1] 263.8966
> G.ccoe(29,13,123,31612)
G = 263.8966 p-value = 0
ふたつめ以降は MI.ccoe 部分を省略しました。やはり G と一致するようです。と、いうことは対数尤度比も情報理論から説明が可能ということなんでしょうか。興味深くはあるのですが状況が状況だけに深入りはやめておきます。
それと PMI なんですけど、今回最初に使った表でいうと左上隅のマスについてだけ p(x, y) の self-information を計算した(つまり期待値を求めているのではないから重み付けの p(x, y)を掛けてもいない)ってことなんですかね。「x1 = milk, x2 = milk以外, y1 = tea, y2 = tea以外」としたときに milk tea の self-information だけを計算して他を無視した数値ってことなのかな。
一方正式な MI は 2×2 のマス全部について重み付けをしていて、その総和=期待値を求めているのだと思われます。
そんなこんなで MI は結局カイ2乗分布の一種であるらしいとわかった(←言い切っていいのか...:汗)わけですが、それにしても PMI っていったいなんなんでしょうね(改めて確認すると PMI は p(x, y) つまり「x かつ y の確率」の self-information です。そして p(x)*p(y) によって予測される値...これも期待値と呼んできたのでやや混乱しますが...と p(x, y) という実測値が一致すると 0 、すなわち entropy が消滅=不確定性がなくなる、という測度です。確かにそれで適切なのですが、数理感覚に難のある私にはここがなんともいえず不思議。なんでこんなにうまいこといくのか。そして MI は PMI 集合から算出した entropy の平均値なんですが、PMI 計算の段階で出て来るマイナスの entropy って何を意味していると考えたらいいんですかね、アレは:笑?)。どういう確率分布をしているのかもよくわかりませんし。3 くらいが臨界値っぽいという話も聞くのですけど。
いずれにせよ存在意義がよくわからなくなりました。計算で手抜きができるという以外なんの取り柄もないような...。昔ならともかく現代の計算環境だとそれは取り柄ともいえませんしね。むう。
ま、MI も実質 log-likelihood ratio と同じってことは、こちらも特に存在意義があるともいえない気が...。
なんかバカバカしくてテンションが落ちてきたような...。
あ、でもこういうのは(ディレッタントどもの衒学オモチャとしてじゃない本物の!)「構造主義」っぽくてなんとなく好きです。もともと別の考え方から案出されたものなんだけど、よくみると数理的に似た構造を持っていることがわかったことから認識の枠組みが広がって行く感じみたいな。
対数尤度比と相互情報量の式を比較してみます。
以前対数尤度比とカイ2乗検定の比較をしたところで言及しましたが...
2×(((log(実測値)-log(期待値))×実測値)の総和)
こんな式が『英語コーパスと言語教育』で紹介されていたと書きました。これをもとに以下の表に当てはめた場合のG値式を書きます。
| y1 | y2 | ||
| x1 | a | b | X1 |
| x2 | c | d | X2 |
| Y1 | Y2 | N |
上段に G 値、下段に MI 値のものを書きました。
>> 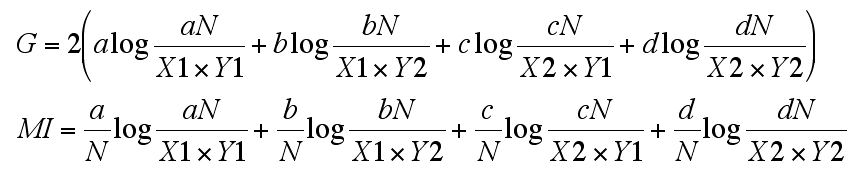
「Gの方ちょっとちがってんじゃねーか!」と言われそうですが、まず対数の引き算は割り算なのでそこは問題ないはずです。(実測値)÷(期待値) 部分ですが、これについてはたとえば a の期待値 ae は X1 に Y1/N をかけることで求められる(もちろん Y1 に X1/N をかけても同じ結果です)というような話は以前していたように記憶しています。そうすると a/ae は a/(X1*(Y1/N)) = aN/(X1*Y1) となるので b、c、d も同様です。
ふたつの式を見比べると G = 2*N*MI は誰の目にも明白かと。ふむふむ。前に wikipedia 読んだときはこんなこと全然理解できてなかったけどなー、しっかし理解した(と錯覚した:笑?)後だと逆になんでわかんなかったのか不思議で仕方が無くなるのは何故なのか。で、調子に乗って説明不足のアレを書いて無駄な敵意に晒されるっと。自重しよう(真剣)。
とりいそぎ、そんな感じで。
こんなことやってる場合じゃ...と書いたそばからアレですが前回の補足です。私に数学的素養が著しく不足しているため「あー、ほうほう、えー、むぐぐ」とジタバタしてますが、わかってる人には「あのね、あのドアってね、引くんじゃなくて押すんだったんだよ!」的なシラケるネタなんだろうな...などと思うと切ない(←笑?)。
えーと、まずは self-information のあたりから。なんであんな式が与えられているのか、を考えました。
>> 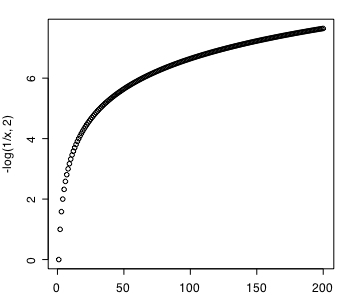
上の図は I(x) = -logP(x) を P(x) = 1/x として x=1,2,3...,200 まで変化させてプロットした結果です。対数の底は2としているので x が2の累乗のとき自然数になります。
全体傾向として self-information は確率が小さくなるに従って大きな値をとることが読み取れます。そして P(x=1)=1 すなわち絶対確実なときの値は 0 です。不確実さの度合いを表す測度として良好に機能するよう考えられているのがわかります。
次に entropy ですが、以下のような式が与えられていました。
>> 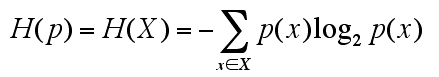
これが「the average uncertainty」を表しているとしています。不確実さの平均値...ですが、ここは「期待値 expectation value」と考えます、大して違いはないんですけど。
で、重み付けされた期待値は通常 E(X) = sum(x*P(x)) みたいな式で表します。たとえば受験者3名の試験で100点が1名、40点が2名だとその期待値(平均点)は 100*(1/3) + 40*(1/3) + 40*(1/3) = 60点となります。(100+40+40)/3 = 60点と結果は同じですけどね。
前回参照した引用部分よりもクドクド書くと、 entropy は「確率変数Xのとる{x1,x2,x3...,xn}についての self-information 集合の期待値」なんじゃないかと思われます。
パッと見た感じで確かにそれっぽいんですが、ちょっと注意というか確認が必要な気もします。結論から先にいうと sum(x*P(x)) の x にあたるのが -log(p(x)) で P(x) にあたるのが p(x) ってとこです。表記上は逆の順番で書かれていますから一瞬「?」と思ったり勘違いしてわけわからなくなる人もいるんじゃないでしょうか。
>> 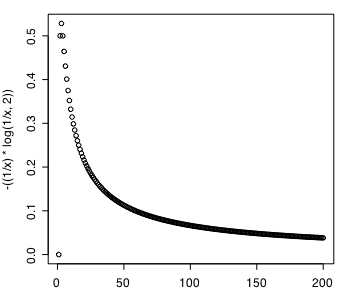
あまり意味がないかもしれませんが -p(x)log(p(x)) についても self-information と同じようにプロットしてみました。図での x とこの式での x は意味が違っているので混乱するかもしれません。すんません。
p(x)=1 のとき 0 なのは self-information と同様ですが、一瞬高まってあとは減少していっています。あまりにも可能性が低いモノは entropy の増減に影響しないってことでしょうか。
前回言及したジャンケンの事例は entropy が最大になる場合と最小になる場合だけを扱いました。ここではその中間の場合について考えてみます。
グー、パーにくらべてチョキというのはちょっと形が複雑なせいで出しにくく、出現頻度が低いという説があります。この説が正しいと仮定してグーとパーが35%、チョキは30%の確率に設定してみます。このときの計算は以下の通りです。
H(X) = -sum(p(x)log(p(x))
= - (2*(0.35*log(0.35))+(0.30*log(0.30)))
= 1.581291
テストの例で出した100点とか40点にあたるのがグー、チョキ、パーそれぞれの self-information 値で、1.581291 は平均点=期待値の60点が相当します。グーとパーは計算結果が同じなのでまとめました。
このときの entropy は完全にランダム(すべての確率が等しく1/3)な場合の 1.584963 より少ない値です。つまり「チョキがちょっとだけ出しにくい」とわかったことでジャンケンにおける「情報量= entropy =不確定性」が減少したのだと考えられます。
前回は「ベン図を想起してください」の一言で説明を省略しましたが、ここではもうちょっとだけ詳しく書いておきます。
>> 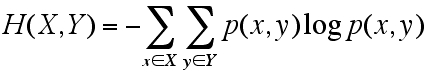
結合エントロピー H(X, Y) ですが、H(X) において p(x) を使う部分が p(x, y) に置き換わった形ともいえます。確率変数 Y の y {y1,y2,y3...,yn}も扱う必要から sum_x sum_y と記号が二重和になりました。
これまで見て来たように p(x) は「x {x1,x2,x3...,xn} の確率」です。これに対して p(x, y) は何を意味するかというと「x かつ y の確率」です。
また p(x) はそのままでは y を考慮していませんが、たとえば sum_y ( p(x, y)) とすることで p(x, y) を使った表し方に書き換えられます。同じように p(y) も sum_x (p(x, y)) になります。
さて、今確認した事柄を踏まえれば前回言及しつつザックリ割愛した「相互情報量(ホンモノ:笑)」計算式に至るまでの説明がなんとか可能かと思われます。以下、二重和 sum_x sum_y は省略して sum_xy と書きます。
>> 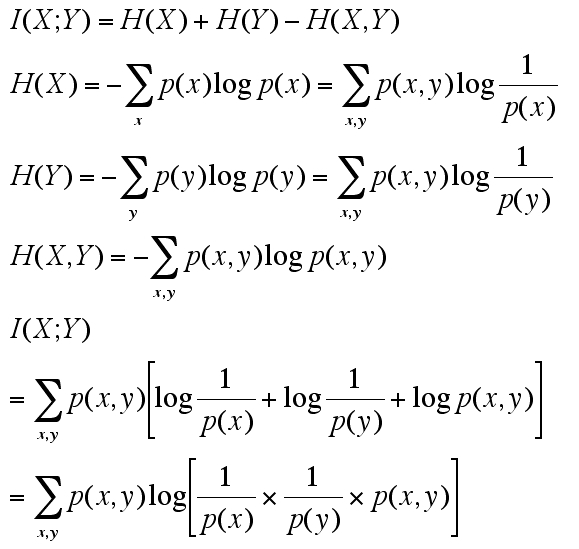
一行目が相互情報量を entropy で表したもの。二行目から四行目で各 entropy を summation 記号を使って表しています。二行目と三行目の最後が分数になっているのはあとの計算の都合です。
sum記号は x,y を扱う二重和で共通しています。中の式も p(x, y)までが共通です。更に I (X; Y) = H(X) + H(Y) + (- H (X, Y)) と考えて正負もそろえて全体を足しています。対数の足し算は掛け算で表せることから前回提示した式に至りました。
>> 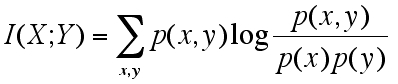
ふう。ところで相互情報量にはもう一つありましたね。バッタモンの PMI というのが。次項で条件付きエントロピーの話なんかもするついでに扱います。
H(X, Y) なんですが実は以下のようにも表せます。
H(X, Y) = H(X) + H(Y | X)
H(X, Y) = H(Y) + H(X | Y)
H(Y | X) は「X のもとでの Y の条件付きエントロピー」といいます。X のせいで(おかげで?)いくぶん H(Y) の entropy が削り取られた状態を表現している...と私は理解します。H(X | Y) も同じように Y によって H(X) の entropy が減った姿です。ふたつの式の左辺はどちらも H(X, Y) なので以下のようになります。
H(X) + H(Y | X) = H(Y) + H(X | Y)
H(X) - H(X | Y) = H(Y) - H(Y | X) = I (X; Y)
削られる前と後との entropy 量差は X についても Y についても同じになります。 このように互いに相手から減少させた(対称の) entropy 量が「相互情報量」です。
最後に self-information での相互情報量を求めてみます。x と y について y によって I (x) が損なわれた(entropy が減少した)状態のものを I (x | y) とします。
>> 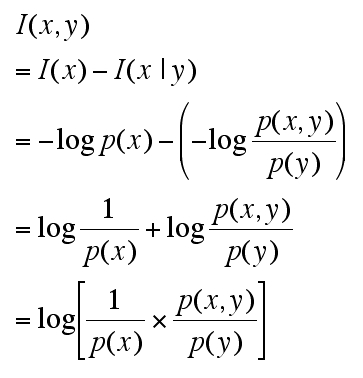
p(x | y) つまり「y という条件つき x の確率」は p(x, y)/p(y) すなわち「y という条件での x かつ y の確率」と考えるようです。self-information についての相互情報量は以下の式に帰結しました。
>> 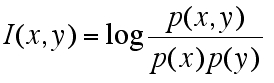
なんと「PMI (pointwise mutual imformation)」は self-information についての相互情報量だったんですね。なるほど確かに「two random variables」(集合)ではなく「two particular points in those(=two random variables) distributions」(スカラー値)を扱っているという説明が腑に落ちます。
>> 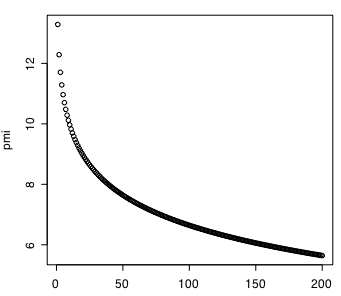
オマケ(?)として総 token 数が10000のコーパスにおいて常に共起する2語の token 数を1から200まで変化させた場合の PMI 値をプロットしてみました。確かにマズい(というか注意が必要な)性質があることがよくわかります。
とりあえず、そんな感じで。
この間つくった簡易 Tag Cloud で使った MI 等々について考えたことなんかを備忘用にメモしときます。あとでまた知識が必要になったときには絶対きれいに忘れているでしょうから。
ええと、以前 log-likelihood ratio に関する話で使用した2×2のクロス集計表を再利用します。
| w2 | w2以外 | ||
| w1 | c12 | c1-c12 | c1 |
| w1以外 | c2-c12 | N-c2-c1+c12 | N-c1 |
| c2 | N-c2 | N |
この表についてのMI(mutual information)scoreは、色んな人が解説していることを参照すると以下のような感じで計算できます。
MI = log((c12*N)/(c1*c2))
このとき使う対数は底が2のものなんだとか。ふむふむ。c12は共起数でNはコーパスに含まれる総word token数でしたね。c1とc2はコーパスに含まれるw1とw2それぞれのword token数です。
分子はc12とNの積で分母はc1とc2の積のようですが、この式が具体的に何を表しているのかはよくわかりません。どうやらこの部分は以下のように考えて立式したものが元々の形のようです。
分子:対象コーパスでの共起発生率実測値→c12/N
分母:対象コーパスでの共起発生率期待値→(c1/N)*(c2/N)
分母の方は例によって「(w1とw2の)共起は偶然である」という帰無仮説が正しい場合の値ですので、この式は「帰無仮説が正しい場合の理論値」と「実際の値」との比を表していると考えられます。
実測値が期待値と一致すると分子と分母が同じなのでこの部分の値は1です。1の対数は0ですから、MIは共起発生率実測値が期待値より大きければ正の方向で、小さければ負の方向で0から離れた値をとります。実測値と期待値のズレが大きいほど0から離れた値になっていくわけですね。
と、そんなこんなでとりあえず MI score と呼ばれる値は計算可能ですし、その値が持つ意味みたいなものもなんとなくはわかります。しかしなぜこの値が「相互情報量(mutual information)」などという呼び名なのかが気になってしまってスッキリしません。
実は情報理論でいう「情報量(amount of information)」というのは我々(=文系ちゃん)が日常語で使う場合と意味が異なるようです。以下(諸般の事情により不正確な)引用は全て『Foundations of Statistical Natural Language Processing』からです。
The entropy (or self-information) is the average uncertainty of a single random variable:
>>
Entropy measures the amount of information in a random variable. It is normally measured in bits (hence the log to the base 2), but using any other base yields only a liner scaling of results.(p.61)
情報量とは「エントロピー(entropy)」のことらしい。そして entropy はある「確率変数(random variable)」の不確実性の平均値だそうな(上の記述では entropy の同義語としていますが self-information を別の意味で使うこともあるようです。その場合の self-information はある事象Aが起こる確率がP(A)であるとき I(A) = log(1/P(A)) = -log(P(A))なんだとか。これを「情報量」と呼ぶ人もいます)。
具体例としてジャンケンを考えます。ジャンケンの entropy は完全にランダムな場合には確率変数Xのとる値{x_1, x_2, x_3}つまり{グー、チョキ、パー}の確率P(x)が全て等しく1/3だと考えられるので H(X) = -((1/3)*log(1/3) + (1/3)*log(1/3) + (1/3)*log(1/3)) = 1.584963bits と計算できます。これは H(X) = log(n=3) = 1.584963bits と同値で、この場合の entropy が取り得る最大値です。つまり完全にランダムである(何が起きるかもっともわかりにくい)とき entropy は最大になります。
これに対して H(X) が最小値0となるのは P(X=x)=1 があるときです。パーしか出さないという変わった人がいた場合、この人のジャンケンではパーのP(x)だけが1で(確率関数P(x)の総和は1なので)他は0になります。H(X) = -(1*log1+0*log0+0*log0) = 0bits です(log0=0として処理)。つまり絶対確実に何が起きるかわかっているとき entropy は最小になると考えられます。
二つの確率変数XとYがあったとき、それらの entropy はそれぞれH(X)とH(Y)で表せます。両者の関係をみるにはH(X, Y)すなわち「結合エントロピー(joint entropy)」の定義を知る必要があります。
The joint entropy of a pair of discrete random variables X, Y 〜 p(x,y) is the amount of information needed on average to specify both their values. It is defined as:
>>
(p.63)
H(X, Y) は上記のように定義されます。H(X) と H(Y) が全く無関係で独立しているとき H(X,Y) は H(X)+H(Y) と同値ですが、確率変数同士になんらかの関連があると「重なり部分」が生じるため H(X, Y) は H(X)+H(Y) より小さな値になります(ベン図を想起してください)。
「相互情報量(MI)」はこうした entropy の考え方のもとでは I (X; Y) と表記し、 H(X) と H(Y) の重なった部分のことを指すようです。次の式で表せます。
I (X; Y) = H(X) + H(Y) - H(X, Y)
詳しいことは省略します(「条件つきエントロピー(conditional entropy)」「相対エントロピー(relative entropy)」等々)が、あれこれいじくり倒すと下記の式になります。
>>
なにはともあれメデタシメデタ...あれ? 相互情報量の項でみた MI score の式と雰囲気は似ていますが同じではありません。前のは負の値をとりますがこっちは必ず0か正の値です。なんでやねん...。
ショック!前のはマガイモノだったようです。みんなニセモノつこてたんかい!!
In this section we have defined the mutual information between two random variables. Sometimes people talk about the pointwise mutual information between two particular points in those distributions:
>>
This has sometimes been used as a measure of association between elements, but there are problems with using this measure, as we will discuss in section 5.4.(p.68)
なんと正体は pointwise がついた「pointwise mutual information (PMI)」とかいうのだったんですね。銀座と戸越銀座みたいな違いでしょうか?(←!)よくわかりません(けど対象が random variables か values of random variables かの違いのようです...)が。しかもなんか問題あるっていってるし(汗)。
We can say that mutual information is a good measure of independence. Values close to 0 indicate independence (independent of frequency). But it is a bad measure of dependence because for dependence the score depends on the frequency of the individual words. Other things being equal, bigrams composed of low-frequency words will recieve a higher score than bigrams composed of high-frequency words.(p.182)
section 5.4 は Mutual Information というタイトルですが PMI についてあれこれ論じています。PMI の問題点というのは上で引用したように independence について完全なとき(つまり無関係なとき)はちゃんと 0 になるので良い測度なのだけど dependence についてはダメダメなことだとか。
P(x) = P(y) = P(x, y)になるとき、つまり相互情報量の項で言及した例でいえば「w1 の出現率」と「w2 の出現率」と「w1 と w2 が共起した率」とがすべて一致する(w1 と w2 は w1 w2 という連語でしか出現しない)場合に I (x, y) は log(1/P(x)) となります。P(x) = P(y) = P(x, y) が大きな値(high-frequency)であればあるほどその逆数である 1/P(x) は小さな値になってPMIが低得点=マズー...という話のようです。
実はマジきづいてたわーそれ Tag Cloud で使ったときからきづいてたわー
ええと、冗談じゃなく結構ホントです。濃淡付けの規準に困ってました。うーむ、やはりそうでしたか。
簡単に触れようと思っただけなんですが MI score だけでも(しかも途中かなり端折ったのに)結構大変でした。また貴重な時間を無駄に浪費してしまって...。こんなことに時間を使うんだったら先週末のアレコレに顔を出してみた方がよっぽど有意義だったかなあと後悔しきりです。是非御挨拶したかった方々もおられたし。
と、いうことで簡易 Tag Cloud で使った残りの共起強度測度のうち t-score についても若干謎があって気にはなってるんですけどそれは全力で忘れておきます。log-likelihood ratio も以前言及したときだけでも 3種類の計算法があってムムムム...な上に、その後ちょっと調べるとロジスティック回帰分析の一環としてのものなんかもあるようで切りがありません。やはり忘れましょう(←!)。斬られ役に手をかけてる場合じゃないので。
ちなみに共起強度選択リストの最後に加えておいた modified overlap coefficient というのは私が長年使っている測度です。考案したのはもうカレコレ10年近く前になるのか...(ウッ...なんか自分が可哀想すぎて吐きそう:涙)。多次元尺度構成法(MDS)用にKUFUして自作したものなんですが、あとで overlap 係数という既存のモノに考え方が似ていると気づきました。
いやーおれつくってたわーオーバーラップ係数知らなかったのにつくってたわー
でも「おれちゃん係数」と主張するのもアレなので overlap 係数を弄ったものだ、と説明するようにしています。あと、そういえば「なんでエントロピーを H(X) って書くん?」という疑問がずーっと頭を離れなかったのですが、なんだかんだで実は謎なんだそうです。そもそも H がエイチなのかギリシア文字の eta のことなのかでも意見の一致はみられていないんだとか。
>> Why is “h” used for entropy?
数学者というのも謎な人々だなあ、とよく思います。こまけえことにすごくうるさそうな反面、こういうところでおそろしく無頓着というかなんというか。
とりあえずそんな感じで。
ちょっと!!
>> 
林知己夫先生の「数量化理論」がらみの特集らしいのですが「?」な用語が見受けられます。
>> 社会調査協会
軽量化III類と多重対応分析・・・村上隆
公式サイトの文言だしマジでそんなのあるんかと焦った。軽量化した数量化III類のことだろうか...しかしこの場合の「軽量化」ってどういうことや...計算が簡単なんやろか...云々。
ですがワクワク(←?)しつつ販売を行なっている有斐閣サイトで目次を確認するとこう↓なってました。
>> 社会と調査 第9号
【特集 数量化理論の現在】数量化理論の形成(森本栄一)/数量化の発想と考え方(高橋正樹)/数量化理論による分析方法の利用の視点から(林文)/数量化3類と多重対応分析(村上隆)/数量化理論と社会調査,そしてそれから(吉野諒三)/言語研究と数量化理論(阿部貴人)
やっぱし「数量化3類と多重対応分析(村上隆)」です。ホッとしたようなガッカリしたような...。
それでも公式サイトの記述が正しく有斐閣が間違っている可能性もゼロではないので Amazon も覗いたところ『社会と調査(第9号)』は目次情報も表紙画像もないので確認はとれませんでした。
むむむ...そんな感じで。
今まで色々調べたりしてみたけど本筋では使わないなあ...と捨て置いたような諸々を廃物利用しつつ、比較対象というかぶっちゃけ噛ませ犬的な引き立て役に使おうと目論んでチマチマと Tag Cloud を生成するCGIを作ってみました。急がば回れという気持ちでやったんですが正直回り込み過ぎだったような。
>> Tag Cloud
ファイルを選択して submit で Tag Cloud を出力します。私の研究対象は日本語テクストですので英語については(少なくとも現状では)あくまでオマケという意識です。CGI作成初期段階での動作確認用に使って(←日本語に起因する問題を回避するため)以後そのまま未調整にて放置しているので項目の選択精度にはかなり問題もあります。ま、言い訳なんですけど(滝汗)。
やや詳しい話は後述しますが、研究対象としての Tag Cloud 技法については2009年くらいの段階でもう相当に複雑化が進んでいて、現時点では進化の袋小路的なレベルに入り込んでいる気配があります。そのぶん比較的単純なものについては一般でも広く利用されている状況が見て取れるので「その技法の有用性について納得がいく説明をしてくれたまえ(ドヤ顔)」とかいうウザい(自動化された定番のクソくだらない)難癖に対処する手間は少なくて済みそうです。精神衛生上これは大事な利点かと。
ちなみに日本語版の分析例だと以下の通り↓です。
>> 
同じ対象を本筋の手法で分析するとこんな結果↓です。
>> 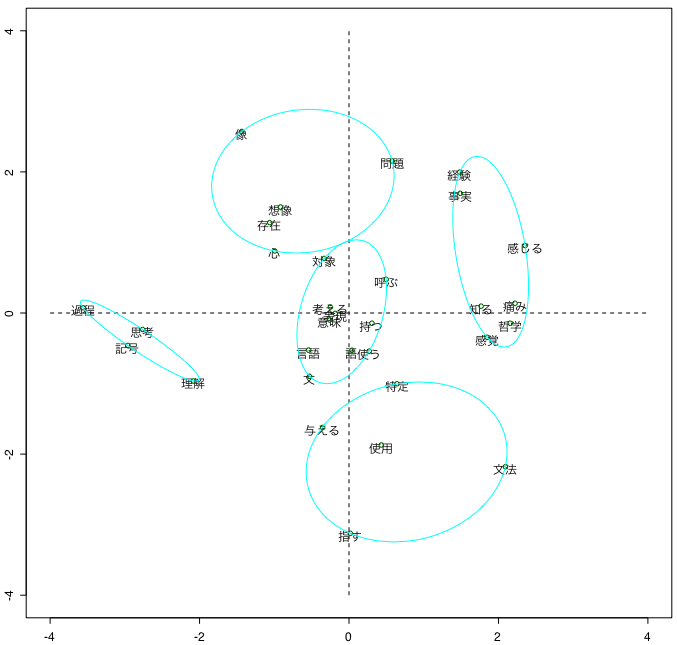
対象テクストの視覚化という点では共通性がなきにしもあらずなのですが、前者と後者は語彙項目の配置が持つ意味が全く違っています。絵地図と地図の精度差というか用途の違いみたいな感じでしょうか。
ダグラス・クープランドが Tag Cloud の発案者とされています。あの『ジェネレーションX』の作者ですね。と、いってもヤングは知らんかもしれません。私は読んでないので未確認ですが『マイクロサーフス』で使用されたのが最初だとか(シュールレアリストが先だという異説もあるようです)。
ええと、いずれにせよクープランドの経歴から考えるに美術方面(?)から生まれた手法だったということなんだと思います。タイポグラフィーとかとか。デザイン的興味からであって、テキストマイニングだとか内容分析とかいう意識では全くなかったってことなんでしょう。
などと延々書いていくと疲れるので端折ります。
>> Visualising a text with a tree cloud (PDF)
これ↑にかなりよくまとまっているように見えました。なのでこれだけ読んどけばとりあえずは十分なんじゃないかと。『マイクロサーフス』英語版の事例も引用されています。独語版とはかなり様子が違っていますが何か理由はあるんでしょうか。ちょっと気になりました。
あと一般への普及についてはたとえば New York Times での使用なんかがあげられます。
>> Most Popular → Most Searched → TAG CLOUD
表示方法を LIST にするとただの検索数が多かった順上位リストになります。Tag Cloud 表示の方が実際の検索数に応じた文字の大きさになっているので単なる順位よりは情報量が大きい感じもしますがどうなのやら。大抵は文字色の濃淡などでも何らかの情報を表現するのですが、ここでは使っていないようです。
項目の単位として複合語や連語も扱っているので「お!」と一瞬技術的な興味を惹かれたのですが、単にこうしたものがそのままの形で検索窓に突っ込まれる事例が多いってだけなんじゃないかと。わかりませんけどね。(11月13日現在で「2012 presidential election」と「election」があって前者の方が大きい字で表示されているということは、やはり特に工夫はしていないってことじゃないかしらん)
項目の並びはアルファベット順です。これも一見手抜きっぽいのですが、中心からグルグル(?)表示する手法に比べて結果同士の異同を発見するという用途では優れています。この場合のように変化をみたいのなら適切な選択といえるでしょう。
えーと、最後に文系的(?)な利用例に言及します。University of Glasgow の Scots Project サイトです。
BNCなどで検索した結果は通常KWICで表示されますが、ここ↑では Tag Cloud を作っています。またBNCは比較用に使っているだけでメインは Scottish Corpus のようです。
適当に検索語を入れてみるとわかるのですが、内容分析をやろうとしているわけではない(←均衡コーパス相手ですからね...)ので全くフィルタリングされておらず、a だの the だの of だのが我が物顔で登場してきます。Scottish と British の比較という観点ではそこからこそ色々有益な情報が得られるのでしょうが。
そして Tag Cloud の表現手法としては文字の大きさが出現頻度の高さを表し、文字の濃淡が検索語とのコロケーション度合いに対応しています。この度合いはMI (mutual information score)を使って計算しているのですが他の様々な計算法を使用した場合にどういう違いが出るのか比較してみると面白いかもしれません。
というかぶっちゃけ(←またか!)上でリンクした自作の Tag Cloud では log-likelihood ratio を使ってるんですけどね。コロケーション度合いというか共起性というか類似度/非類似度というか、ま、そういうあたりの色々な計算法の違いを視覚化して(予備知識ゼロだし今後も特に学ぶ予定はない人々にもわかりやすく)示せそうなのが、遠回りして Tag Cloud 用CGIを作ってみてよかった点というか「瓢箪から駒」みたいな感じというかなんというか(11.19 追記:log-likelihood ratio、MI score、t-score、modified overlap coefficientの4つの計算法を選択して共起強度の濃淡をつけられるようにしてみました。諸事情により厳密性はありません:汗)。
でも時間と労力(と希少な気力:笑)を浪費してしまった点が現状では致命傷になりかねないんじゃないかと結構後悔はしていたりもするわけですけど。「勤勉とはいえないが真面目」という人間は productivity が異常に低くなる傾向があるため世間からの風当たりはことのほか強かったりします。
などど愚痴と弁解ばっかりでもアレなので自重しつつ、ま、そんな感じで。
くっそ迷惑なんですけど(怒)。なんかインターネットのエラい人達団体(?)とかから圧力かけられないんすかね。営利企業なんだから何やってもいいでしょ?みたいなノリを野放しにしてちゃダメだと思うんです。
>> New Twitter API Drops Support for RSS, Puts Limits on Third-Party Clients
Since its inception, Twitter has allowed developers to access Twitter timelines and search queries using RSS. As a result, lots of social aggregators have used RSS as an easy way to pull in tweets alongside messages for other services.
Apps that use RSS, XML or Atom will need to shift to JSON or other API methods by March 5, 2013.
これには「March 5, 2013」とあるのですが、この間の10月11日にイキナリ廃止されました。唖然&呆然。
で、オイラがちんまりと自作したCGIスクリプトもこの余波で機能しなくなりました。チーン...(←ご臨終エフェクト)
ハッシュは表示されますがアカウント毎のtweetは表示されません。この違いは別々のところからRSSを参照してくるように(手探りで:笑)作ってあったためです。どうやらハッシュを引っ張って来てる方はまだ生きてる模様。
>> ツイッター(Twitter)のつぶやきをRSSで読む方法
上記引用先のコメント欄にこんな書き込み↓がありました。
1. Astor 2012年10月11日 10:00
どうにも本日(2012/10/11)からXMLとRSSは404になるみたいですね
http://api.twitter.com/1/statuses/user_timeline.rss?user=アカウントID でまだアクセスできます
遠からずTwitterのRSSは廃止になりますが、それまでのつなぎに
うーん...とりあえずこっち系統が来年3月まで維持されるのであれば、オイラのCGIも当面は小改造で乗り切れるのでアレなんですが、でもそれでも面倒くさいし今それどころじゃないし。あったまくんなーもう。
しばらく前にTwitterで見かけて「ふむー」となったtweetがありました。
コーパスがXML化される意義はとても良く理解できる。でもプログラミングをしない研究者にはコーパス言語学への敷居がますます高くなった。プログラミングを利用する研究者は絶滅危惧種とのことだったが、下手するとコーパス言語学の研究者自体が絶滅危惧種になりかねない。
「XML化」といってもたぶん色々あって、SGMLとかで独自にタグ付けしていたものがXML化されるのであれば格段に簡易化されて使いやすく&作りやすくなるだけだと思うんですよね(BNCなんかはそうなのかな?)。SGMLバージョンのBNC生データ(?)を弄ったことがありますが「なんじゃこりゃー!!」でしたよ。なのでRSS(その実体はXMLで記述されている)を弄り始めたときに抱いた第一印象は「BNCに比べりゃカーンタンだぜ!」でした。すごく単純でわかりやすいものに見えたんです。
実際XMLの位置づけってそんな感じみたいですしおすし。『Perl&XML』の前書きから引用します。
XML, the latest and best markup language for self-describing data, is becoming the generic data packaging format of choice.(略) More powerful than HTML, yet less demanding than SGML, XML is a perfect solution for many developers. It has the flexibility to encode everything from web pages to legal contracts to books, and the precision to format data for services like SOAP and XML-RPC. It supports world-class standards like Unicode while being backwardscompatible with plain old ASCII.
XML化が面倒だとすれば、全くメタ情報というかデータ構造を持たないコーパスを改修する場合でしょうか。利用する方は(メタ情報がいらないのであれば)XMLタグを全部取り除いて処理すればよいだけ(←テキストデータを扱えて正規表現が使える計算機言語なりソフトウェアを使えば誰でも可能ですよね?)なので特に問題はないでしょう。
作る側であっても従来通りのタグ付けコーパスより特に手間がかかるという感じもありません。タグの解析をしながら利用する人(←コーパス言語学者?)もコーパス毎に全く違った様式をあれこれするよりは共通した仕様の方が作業がしやすいんじゃないですかね。今ひとつデメリットがわかりません。
というかですね「XMLを使い続けようよみんな!」といいたい。ちょろちょろ変更すんのやめれや!っていうか。
私が最初に色々コーパスのタグとかを見始めた時期にはまだXMLは普及しておらずTEIだのココアだのSGMLだの...調べたことが全部無駄になったっつーの!!!(←笑?)この分野(マークアップ言語研究?)の専門家ならそういう変化にもすぐ対応したりすることが苦でもなくあれこれ新しい規格を考案すること自体に興味もあるんでしょうけど、それを何かの目的で使っているような人間(たとえばオイラ)からすれば「変えないでよ!」というのが切実な願いです。
昔『The World of Golden Eggs』というのがあって、そこに七面鳥のケヴィン先輩と後輩のポールというコンビが出てたんですけど、なんかそれを久しぶりに思い出したりしました。
>> トップ5リターンズ
これの火曜日を聴いてて思ったんですが。失礼な後輩(ボケ)と先輩(ツッコミ)の関係みたいな感じが似てる(←ツッコミの先輩が実はズレてるので後輩のボケがツッコミにもなっている...みたいな感じというか)かなあ...とか。七面鳥コンビと違ってこっちの後輩はNHK出身らしいので滑舌がいいですけどね。
というか、神田愛花さんの話し方はすごく好みで困る(恥笑:汗)。なんだろう、どういう要因でそう感じるのか解析できなくて居心地悪い。自分が北海道弁なくせに他人の発音間違いにはイラっとする習性とかと関係あるかも。もともとの声質にプラスしてNHKで教育されてて東京出身(←マチガイです。横浜出身だそうで...好感持ったのは単にハマっ子つながりか...)(クリアでスピード感アリ)というところでアレなんでしょうか。なんつかNHKって「東日本大震災」の発音をどうすべきかとかで真剣に悩んだりするところらしいですからね。
「ひがし」は「ドミミ」で「にほん」は「ドミド」なんですが「ひがしにほん」は「ドミミミミド」になります。日本語(共通語)の単語では一度下がったら上がらないという規則(?)があるので「に」で下げたら「ドミミドドド」になっちゃうこともあって(←アヤシイ説明やな!)発音が変わるんですよ。これが更に「ひがしにほんだいしんさい」になると(細かい話ははぶいて)「東日本、大震災」と二語の意識で発音するか「東日本大震災」と一語として発音するかで読み方が変わってくるわけですね。
NHKは結局どっちに統一したんですっけねえ...(←テキトーか!)
とりあえずそんな感じで。
前回「対数尤度比検定」についてアレコレ吐き出してみたらかえって頭の中のぐーるぐるが悪化しました。超うざい。なんとかせねば。
>> Dunning's loglikelihood ratio test and G-test
そこで作業をある程度自動化するために上のリンク先にあるような関数ファイル(←こういう呼び方でいいのかな?)をつくりました(10.02 ちょこっと修正)。このファイルをRで読み込むと三つの関数が使用できます。
使い方はだいだいこんな感じ↓です。
D.ccoe(c1=12593,c2=932,c12=150)
D.ccoe(12593,932,150)
G.ccoe(a=150,b=12443,c=782,d=14294293)
G.ccoe(150,12443,782,14294293)
DG.ccoe(c1=12593,c2=932,c12=150)
DG.ccoe(12593,932,150)
関数名には"ccoe"という世間的には無意味な文字列がくっついているので関数カブリ(?)の心配はないかと。D.ccoeはDunning1993に出て来たらしい New York Times corpus の分析表用に特化してあります。
早速ですが『Foundations of Statistical Natural Language Processing』の174頁にある表と比較してみます。D.ccoeがとる三つの値は下の表にあるc1,c2,c12の値です。Nは14307668に固定しています。
| w2 | w2以外 | ||
| w1 | c12 | c1-c12 | c1 |
| w1以外 | c2-c12 | N-c2-c1+c12 | N-c1 |
| c2 | N-c2 | N |
前回と微妙にマス目の名前が異なるので(もし試してみようという方がおられれば...いないか:笑?)注意してください。下にD.ccoeの計算結果と表の数値の一部を抜き出しました。以降Rの出力などを含む引用は全て見やすいように適当に編集してあります。
D = 1291.319(1291.42) D.ccoe(12593,932,150)
D = 100.5019(99.31) D.ccoe(379,932,10)
D = 82.37586(82.96) D.ccoe(932,934,10)
D = 80.36915(80.39) D.ccoe(932,3424,13)
D = 57.28908(57.27) D.ccoe(932,291,6)
(中略)
D = 40.62556(40.45) D.ccoe(932,3694,8)
D = 35.53571(36.36) D.ccoe(932,47,3)
D = 35.58569(36.15) D.ccoe(932,268,4)
D = 35.21179(35.24) D.ccoe(932,5245,8)
D = 34.74123(34.15) D.ccoe(932,3,2)
検定統計量はカッコ内が表に載っていた数値です。計算結果とまったく合致していません。このD.ccoeは前回示した2種類の計算法のうち2項分布関数dbinomを使うやり方を採用しています。もしかするとそのあたりに何か原因があるのかも...と思ったので『英語コーパスと言語教育』の方法で計算するG.ccoeもデッチアゲました(2×2の表にしか対応してませんが:汗)。比較にはDG.ccoeを使います。
> DG.ccoe(12593,932,150)
D = 1291.319 p-value = 0
G = 1291.319 p-value = 0
(中略)
> DG.ccoe(932,3,2)
D = 34.74123 p-value = 3.765707e-09
G = 34.74123 p-value = 3.765707e-09
全く一緒です。でも p-value=0 などという怪しげな数値が出ているので信用できそうにない気もしないでもありません。そこで・・・
ものすごく(ほんとにすごく!)信用のある先生が作成なさった既存の関数を使って検算してみます。
対数尤度比に基づく独立性の検定(G-squared test)
data: matrix(c(150, 12443, 782, 14294293), byrow = TRUE, nc = 2)
G-squared = 1291.319, df = 1, p-value < 2.2e-16
G = 1291.319 p-value = 0 (G-test)
(中略)
対数尤度比に基づく独立性の検定(G-squared test)
data: matrix(c(2, 930, 1, 14306735), byrow = TRUE, nc = 2)
G-squared = 34.7412, df = 1, p-value = 3.766e-09
G = 34.74123 p-value = 3.765707e-09 (G-test)
まあ p-value の処理はG.ccoeの方がイイカゲンというか無知なのでアレですが検定統計量は同じですね。削ってもまだゴチャゴチャしているのでG値の部分だけ色を変えました。
いずれにせよ私の間違いではないようです。しかしあのDunning1993にこんなデタラメな表が使われていたなんてスキャンダルじゃないのか...と思って確認してみたんですが(←今頃かっ!)Dunningは計算間違いなんてしていませんでした。本物(?)の表の数値は計算結果と一致しています。
G = 270.7219(270.72) G.ccoe(110,2442,111,29114)
G = 263.8966(263.90) G.ccoe(29,13,123,31612)
G = 256.8365(256.84) G.ccoe(31,23,139,31584)
(中略)
G = 37.19584(37.20) G.ccoe(6,41,70,31660)
G = NaN(37.15) G.ccoe(2,0,2,31773)
G = 36.97986(36.98) G.ccoe(3,10,5,31759)
えー、一箇所「NaN」が出ておかしくなっているのがありますがマス目に「0」があるケースの処理をしていなかったために出たエラーです。マンドクセーのでとりあえずそのままで(というわけにもいかんのでスクリプトをちょこっと修正しときました:汗)。まあ、とにかく『Foundations...』は bigramに関する考察をするという点でのみDunning1993を踏襲しただけで実際の計算に使う表は全く別モノだったようです(図や表の著作権って結構ウルサイですもんね、そういえば)。紛らわしいのう。こういうタイプの本はいろんなことを幅広く扱ってくれてるんでチェックが行き届かないのは仕方がない部分もあるんですけど。
さてとぽてと。ここまでざっと「対数尤度比検定」の謎(?)を概観してみて、なんとなくわかった(気がしないでもない...)ことをまとめてみます。
検定統計量としては尤度比λの対数をとってlogλ、それに-2をかけてカイ2乗分布に近似させるということをしていました。対数をとるのはともかく「なんで-2をかけるの?」と疑問だったんですけど、これ実は「-2」じゃなくて「正負逆転」と「2乗」なんじゃないかと思われます。
以下ちょっと説明してみます。前回のL1とL2という尤度関数を今回の表で書き直すと次のようになります。dbinomはBで表記しました。
L1 = B(c12,c2,c1/N)*B(c1-c12,N-c2,c1/N)
L2 = B(c12,c2,c12/c2)*B(c1-c12,N-c2,(c1-c12)/(N-c2))
L1とL2はどちらも「w2に対するw1出現率確率」と「w2以外に対するw1出現率確率」の積です。「出現率確率」というすっごくアタマの悪そうな表現をしていますが他の言い方がわかりません。すんません。あと参照用に表をコピペしときます。
| w2 | w2以外 | ||
| w1 | c12 | c1-c12 | c1 |
| w1以外 | c2-c12 | N-c2-c1+c12 | N-c1 |
| c2 | N-c2 | N |
B(c12,c2,c1/N)の例だと、「w2に対するw1出現数(c12)」を「w2出現数=試行回数(c2)」で割った値が「w2に対するw1出現率」にあたります。2項分布パラメータ(母数)の「確率」は「母比率(サイコロだったら1/6だしコインだったら1/2みたいなそうあるべき確率)」のことなので、ここではそれを「総語数に対するw1出現率(c1/N)」と想定しています。
なので「w2に対するw1出現率確率」とは、想定した母比率にもとづく2項分布で計算される「w2に対するw1出現率」の確率(=あるある率)という意味です。
L1とL2では母比率の想定が少し違います。L2では「w2に対するw1出現率」や「w2以外に対するw1出現率」をそのままそれぞれの母比率として計算して(別々の母数を持つ2項分布に属していると考えて)います。この想定では「出現率」が常に母比率と一致することから「出現率確率」は他がどうでもいつでも最大値(サイコロでぴったり1/6となる実測値が出た感じ)になります。現状追認型の幸せ思考みたいですね。
で、積であるL2の値もフルタイムマキシマムです。「パラメータ空間における尤度関数の最大値」がどーのこーのというのがこういうことなんでしょうか?(←疑問か!)。
一方、L1が最大値(L2と同じ値)になるのは三種類の母比率が全く同じケースだけです。少しでもズレてしまうと「出現率確率」は最大値をとれません。そんなこんなで両者の比であるλは0から1の間の値になるとわかります。
つまりL1で表現された(帰無)仮説「w1とw2の出現率は独立である(無関係である、影響関係にない)」が「ごもっともですのう...」という程度が大きくなるほど1に近づき、「そうですやろか...」という度合いが高まると0に近づくのです。これなら確かに「(その仮説は)尤(でござります)」度比といえます。
そして対数をとるとL1=L2のとき log1=0です。これ以外は常にL1<L2なのでlog(L1/L2)=log(L1)-log(L2)は負の値で、差が大きいほどマイナス方向に大きくなります。帰無仮説が「ごもっとも」なとき最大値の0に近づき、そうじゃないとどこまでも大きな負の値すなわち最小値をとるという関係がこのときも維持されます。
常に0か正の値であるピアソンのカイ2乗統計量と対数尤度比を似せるにはまず「正負逆転」させなくてはなりません。なので logλは -logλにします(この時点で非「ごもっとも」度化したような...)。あとやっぱり「2乗」がないとそれっぽくないんで(←!)尤度比λを2乗しときます。 logλ^2は 2logλですので、両方の結果を合わせて -2logλ...ってことかな?(←質問か!)
なんとなく誤摩化しつつ書いてきましたが、もうひとつ大きな謎が残っています。なんだか知りませんけど対数尤度比検定のことを「G検定(G-test)」って呼ぶ人が結構いるんですよ(Gが2乗されてて G-squared という人もいます)。一応全部同じものを指しているようなんですけど...。
wikipediaの「G-test」にはこう↓ありました。
An application of the G-test is known as the McDonald-Kreitman test in statistical genetics. Dunning introduced the test to the computational linguistics community where it is now widely used.
Dunning は考案したんじゃなくて言語研究に導入したんだ、ということのようです。G-test自体はもっと前からあったみたい。そっちの方でいろいろゴチャゴチャあったんでしょう。というわけで「なんでGなん?」の謎解きは時間と労力が無駄にかかりそうなので放置しときます。
そういえば作ったっきり放置していたものがありました。OOP技術を導入したつもり(←笑?)のレマタイザ改造モジュール。従来通りの使用法にも対応したので権利関係等々のメタ情報記載が済めば公開できそう(してもらえそう?)な出来具合だったんでちょっといろいろ残念に思うところもあります。珍しく世の中のお役に立てそうなチャンスだったのになあ、みたいな感じで。
先様に連絡というか御挨拶しようと思った矢先(今年の2月か3月頃かな?)に公開されていたレマタイザ関連ファイル類がサイトごとネットから完全消失してしまったのでオロオロして今に至っています。原因は単純にそのタイミングで大学サイトが大改修された余波だと思われるんですが。
でもこういうことって一旦タイミングを逃すとアレなんですよね...。
こんなことやってる場合でもないんですが「計量的言語研究の諸相」以降なんとなく頭の中をぐーるぐるしていてジャマくさいのでここらでアレコレ吐き出しておきます。
「対数尤度比検定 loglikelihood ratio test」は自然言語を対象とした研究ではカイ2乗検定より優れたものとして使われてきたそうです。でも最近はオワコン扱いされることも多いのだとか。まあ、世間がどうあれ私のやっていることとはあんまり縁がない&最初にこの用語を聞いたときに「対数誘導(たいすうゆうどう)」と空耳したこともあってワケワカラン感が強い...等々の理由で放置していました。
でもこれって空耳しなくても用語に違和感がありませんかね? 私はかなりあります。likelihood の意味ってなんだかピンとこないし、その訳語の尤度(ゆうど)っていうのも全然イメージがわかない。『すぐわかる統計用語』によれば尤度比λというのは以下のようなものだそうです。
λ=(パラメータ空間の部分空間上での尤度関数の最大値)÷(パラメータ空間上での尤度関数の最大値)
実際には分数で書いてあるのですが上の引用では除算記号を使いました。はふ。なにいってるのかわかりません。ただ対数尤度比というのは尤度比の対数をとった値で、尤度比は尤度関数の比なんだな、というのはわかります。
「尤度関数 likelihood function」についてはこう書いてありました。
母集団のパラメータをθとし、その母集団から取り出したデータxの確率をP(x;θ)、または確率密度関数をf(x;θ)とする。このとき、母集団から取り出したN個のデータ x1,x2,...,xNに対し
L(θ)=L(x1,x2,...,xN;θ)=P(x1;θ)P(x2;θ)...P(xN;θ)
L(θ)=L(x1,x2,...,xN;θ)=f(x1;θ)f(x2;θ)...f(xN;θ)
をパラメータθに関する尤度関数という。
句読点表記を変えています。というか、色々正確じゃない引用になってます。
えーと、やっぱり何がなんだかわかりませんが尤度関数というのは確率っぽいものの積のことらしいのう...みたいなことは言えそうです。しっかし、こういう説明で「ふんふんなるほど!」ってわかる人のことは羨ましいと思うし、そういう人達向けに本が書かれるのもしかたないのかもしれませんけど、軽くイラッとはします。というか、この説明でわかるような人にはそもそも説明なんていらんのじゃないかしらん。
対数尤度比検定は Dunning1993で使われたのが最初だとかなんだとか。で、そこに出て来たと思しき(←確認しろよ!)事例が『Foundations of Statistical Natural Language Processing』で紹介されています。
Hypothesis 1. P(w2|w1) = p = P(w2|not w1)
Hypothesis 2. P(w2|w1) = p1 not equal p2 = P(w2|not w1)
例によって引用元とは表記を変えざるを得ませんでした。bigram w1 w2 (つまりw1とw2という2語の連語)において仮説1は「w2とw1が共起するときの確率とw2がw1以外と共起する確率に違いはない=w2とw1は無関係で独立している」をあらわしています。仮説2はこれの対立仮説で「w2とw1が共起する確率はw2とw1以外が共起する確率と同じではない=有意差がある」というものです。
これらの仮説それぞれの尤度関数をもとめて比の対数をとればこの場合の対数尤度比が計算できるらしいので、語の出現確率を2項分布と仮定しつつ具体的な値を入れて R でやってみます。w1がmost(出現数12593)、w2がpowerful(出現数932)、w1w2つまりmost powerfulの共起数が150です。使ったコーパスの word token 総数は14307668だとか。
> c1<-12593#mostの頻度
> c2<-932#powerfulの頻度
> c12<-150#most powerfulの頻度
> N<-14307668#word token総数
> p<-c2/N#全コーパス中でのpowerful出現率
> p1<-c12/c1#mostを含むbigram中でのpowerful出現率
> p2<-(c2-c12)/(N-c1)#mostを含まないbigram中でのpowerful出現率
> L1<-dbinom(c12,c1,p)*dbinom(c2-c12,N-c1,p)
> L2<-dbinom(c12,c1,p1)*dbinom(c2-c12,N-c1,p2)
>-2*log(L1/L2)
[1] 1291.319
dbinomの三つの値は左から出現数x、標本サイズsize、確率probです。簡単な表をつくるとわかりやすいかもしれません。
| most | most以外 | ||
| powerful | c12 | c2-c12 | c2 |
| powerful以外 | c1-c12 | N-c1-c2+c12 | N-c2 |
| c1 | N-c1 | N |
ふむふむ...対数尤度比の計算結果は約1291.32か...どれどれ参考図書の数値はどうなっとるかなっと...1291.42...うそーん(滝汗)。
Rでの処理の最後で -2*log(L1/L2) という計算をしています。理屈はよくわからないのですが、-2を対数尤度比に掛けてやると値がカイ2乗分布で近似されるようになるんだとか。
カイ2乗分布に近似する検定統計量としては「(ピアソンの)カイ2乗統計量 Pearson chi-square statistic」というのがあります。
(((実測値-期待値)^2)÷期待値)の総和
「実測値 observed frequencies」と「期待値 expected frequencies」のズレを計算した値です。ズレの大きさに関する測度なので2乗して正負の符号が関係なくなるようにしつつズレの値も大きくなるように処理しています。期待値で割って比にしているのは規模による影響を小さくするためだと思われます。
ところで『英語コーパスと言語教育』ではこれまでみてきたのとちょっと違った方式で対数尤度比の計算をしています。引用元の表記と違ってしまってますが概ねこんな内容のものが紹介されていました。
2×(((log(実測値)-log(期待値))×実測値)の総和)
この式(?)をみると対数尤度比検定は more appropriate for sparse data という性質を持つことがよくわかります。語彙の出現率というのは極端なバラツキを示すため、2乗してズレの大きさを強調するカイ2乗統計量よりも対数をとって小さな値にしてしまうこちらの方が自然言語の分析には適しているというわけです。(←この説明間違いくさいです。実測値と期待値の差ではなく想定する母比率の違いに応じた差の測度的なものを扱っていると考えるべきかもしれません。対数の使用も比を差に変換するのが主な理由のような気がします。とにかくまだよく飲み込めていません。すみますみません)
とりあえずこちらの方法でも実際に計算してみましょう。
most powerfulという形で共起するときの実測値はc12すなわち150です。コーパス全体におけるpowerfulの出現率pはc2/Nですから、このpをc1に掛けると0.8203067になってこれがw1がmostである場合におけるpowerfulの期待値になります。計算結果は大体781.3068くらい。(w2がpowerfulである場合におけるmostの期待値を計算する...という考え方でc2*(c1/N)を使っても同じ結果になります...よね?)
この値は2×2のマス目のうち左上の分です。同様にして4つのマス目全部の分を計算して総和を求めてから2倍すると先述したやり方での検定統計量と一致するはずです。(...と、いいつつ若干うまくいってないのですが丁寧にやってる時間がないので気が向いたら直します:汗)
で、ボンヤリとですがこの式と -2*log(L1/L2) の計算結果がなぜ合致するのか考えてみました。一つには対数では乗除法が加減法になるからなんじゃないでしょうか。
log(L1/L2)はlog(L1)-log(L2)になります。 log(dbinom(c12,c1,p)*dbinom(c2-c12,N-c1,p))- log(dbinom(c12,c1,p1)*dbinom(c2-c12,N-c1,p2))はlog(dbinom(c12,c1,p))+log(dbinom(c2-c12,N-c1,p))-log(dbinom(c12,c1,p1))-log(dbinom(c2-c12,N-c1,p2))に展開できるので、-((log(dbinom(c12,c1,p1))-log(dbinom(c12,c1,p))+log(dbinom(c2-c12,N-c1,p2))-log(dbinom(c2-c12,N-c1,p)))というように組み替えられます。これに -2 を掛けて -2logλとした結果をまとめると以下のような感じでしょうか。
2×((log(実測値の確率)-log(期待値の確率))の総和)
出現数ではなく出現率を扱うことで「mostを含むbigram中でのpowerful出現率」と「mostを含まないbigram中でのpowerful出現率」という2列(columns)の中に結局4マス分の数値を含むからOKってことなんでしょうかね。よくわかりませんが。(で、たぶん2行(rows)の方を扱っても同じ計算結果になるんです...よね?)
とりいそぎ、そんな感じで。
「蛙と亀の意味は似ている」とか言い出すと「コイツいよいよアタマが...」と思われてしまうかもしれませんが、以前から似たようなことは平気で言ってきたので今更という感もあります。ま、開き直っているわけですけど。
ええと、お医者様を呼ばれる前に(マンドクセーけどシブシブ)説明しますと、ざっと以下のような理屈です。
(1) 両生類は「カエル」「イモリ/サンショウウオ」「アシナシイモリ」の三種類にわけられる。(手足の形状などについて着目すると)イモリ等がフツーの状態、アシナシイモリは退化の方向で進化(!)して、反対にカエルはジャンプや泳ぎに適する特殊強化した脚を得る方向で進化している。
(2) 同じ観点から爬虫類は「カメ」「トカゲ/ヤモリ」「ヘビ」にわけられる。同様にしてトカゲ等がフツー、ヘビがシンプル化方向での進化、カメが特殊強化方向での進化をしている。
(3) よって、両生類におけるカエルの「意味」と爬虫類におけるカメの「意味」は似ていると考えられる。両者はぞれぞれ陸に適したタイプ(ガマガエル=トード、陸ガメ=トータス)と水中に適したタイプ(非ガマガエル=フロッグ、海ガメ=タートル)を持つ点からもそのようにみなせる。
どうなんですかね。「構造」という概念にあてはまる例をあげろと言われると、まっさきに思い浮かぶのがこういう話で、「意味」というのもこういうふうに私は捉えています。
両生類と爬虫類を三種類に機能分化させて、つまり構造として捉えて類似性をみるのと同じやり方は哺乳類や鳥類や魚類にはたぶん通用しません。というか、無理に強弁してみてもあまりにも説得力がないでしょう。
それよりは全然別のジャンル、たとえば「ゲッターロボ」の分類にあてはめた方がうまくいくかもしれません。ゲッター3がカメ、ゲッター1がトカゲ、ゲッター2がヘビ、とかとか。他には三人組アイドルにおける「でぶ/ふつう/やせ」みたいな感じだとか。いや、もうちょっと一般的かつ穏当な言い方で「とろい/ふつう/するどい」とかかな。
で、こういう「構造」理解に対して「はぁ?(威嚇)」とキレる人もいます。そういう人は大抵「構造とはツリー構造の略称だ(=ツリー構造だけが構造である)」みたいな考えをもっているんですよね。ツリー構造は階層構造ともいいますけど。
ツリー構造は一見すると樹木みたいな形に描かれるのでよくわからんかもしれませんが、あれの実体はマトリョーシカ(ただし途中で複数に分割される)です。つまり入れ子構造なんですよ。rootに対してより近い(上位)概念が、より遠い(下位)概念を包含するという関係で成り立っています。
この場合「意味」に該当するのは下位語(=Hyponym)に対する上位語(=Hypernym)です。「アシナシイモリ」だったら「両生類」がそれにあたります。「両生類」の上位語は「脊椎動物」で、これが「意味」になります。「脊椎動物」の上位は「脊索動物」ですね。WordNet がこういう考え方でつくられている辞書(?)として有名かと思います(WordNet は階層構造を前提とすることで生じる問題を割と力技でなんとかしようとしていてアレでもあるんですが...)。
私はこうした考えにはなじめません。関係が hyper であるか hypo であるかに執拗にこだわる動機がよく理解できないのです。しかしこういう感想を持つ人間は少数派なのでしょう。
印欧語の祖語を求めるという古くからのテーマではツリー構造=系統樹は当然の前提とされてきましたし、最近でもこの種の研究はより科学的な装いをしつつ継続されています。
>> A Turkish origin for Indo-European languages
Genes and words have several similarities, and language evolution has conventionally been mapped using a "family tree" format. Gray and Atkinson theorized that the evolution of words was similar to the evolution of species, and that the 'cognate' of words --- how closely their sounds and meanings are related to one another --- could be modelled like DNA sequences and used to measure how languages evolved.
この記事の末尾に批判的意見のようなものも出ていますが、それはあくまで「クルガン仮説」がこの研究結果によって否定されるわけではない、というものであって前提となっている遺伝子と語の類似やツリー構造そのものに異議をとなえたものはありません。
また生成文法を信奉している人々もツリー構造として言語を捉えて構文解析を行なっており、まるでツリー構造とその相似形(つまり包含関係だけ)で世界が構築されているかのようです。
ところでウロボロス(uroboros)というのは自分のシッポを飲み込んでいる蛇の図みたいなものですが、いったい何が面白いのか以前は全然わかりませんでした。ですが上でみたような(たぶん主流派の)ツリー構造的な世界理解に対しては、一種のカウンターにはなっていて、そこに価値を見出す人もそれなりに昔からいたのかもしれません。
完全な地図(=世界のミニチュア)を作ろうとするとそのミニチュア自身のミニチュアも作らなければならなくなり云々...たしかエーコの小説にあったネタだと思うのですが、そういうものを面白く感じる人がいるのも包含関係に対して強いコダワリがあるからなんじゃないでしょうか。
軍隊や企業の組織図をみてもツリー構造になっていますし、計算機OSのファイル構造もそういえば基本的には階層構造ですね。確かにツリー構造は遍在しています。
ただ計算機OSのファイル管理についてはちょっと違う部分もあります。たとえばエイリアスを使ってウロボロス的にしてしまうことも可能です。アタマと名付けたフォルダの中にシッポというフォルダを入れ、その中にアタマのエイリアスを入れておけば、シッポの下位にも上位にもアタマがあることになって無限ループのように(擬似的にですが)できます。
「関係は確かにあるがどちらが上位であるか下位であるかはわからない」という関係を想定するのは私にとっては全く難しくなく極普通のことなのですが、ひどく抵抗を感じる人もいるようです。実際私の考えはそういう人々からは「わけがわからない」とか「けしからん」とか言われます。一応自称じゃなくて世間的にちゃんとした学者と認められているような人々にもそういわれたりするので疲れます。ほんと疲れました。
もう少しマシな人だと、ツリー構造だけじゃなくてネット構造も存在することは認めてくれたりします。上下ではなく、結び目と結び目が紐で繋がっているような関係といいますか。
この網が球を覆うような形だったり、ドーナツを包むような形で閉じていれば、一種のウロボロス(?)構造にはなるのかもしれません。言語研究について当てはめると、意味ネットワーク(semantic network)のある種のものはこれに該当するかもしれませんが、単なるツリー構造の変種として使われることも多いので一概には言えないのですけれど。
最初の「蛙と亀は意味が似ている」話に戻ります。爬虫類におけるカメ、両生類におけるカエルは他に対して同じような位置にあり、その観点からは似ているという主張をしました。同じ「構造」観からゲッターロボにおけるゲッター3やPerfumeにおけるかしゆかもそうではないか、と述べました(注:一部言ってない内容が含まれてます)。
いかにも非科学的で適当かつ根拠のないことを述べたように見えますし、実際そうなんですが(←!)言語における意味というのはもともとそういうもんなんじゃないでしょうか。不安定で、いかようにも関係を見出せるような。
上で言及した意味ネットワークのツリー構造っぽくないやつでさえ、ノード間の関係を固定したものとして捉えます(そうでないのもあるかもしれませんが私は知りません)。でもノード数が多くなると単純に距離で関係の近さを(2〜3次元図ではうまく配置できずに)表せなくなるので線の太さで示したりするようですが、たぶんそれでもあまり収まりよくはいってないっぽい気が。
うまくいえんのですが、特に「意味」についての関係構造というのはハッキリと固定されて一意に決まる形では提示され得ないものであって、そうした点を考慮しないとダメなんじゃないかな、と思えてならないのです。
なんつーか、昔「超漢字」というOSがあって「すべての文字を使用可能に!」みたいなことを唱えていたのですが、実際に取り組んでみたところ、そもそも「すべての文字」ってどうやって規定すんの...という段階で坐礁していたような(参照:『超漢字超解説』)。異体字なのかデザインの違いなのか、それとも一見同じようだけど別の意味や機能を持っているのか...はそう簡単には判断がつかないし、誰がみても一様に同じ判断をするとも限らないものだったりするわけです。(今でもある...のかな?→『超漢字V sp1』)
何にも知らないと何でも簡単に出来るとおもっちゃうんですけどね。ま、そういう姿勢も大事だみたいなことは寺田寅彦先生の随筆にもあったようなのでアレなんですけど。
そんな漢字、いや感じで。
気づいている人はかなり少ないのではないかと思うのですが何やら異変が起きているようです。私がそれに気づいたのは自作のスクリプトが挙動不審になったからだったりするわけですが。
>> 天気予報
ここでYahoo! 天気のRSSから抽出したデータを加工して使っているのですけど、8月アタマくらいから不規則な誤作動が出始めました。単にYahoo!でRSSに載せる情報の書式を変えたのが原因ならば常に表示が崩れるはずなので、滅茶苦茶になっているかと思えばマトモに機能しているときもある、というのは奇妙です。
そして一度しか目にしていませんが「該当する地点はありません」「この地域は削除・変更された可能性があります。御迷惑をおかけいたしますが、再設定していただくか別の地点をお選びくださいますようお願い申し上げます」云々などというメッセージが表示されていたこともありました。
原因究明が面倒くさそう...という気配はあったものの、このまま放置しておくのもアレなので(約一名の利用者様から苦情がきた&観察してても自然治癒しそうにない:笑)嫌々調査したところ割と簡単に対処できました。細々した話(←私のスクリプトの問題点とか:汗)を省いて説明すると、どうもYahoo!が配信するRSSデータに時折LFじゃない改行コードが混じってきてたようなのです。(追記:もしくは途中に全く改行コードを入れないデータを配信していたのかも...)
所謂テキストデータの改行コードには「ラインフィード LF」と「キャリッジリターン CR」の二種類があって、普通UNIX系OSではLFが使われています。Windowsとかはたぶん今でも両方使ってるんですよね? よく知りませんが。
そもそもなんで改行コードが複数存在する上に、どちらか一方じゃなくて組み合わせて使うようなアホ(←!)までいるのかワケワカラン。実際のタイプライターでは確かにLFとCRは似て非なる改行的動作として両方存在しますし存在する意味ももちろんあるのですが、それを計算機上で模倣するというのは全く無意味です。そもそも模倣になってませんし。ま、こんなところで吠えても仕方ないのですけど。
えー、で、要するに今回の怪現象は基本的にはたぶんこういうことです。
(1) 8月からデータ入力担当者に変化があった
(2) 時々以前と改行作法が違うデータをつくる
(3) オレちゃんCGIはLFのみ前提だったのでエラー
このCGIを作ってから1年くらいは問題なく動いていたので、今月から担当者が変わったか、こまけえことは気にしないヒトが混じったんじゃないかと推察できます。「該当する地点はありません」メッセージについてはYahoo!のRSS配信用スクリプトさえもがエラー起こすような何かをこの人がやっちまったんじゃないのかなあ...という気がしてなりません。それが何かまではわかりませんけどね。
これも面倒かつ億劫で避けてたのですがもうどうにもならんので、一日がかりでレイアウト設定に取り組んだものの、結局「行間という語を二種類の意味で使うような人々の要請には応えられまへんのでムリポ」という結論に達しただけでした。
うっかりこの話を人に言うと「文書のレイアウト設定ごときに一日がかりなだけでも呆れるのにそれでダメって一体...」と顔が曇るのですが、言い訳するとほぼ「悪いのはオレじゃない世の中だ」的な言動に受け取られてしまうので黙ってた方がマシだったりします。なんだかなあ...。
地味にショックを受けました。Wikipedia から引用します。
He was well-known for having unconventional ideas which helped to advance the young field of corpus linguistics. At his valedictory lecture in 2000 he stated that none of his many published articles passed successfully through peer review, and that even an article he had been invited to write for a journal was peer reviewed by mistake and rejected.
「none of his many published articles passed successfully through peer review」というのは事実なんでしょうか。それとも私の英語力が低すぎて何か勘違いしている?
たとえば collocation について考察した60年代とかの論文がよくわからん(←英語圏ですらない?)とこのよくわからん出版物に載ってたりして「なんで?」とは思った記憶はあるのですが。
で、何が「ショック」かといいますと Sinclair の主張しているようなことはどちらかと言えば「手堅い」とか「ひよってる(←?)」という印象だったので、それすらそんな扱いだったなんて...ぷるぷる、という点です。
ええと、ボンヤリとした記憶と理解で書いてるフワフワした話なのですが、一昨年あたりに女流王将を負かすなどの活躍をした将棋ソフト「あから2010」は複数の思考エンジン(「激指」「GPS将棋」「Bonanza」「YSS」の4種類のソフト)が合議して手を決めるという特徴を持っているのだとか。この場合の「合議」は「多数決合議法」とされているのですが、実際の指し手では必ずしも多数決でのみ決定していたわけでもないようです。「合議マネージャ」というのがキモだったんですかね。
人間同士の「合議」でもそうなのですが、同程度に優れた思考力(と理解と真剣さ)を持ったもの同士による多数決は、普通にイメージするような多数派が少数派を無視する形式的なものにはなりません。ある判断においてひとりだけ違った奇妙に聞こえる意見を出したときでも単に少数意見として却下するのではなく、それを他の(たまたまそれを思い付けなかった)3人が再検討してその結果翻意することも有り得るのです。
レベルが違う同士で合議するのは単に時間の無駄(というよりも精神力の浪費)になっちゃうんですけどね...。ってところで peer review の話に繋がるのですが、もともとこれって同レベル同士での合議のためにあるんじゃないんですかね?と言いたい。
何事も「かくあるべき」という具合にはいかないんでしょうけど。
そうそう Sinclair で思い出したのですが Sinclair ZX81 をWebブラウザ上で体験できるページがありました。
>> Timex/Sinclair 1000 Emulation in a Browser Window
あんまり懐かしくて思わずプログラムを作りそうになりましたが自重しておきます。あと Sinclair という名前は結構多いみたいですね。良く知りませんがビートルズだかジョンレノンだかの曲で「ジョン・シンクレア」とかいうのがあるとかないとか(たぶんある:笑?)。
そんな感じで。
Longman の『Dictionary of Contemporary English』には(私のは第2版でエライ古いので今のと違うかもしれませんが)collocation についてまるまる1ページを使って解説しています。
A collocation is a grouping of words which "naturally" go together through common usage. Unlike idioms, their meaning can usually be understood from the individual words. In order to speak natural English, you need to be familiar with collocations. You need to know, for example, that you say "a heavy smoker" because heavy (NOT big) collocates with smoker, and that you say "free of charge" because free of collocates with charge (NOT cost, payment, etc.). If you do not choose the right collocation, you will probably be understood but you will not sound natural. (p.193)
傍線は引用者がつけました。強調されていた部分は色を変えています。
Oxfordの辞書は「学習者用」と明記してある辞書しか持っていないのできちんとした比較はできないのですが Longman の方が usage に焦点をあてた辞書作りをしている気配は感じます。Randolph Quirk が編集に絡んでいる点からもそーなんかなーという。
なので collocation とかについて扱うのも usage に関するものの一貫としてなんでしょう。もうかなり大昔になりますが、私がコーパス言語学について学び始めたころにはよく Quirk の名前をみかけたような気がします。とはいえ、この名前を目にする度に「金儲けの秘訣」でおなじみの例のフェレンギ人の姿が思い浮かんでいたわけですが(名前の綴りは Quark なのでちょっと違いますけど)。
さて話を戻します。二つめの傍線部にあるように collocation は idiom ほど拘束力は強くないし、もとの語の意味がそのまま残っているもののことを指しているんですね。上で引用した中では heavy smoker というコロケーションが自然であって、big smoker は聞き手に何がいいたいのか理解はされるだろうが不自然に聞こえてしまうというようなことが書いてあります。free of charge が普通の言い方で、free of payment や free of cost は変であると。最初の傍線部のように「自然さ」が規準みたいです。なんとも学習者には辛い規準ですが(笑?)。
・・・と、ここまで書いて気づいたのですが Oxford の『Advanced Learner's Dictionary』でも1ページ割いて解説してますね。それどころか『Collocations Dictionary For Students of English』なんつーのも出してたのか。むぐぐ。手元の『Wordpower Dictionary』(初版)には解説どころか項目さえなかったので軽視してるんだと思い込んでました(汗)。(補足:「Wordpower」も collocation という語は載せていないものの、Study Pages の中に Words that go together という見開き2ページのコーナーを設けて同様の概念について説明しています)
なんか話がいったりきたりしててアレなんですけども、Longman では collocate と collocation 項目で共通の例を提示しています。
"Strong" collocates with "coffee" but "powerful" does not. The words "strong" and "coffee" collocate.
"Strong coffee" is a typical collocation in English but "powerful coffee" is not.
日本語でいう濃いコーヒーは strong coffee であって powerful coffee ではないし、deep coffee でも dense coffee でも thick coffee でもダメということです。BNC で見ても strong coffee はありますが powerful coffee はありませんでした。
ググってみると powerful coffee grinders ならありました。これは coffee 用の powerful grinder (強力なモーター内蔵?)という意味で、濃いコーヒーを作るための grinder じゃないですね。
「The Most Powerful Coffee In The World xp」というブログ記事を見つけたので「おお!」っと思ったのですが、コーヒー豆の製品名(?)が「BARAK-Ooob-MAMA」なので(某国大統領の名前と似ていることから)powerful だということみたいです。
あとは...間違って power coffee でググるとこんなページ↓がありました。
>> Power Coffee
ページタイトルが Pwoer Coffee と表示されてて不安になる上に全体がヘブライ語で書かれているので読み難いですが(←!) 「世界でめっちゃうれとる」「シアリスやバイアグラの代用品になるで」「めっちゃよう効くで(けど副作用はないから心配すんな!)」「処方箋もいらへん(手間いらずや!)」「めだたんようにして送ったる」「女に飲ますんとちゃうで男が飲むんや」と怪しさ満載な宣伝文句が(苦笑&ノスタルジー)。
コロケーションについて和書では『例題で学ぶ 英語コロケーション』が割と最新かつ広範囲に目配せがされていて参考になります。この本でコロケーションの定義について書かれていた中にこういう部分がありました。
意味の不透明性と固定した語順という点では dark night(暗い夜)という表現は kick the bucket とは異なります。dark night における dark と night は一緒に使われることが多いという点では強い共起関係をもっていますが、その意味は dark(暗い)と night(夜)の語の意味を反映しています。また、dark は black に代えることもできますし、the night was dark. とすることもできます。したがって、kick the bucket の方が dark night よりも語と語の結びつきは強いと言うことができます。(p.16)
傍線は引用者がつけました。
kick the bucket はこの手の話が出るとやたら引用されるんですけど、意味が意味だけにやな感じです。字義通りの意味は「バケツを蹴っ飛ばす」なので、この句が意味することと全然違っていて題材になりやすいのはわかるのですが。
それで、こっちは慣用句なので kick the pail だとか the bucket was kicked とか kick the big bucket とはいえないのだそうです。英語だとそうなんですかね。日本語というか私の個人的な言語感覚かもしれませんが「井の中の蛙(大海を知らず)」を「胃の中のオカズ(大腸を知らず)」と言い換えるのとか大好きなんですけども(←そういう問題か?)。あ、省略形じゃない場合は(世間「知らず」と)「知らず」が被ってしまってるから例として適切じゃないか。全く語が被らないというと「油を売る」とかかな? 確かにこういうのは言い換えできませんね。
それはさておき、この本では上記の例で出て来た dark night が Firth の例示したものであるということは特に断わってなかったように思います。傍線部だけを見れば Longman の解説と一緒ですが、そのあとに dark を black に代えても問題はないとあります。つまり更に拘束が弱まっているのです。Firth が扱おうとしたコロケーションというのはこのレベルというかタイプのコロケーションなので、確かに本人が言う通り扱い難いんでしょう。
結びつきが緩すぎて安定しないため、固定した形で対象テクストから抜き出すのが難しいんですね、普通のやり方だと。・・・と、ここまで書いてて思ったのですが、ホントに kick the big bucket とかって存在しないんですかね。ググったら下記のサイトがヒットしてきましたけど。
>> QRidiom
翻訳を行う際の問題の一つにイディオムの存在が挙げられる. イディオムはテキスト中に様々な形で出現するため, 翻訳者にとって未知のイディオムは大きな障害となる. 我々はまずこのイディオムを整理し,4つに分類した. その分類は(1)挿入(kick the bucket 意味:自殺する → kick the big bucket)・(2)置換(head screwed on right → head screwed on wrong)・(3)削除(not get to first base → got to first base)・(4)主題化(break the ice 意味:雰囲気を和らげる → the ice is broken)である. すでに存在する辞書を用いて翻訳者に対しこれらのイディオムの情報(訳や位置情報など)を提示出来れば翻訳作業の高速化や負担の軽減に繋がる.
むむむ...あとでじっくり勉強させてもらおう。
とりあえず、そんな感じで。
VOR(The Voice of Russia)という明らかに名前的にはVOAを意識したんじゃないかと思われるサイトに変なタイトルの記事がありました。
記事の内容は「ヤフー!取締役会は、新しい社長にグーグルのマリッサ・マイヤー副社長を指名した。17日から正式に就任する」というもので、このマイヤー氏が普通の日本語でいうなら(キモオタやオッサンではなく見た目が不快ではない)「金髪美女」だということを伝えています。特にマイヤー氏が何かやらかしたわけでもなく憎まれているとか蔑まれているということもなさそうなので「金髪女」呼ばわりは統語論(?)的には問題がなくても適切な用語選択とはいえません。
「金髪女」がどういう文脈で使われるのか「少納言」で確認してみます。
| バーでジューンなる | 金髪女 | に声を掛けられる。 |
| 金髪女 | とやった奴、喘き声は | |
| しかし、ババァに | 金髪女 | を仕込んでいる暇はない。 |
| 黒人や | 金髪女 | が絡み合った薄汚い写真 |
| 情けないセンセイだ。 | 金髪女 | のウインクにデレッとするから |
| 謎の | 金髪女 | との一夜。 |
| あわてて逃げ去る、 | 金髪女 | やチンピラ達。 |
| キックで | 金髪女 | の拳銃をはじきとばす。 |
| 実は、その | 金髪女 | というのがやり手の弁護士 |
| 片づけていく。 | 金髪女 | のエマニエルが、ハンドバッグから |
コンコーダンスから更に短く抜き出したのでよくわからなくなっています(たとえば最後の事例のエマニエルがハンドバッグから出すのが拳銃である etc...)が、「金髪女」は「金髪ふしだら女」の言い換えだったりして、犯罪や性的なもの(=攻撃や蔑みの対象)に関する文脈に限って使われています。これに対して「金髪女性」や「金髪美女」だとネガティブな感じは減るようです。用例数は「金髪女」が10で「金髪女性」が7、「金髪美女」は1だけです。(無論「金髪の美女」「金髪碧眼美女」のように「金髪」と「美女」の間に何か入る形のものを加算すれば8あります。しかし同様にして「金髪の女」「金髪の女性」なども加算すれば、それらも八倍まではいかなくても数は増えるので、ヒット数の多寡に関する順位がひっくり返ることはありません)
「少納言」は均衡コーパス(balanced corpus)ですので、母集団である現代日本語書き言葉における実際の用例数全体でも「金髪女」がもっとも多くなると推測できます。VORの(日本語母語話者ではない)書き手がこの語を(もっとも普通の言い方と考えて)選択してしまったとしてもしかたないのかもしれません。
VOAが新聞でいえば真面目な高級紙の趣きであるのに対して、どうもVORは大衆紙っぽい佇まいです。VOAの記事やNHKニュースの見出しとしてならこの見出しは根本的に直さないとダメですが、スポーツ新聞や週刊誌で「ヤフー!の社長にグーグルの金髪美女」ならありかもしれません。「ヤフー!の社長にグーグルの金髪女性」だと中途半端になって変だと私は感じます。(ちなみにVORの英語版ではGoogle's "geek queen" Marissa Mayer to head Yahoo!という見出しで、写真もドブスに写っているのを使っています。「ギークの女王」ですからね。なんだかなあ....。一応ロシア語版もチェックしたら英訳するとNew Yahoo! CEO earns $ 100 million over 5 yearsという内容の見出しで、記事本体の焦点も銭金にあるようでした。写真は日本語版と同じく奇蹟の一枚みたいなヤツが使われています。)
用語選択において何ならOKか、というのは非常に難しい問題です。統語論的なレベルの間違いでさえ、細部に入って行くと母語話者でも一致した意見にならないことがあります。ですが大枠の部分ではネイティブであれば内省によってアリ/ナシを判別できます。
これに対して学習者は内省に頼って判別することができません。学習した知識や辞書などを元に考えを巡らせて用語選択をしていくわけですが、初見の状況に対しては大抵うまくいきません。極少数の原理原則を当てはめてバシバシ適切な選択をしていけるわけではないのです。
こういう感じがなんとなくファッションのアリ/ナシに似ているなあ、と思えてきます。現代日本の一般的状況でズボンやスカートを間違って上半身に着込む人はいません。大抵の人はこのレベルでは適切な選択をします。これは内側に何を身につけるか、どういう順番で重ね着するか、性別に合っているか、上半身・下半身・頭・足といった部位には何を身につけるか、というようなことは原理原則的には決まっていて誰もが知っているからです。
なんらかの理由で正気を失った人は、おかしなことを口走り、変な格好をするとされていますが、これはクルクルパーになると言語の構造も服装の構造も把握できなくなるという形で周囲に異常が認知されるということなんじゃないでしょうか。こうなるとお巡りさんやお医者様を呼ばなければなりません。
一方、そこまではいかないけれども...という事態も目にします。パジャマらしきモノをきちんと(構造的には:笑)着用できているがコンビニで買い物をしている、というような人については正常/異常の判断に困ります。夜中であまり高級でない住宅街での出来事であればクルパーではないかもしれません。これは言語でいえばレジスター(使用域 register)に関してあまり適切でない、という話と重なります。高級紙に大衆紙のような記事が出る、みたいな感じといいますか。
このレベルを踏まえた上で更にダサイかそうでないか、という問題も出てきます。気が利いている言い回しかどうか、オシャレで素敵かどうか、等々。このレベルだと敢て下着を見せるとか男性がスカートをはくとか、ものすごくダサイ(歪んだハート型で目つきが悪いキャラクター)シャツを着ることが逆にカッコイイとかになってきます。
で、語学をやるときにどのレベルを目指すのか、という問題は当然あるんじゃないかと思うのです。とりあえず病院に行けと言われないレベルで服が着られるようになりたいのか、周囲に違和感や不審感を与えないレベルで落ち着ければいいのか、ファッションリーダーとして目立ちまくるのが目的か...。
語学とファッションの類似性について述べてきましたが、後者について日本の現代の服装の話をしていたのではよく類似点がわからないかもしれません。しかし外国の服装の話だと書いている私が皆目わからないのでアレです。
なんでしょうね、キモノの着付けとかの話にもっていけばよかったのかな? 着付け教室とかがあるくらいですから現代だと日本人でも内省でなんとかなるもんでもないのでしょう。そういう習慣があった時代からのお年寄りなら可能なんでしょうが。
未知のものを学ぶときには、まず誰かに原理原則レベルの構造を手解きしてもらわなくてはなりません。一気にすべてを理解することはできないはずですが(襟の左右どちらが外側かみたいな)基本中の基本みたいなことは割と短期で習得できそうです。
次に「なんかヘン!」と言われないため、出来るだけたくさん(着物を身につける)機会を増やし、色んな失敗もしながら他人の(着こなし)例を参照して自学自習していくことになります。これに伴って構造的なレベルについての理解も変わって(=深まって)来るでしょう。
それからイケテル/イケテナイという評価での勝負(?)レベルに入ります。独自のスタイルを築き上げる段階といいますか。
で、着付けのお師匠さんや語学教師はどう振る舞えば良いのかというと、手解きではシンプルで記憶が定着しやすい形での基本原則の提示、自学自習に関しては良い手本の見つけ方や参考にするポイントの指示、独自スタイルについては放任(!)でいいのではないかと。どの過程でも教え子が壁につきあたったりモチベーションが低下していれば解法を示唆したり鼓舞するようなネタを投入してやる必要はありますけど。
大雑把に三段階にわけましたが第二段階がもっとも重要だと思えます。つまり習得の可否は基本的には学習者の努力にかかっているということです。ですので教師の役割は自学自習でドツボに嵌っている子がそこを抜ける切っ掛けを与えることや、そもそもドツボに嵌ったりしないような予備知識を与えることのはずです。古いタイプの職人教育なんかではまさしくこんな方法だったと聞きます。
無論、特別な才能がある人物に教育を施すときは彼等の習得スピードが尋常ではないことから、そして異常に才能がない人物の場合にもドツボに嵌る頻度が尋常でないことから(目を離している暇がなく)教師が付きっきりで指導&フィードバックしなければなりません。けれど、そうでない大多数に対しては「見てるよ〜」というメッセージだけ態度で示して基本的には放任で問題はないでしょう。一人で多くを指導するならそうするしかありません。
語学教育におけるコーパスの有効性は自学自習の際に参照できる(そして信頼できる)お手本を提供できる点にあります。要するに自力でドツボを回避できる可能性が高まり自学自習の質が向上するのです。
これによって教師の負担が減って監視に注力できるため、不幸にも本格的にドツボに嵌ってしまった場合に早期発見&救助の恩恵を受ける可能性も高まります。あとイヂワルなことをいうと(全力でドツボに嵌めにくるような)ダメ教師に捕捉された場合には学習者が身を守る手助けにもなります(笑?)。
が、まあ、これもそう簡単にはいかんわけですけど。
たとえば「I was terrible」を調べてみましょうか。BNCではこんな感じです。
| " Largactil , Valium , you name it ... | I was terrible | on drugs , shouting , swearing ... " ) , of her |
| ? " I said , " Everything . " | I was terrible | , mind you . No good at all . He said , " |
| said Bob . " Very good . " " | I was terrible | , " said Dyson . " You were very good , John |
| the screen test , " commented Dustin . " | I was terrible | . I always thought I got cast in The Graduate because I |
ハミ出してますけど...(汗)。
BNCなので4例出てきましたが、規模の小さいブラウンコーパスなんかだと0件です。そんで、えーと「I was terrible」を調べたのは、これが「こわかった」を表現するときの日本人の英語学習者に共通する間違い例として『日本人に共通する英語のミス121』に載っていたからです。間違いではない表現である「I was terrified」なら68件、「I was frightened」なら72件出てきます。
用例数だけでなく共起する語、たとえば前置詞の種類なんかも異なります(terrible by は1例だけ、frightened by は126例等々)。そしてまあ、なんといっても意味が違います(笑?)。上記コンコーダンスからわかるのは「I was terrible」が「こわかった」ではなく「ひど(く悪)かった」という意味で使われているということです。
ついでに google で検索もしてみます。
>> 'The Dictator' star Anna Faris: 'I was terrible with tanning'
The Dictator star Anna Faris has confessed that she used to be "terrible" at keeping her skin safe from the sun.(中略)When BellaSugar asked Faris if she ever "practised safe sunning", she answered: "No, I was terrible about it for years! I used to lay out all of the time and I would go to the tanning booth.
大御所スター(?)Anna Faris さんがかつては日焼けを全然気にしていない「ひどい(=すごく無頓着な)」態度だったということを話した...とかなんとか。日焼けをこわがっていたわけじゃなくて全く逆の態度だったのですね。
なんか中途半端ですが、とりあえずそんな感じで。
色々とやりかけで放置していたことを「いまはどうなってんだべ?」と確認しながら総ざらいしてます。クラスター分析と判別分析の関係がちょっと気になりつつ、統計ばっかりやってるわけにもいかないので違う方面も。
で、「コロケーション」についてなんですけど、知らないうちにすっかりメジャーな用語になってます。「コーパス」もそうでしたがNHKの影響力はまだまだ侮れません。「100語でスタート!英会話」と、その後継の「コーパス100!で英会話」という番組の貢献がかなりあったみたいです。
これらの番組では対象とした語のコロケーションをコーパスを使って調べる、ということをしていたのだとか。見てないのでわかんない(←!)んですが、例えばイディオムみたいな従来からある概念との違いについて説明はあったんでしょうか。
英語教育界でいうイディオム=英熟語という概念がそもそも...みたいな話も見かけますし、敢て全く触れなかったのかな? それなりに伝統もあり紆余曲折だらけの英語教育史では蓄積した怨念(笑?)や歪みの量も半端ではないでしょうから、ややこしそうな案件についてはスッパリ知らんぷりして直接関わらない方がいいのかも知れません。
とかいって私自身がそもそも英語教育史を全然知りませんし。ただそっち業界から日本語教育に(我が物顔で)流入している勢力が使う手法のアレコレなどはそれなりに把握しています。あと『文体』で紹介されてる漢文訓読手法を英語読解にも用いた『スウィントン氏第弐リーダー独案内』をみて明治の人達は色々妙な(そして無駄な:汗)工夫してたんだなあ、と感心した経験とか。
それ以外では『日本人と英語』という本で明治あたりから最近までの英語教育史について概観しましたけど、なんだかダイエット産業界に似てるなあ、という感想です。なんでそう思ったのかはアレなんで書きませんが。それと、この本には「語用論」という言葉がほとんど(←ゼロではなかったような...)出て来なかったのが気になりました。たぶんわざと無視したんでしょう。なんつーか、いがみ合ってないで協力すればいいのになあ...と思ったり。言語政策と関わったりして政治が入って来るからか、どよよんとしてやな感じ。
「教育」が入っていない単なる「英語史」だと、たとえば『ベーシック 英語史』なんかの読後感はサイコーにサワヤカなんですけどね。「英語って無節操かつ成り行きまかせの誤用だらけで整合性皆無じゃん!だからあんなモザイク状グッチャグチャ言語になってたんだ!!フツーに理屈で考えてたら納得できねーはずだよ!!!」みたいに(悟りを開いて?)スッキリします。
逆にいうと英語史の知識がなくても違和感も抵抗もなくツルツル習得出来た人は「Philosophers on the Moon」の「月面は無重力だ」というTAの話にさえ同意できるタイプの人間に違いありません(確信)。ちなみに一部分を抜き出すとこんな話↓です。
Think. Think. Aha! "You saw the APOLLO astronauts walking around on the Moon, didn't you?" I countered, "why didn't they float away?" "Because they were wearing heavy boots," he responded, as if this made perfect sense.
こちら↑に日本版(?)の類似話と合わせて紹介されています。御参照ください。全く元ネタとなる実話が存在しない純度100パーセントの空想による作り話であって欲しいです。
さて、話を戻します。世間一般でのコロケーションという用語の使われ方を観察してみると「よくいっしょに使われる語はコロケーション!」くらいのザックリした感じでした。この定義ならチャンク、熟語、慣用句、フレーズ、イディオム、句動詞、etc...概念が重複してようがなんだろうが、なんでも取り込んでしまえますね。
ところで「コロケーション」が、そもそも最初はどういう意味の語だったのかを知る為にOEDを引いてみます。こんな風↓に書いてありました。
c. Linguistics. The habitual juxtaposition or association, in the sentences of a language, of a particular word with other particular words; a group of words so associated.
Introduced by J. R. Firth as a technical term in modern Linguistics, but not fully separable from examples in sense 1 a nor from other uses as exemplified in quot. 1940.
言語学の用語としては Firth が1940年に使ったのが初出だとされています。テクスト内での語の常習的な並置や結びつきのことだと言っているようですが、シソーラス的な類語のことも含んでいるっぽいです。A と B 及び C と Bがそれぞれ共出現する傾向があるなら A と C は共出現してなくても B を媒介にして関連しているとは考えられますもんね。
あと「sense 1 a」では(言語的なものに限らず)並置や配列一般のことだと説明していて、その最後で「Frequently applied to the arrangement of words in a sentence, of sounds, etc.」と述べています。
『コーパス語彙意味論』では Firth の概念を弟子の Sinclair が継承しつつ、拡張語彙意味単位として「コロケーション」「連辞的結合」「優先的意味選択」「談話的韻律」という4種類を提唱したことが紹介されています。
コロケーションは、中心語と共起語の組み合わせであり、語と語の間の統語的関係を無視した純粋に語彙的な関係である。これは確率論的なもので、方向性はない。(p.85)
例によって句読点は変更しました。「共起」というのも案外ややこしい概念なのですが、ここでイメージされているのは Weblio のメニューにある「共起表現」でいわれる「共起」の意味でしょう。
Sinclair は『コウビルド英英辞典』の生みの親で、コウビルドはコーパス(Bank of English)を使ったコロケーションの利用で作られた辞書として知られています。
コウビルド(COBUILD) の生みの親はバーミンガム大学のコーパス言語学のパイオニア、ジョン・シンクレア(John Siinclair)氏で、2007年3月に亡くなりました。享年73歳。1960年代末からコンピューターを活用した語彙、および談話分析におけるコーパス研究を始め、のちに出版社コリンズとの共同作業であるCOBUILD辞書の開発を手がけました。(>> 英語学習のヒント)
そうそう5年前ですね、亡くなったのは。Firth の弟子筋の人ではこの Sinclair が計算機の利用という方面で参考になりますし、テクスト論的な方面では Halliday の研究もあります。後者は「コロケーションw w w わけわからんw w」みたいなことも書いてたようですけど。
何らかの点で特徴的に互いに結びつく語彙項目の共起から生じる結束性を表す総称語にすぎない(this is simply a cover term for the cohesion that results from the co-occurrence of lexical items that are in some way or other typically associated with one another)(p.378)
引用は『テクストはどのように構成されるか 言語の結束性』から。カッコ内は原著『Cohesion in English』の該当箇所です。コロケーションに関する Halliday の見方が述べられています。「共起」から形成される「結束性」に関するものだとしてますね。
おそらく Firth が提唱したコロケーションに近いのは Sinclair のではなくて Halliday のものの方だと思います。前者は語学研究に関する非常に効果的なツールを提供しているので影響力が強いというか、多くの人が参加してどんどん有用なものが開発されていっていてそれはそれですごく良いことなのですが、もともとの Firth の狙いとは別のものを作り上げた感じです。
語彙の結束性、特にコロケーションによる結束性がテクストに及ぼす効果は、微妙なもので評価しにくい。文法的結束性の場合は、その効果は比較的明白である。(The effect of lexical, especially collocational, cohesion on a text is subtle and difficult to estimate. With grammatical cohesion the effect is relatively clear.)(p.379)
Firth や Halliday 的なコロケーション概念がなぜ普及しないのかは上記引用部分に表れています。つまり「よくわからんw w w」というわけです。
・・・と、そんな感じで途中ですが、ではでは。
ググってたらみつけました。
いろんなことを知っていて情報は多いんですけど、オリジナリテイはないし。この貸してくれたコアー・ボキャブラリーの論文だって、スタッブズに寄りかかっていて、ああしたらいい、こうしたらいい、と言っているけど、実際語彙表を作ろうとすると、彼の提案のかなりのものは実行できないんですよ。わたしは学習基本語4000語の語彙表を作ったことがあるんですけど、彼はそういう仕事をしたことがあるのかしら。それから、友達がカーターの間違いを見つけて手紙を二度も出したのに返事がなかったと言っていたけど。また別の本でも同じ間違いをしているようですよ
>> コービルド物語
傍線は引用者がつけました。バーミンガム大学での Sinclair とその教え子たちの印象なんかについて書かれていておもしろいです。なんつーか、傍線部のようなタイプの人っていますよね。文中では「ロン・カーター」と表記されていますが、たぶん Ronald Carter のことだと思われます。記憶が定かでないので人違いかもしれませんが、昔自主ゼミみたいなのの題材がこの人の本で、内容があまりにバカバカしくて途中でキレて出席しなくなったことがあったような。(追記:確認してみたらやっぱり Carter でした。『Vocabulary: Applied Linguistic Perspectives』で、当時のは1998年版です。 core words とか nuclear vocabulary とか、そういう話が出てます。)
ええっと・・・一応通して全部読んだのですが「B列系が日本独自規格なことを御存知ない」「汚名を挽回」「ヒアリング」等々「んんんんん?」と思うところはちょっとありますね(笑?)。あと「イースト菌入りのオート麦の粉の大袋」というのは私の常識からすると考えられないというか、驚愕します。「英国のイースト菌は常温保存でも平気なのか」「そんなんでちょうどよい配合で混ざるのか」...とかとか。(推測ですがこれ、ドライイーストじゃなくてベーキングパウダー入りのオート麦なんじゃないでしょうか。ホットケーキミックスみたいな感じで。)
日経新聞にこんな記事が出ていました。書き手は「日経デジタルマーケティング 小林直樹」だそうです。
>> AKB総選挙、選抜メンバー16人中15人を的中させた「ビッグデータ予測」
「ビッグデータ予測」ってなんぞ?と思って記事を読むとこんな風に書いてありました。
そしてこれら各メンバーのデータと最終得票数との関係を解析した結果、以下の方程式を導き出した。
得票数≒ブログクチコミ件数×2.75+CM登場分数×4.47
ブログに名前が書き込まれた件数に比例して得票数が増え、CMに出演しているメンバーはそれがプラスアルファとなって上乗せされる、といった比較的シンプルな式である。ルグラン代表取締役の泉浩人氏は、「Twitterの投稿数も興味深い傾向が出ていたが、昨年より件数が数倍増えていたため、票数予測に使うには向かなかった」と語る。
むむむ?なんだか単なる「重回帰式」に見えるんですが。「ビッグデータ予測」って「重回帰分析」のことなの?
それと「以下の方程式を導き出した」という部分はこの式がどうみても「方程式」じゃないので(記事の信頼度的に)マズいような。「以下の式を正規方程式から導き出した」と泉浩人氏が言ったのを記者さんが理解できてなくて変な省略をしたのかも。
で、状況はあんまり飲み込めていないのですが、とりあえず「ルグラン」という会社がAKBナントカの人気投票結果順位の予想をやったというのは確かなようです。そしてそれを日経で取り上げたと。
>> <直近予測> データで予測する2012年第4回AKB選抜総選挙
↑この「i love data」というサイトはルグラン社が運営しているみたいです。「応援係数」と「前田票の行き先予測分」を重回帰式(?)で求めた予想得票数に加算するとかいう調整の話ぐらいでしょうか、日経の記事に無かった内容は。あ、でもコメント欄でファンに変な絡まれ方をしているのとかは微妙に面白そうですけど(笑?)。
日経の見出しには「16人中15人を的中させた」って書いてあるんですけど実際は「ベスト16に入る15人を当てた」ってことらしくて、なんかこう、アレです。とりあえず得票数について「決定係数」を求めて当てはまり具合を検証してみましょうか。
実際の結果と予想の間の相関係数を計算すると「0.9271344」です。決定係数はこれの2乗なので「0.8595783」となります。アレレ?そんなに当てはまりはよくないですね。もちろん「無相関」なんてことはありませんが。結果(x軸)と予想(y軸)の散布図はこんな感じ。
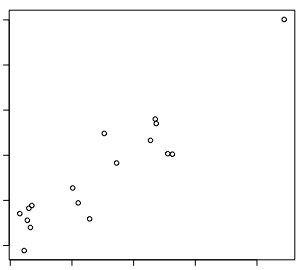
得票数だけじゃなくて順位の相関も見てみますか。スピアマンの順位相関係数を使うと「0.8504902」になります。その2乗だと「0.7233336」です。当てはまってはいますが、結構ダメなレベルじゃないのかな、コレ。
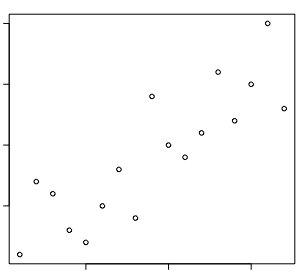
散布図を見ると確かに正の相関はあるけど「16人中15人を的中させた」という言葉のイメージとは程遠いバラけ具合ですね。ピタっと的中(決定係数=1)していたら点は一直線上に並びます。
ついでなので重回帰分析っぽいこともやってみますか。テレビ関連のリサーチ会社「エム・データ」やらインターネット視聴データ屋さんの「Web PAC」からデータを買ったりできないので、適当にお茶を濁しておくだけなんですけども。
やり方はこんな感じです。
(1) 投票結果順位の1から15位までを対象とする
(2) 説明変量にmixiとGoogle+関連データを使う
(3) 3,6,9,12,15位を標本とし、重回帰式を算出する
(4) 得票数を予想する
(1)で16位じゃなくて15位までにしたのは「梅田」のデータが日経の記事ではmixiとGoogle+に関して掲載されてなかったからです。たぶん番狂わせだったんでしょう。
ほげほげほげ...っと R でやってみたわけですが、Google+のデータは使わん方がいいという御神託が。うーむ...それだと単回帰分析になっちゃうけど...。
得票数≒mixiコミュ参加者数×1.865311+4843.232746
得票数≒mixiコミュ参加者数×1.3847493+Googleプラスファン数×0.1387462−6383.4480570
標本だけじゃなくて15人全員に当てはめてみた場合には下の式の方が誤差の総計は小さくなりました。決定係数で当てはまりを確認しますと、上の式のは相関係数が「0.7857032」で、その2乗は「0.6173294」となります。これはヤバい(笑)。下の式の結果は「0.8021741」で決定係数は「0.6434833」で、これもひどい。要するに「mixiコミュ参加者数」とか「Google+ファン数」というのは説明変量として適切じゃないってことがいえます。
重回帰分析では説明変量同士は独立であることが望ましいわけですが、その点でもこのふたつはルグラン社が使ったデータに対して劣ります。あちらはテレビとネットで別領域のデータでした。
一応散布図を書いてみました。思いっきりハデに外れているのは「篠田」のデータです。これが無ければもう少しアレだったんじゃないかとは思うのですけど、実際の結果ではブッチギリだった「大島」よりも今回設定した説明変量の値では上だったわけで、この盛大っぷりは仕方ありません。話題にはされるが投票はされない、という特異な傾向を持っているのでしょう。
「i love data」のコメント欄を読んでいたらこんなブッチャケが載っていました。
ただ、特に重回帰分析においては、予測に影響を与えると思われる要素を全てぶちこんだからといって、必ずしも精度の高いモデルができる訳ではない、という統計的な理由もあり、今回の得票数の予測にあたっては、ブログの書き込み数を採用するのが妥当と判断した経緯にあります。この点については、当初予測の本文ならびにコメントでも触れておりますので、そちらもお読み頂ければ幸いです。
「特に重回帰分析においては」って書いてますね。「ビッグデータ予測」とは何だったのか...(日経が勝手に命名しただけなのかな?)。うーむ。
また、今回の予測にあたって、消費者マインドを読み解くということを放棄している訳でもありません。申し上げたかったのは、種々の定性的な要素を「得票数を予測するための変数」としては考慮していない」ということであって、今回の実験自体は、まさに、ソーシャルメディアをはじめとする「定量的」なデータの分析から、「定性的」なAKBファンの投票行動や心理をどこまで読み解けるのか、を目的に行っておりますので、その点は、ご理解を頂ければ幸いです。
「量的」データと「質的」データという言い方ではなくて、「定量的」「定性的」という用語を使うんですね。最近チラホラみかける気がするのですが、これも quantitative と qualitative の訳語なんでしょうか。辞書をみると以前から化学ではこういう訳語を使っていたみたいですけど。
それはさておき、このルグラン社の予測は「すべての被投票者において説明変量と目的変量の関係が同じである」という前提で行なっています。「応援係数」なんかでちょっと差をつけてはいるみたいですけど、大枠ではそういう前提です。で、コメント欄でファンの人が指摘していたようですが、被投票者たちは実は一様ではなく、メディアへの出方やファンの投票行動などに関してかなり違った傾向を持つらしいのです。たとえば上で試みた例でも確かに「篠田」には、mixiコミュ参加者数などから期待される予想得票数と実際の得票数との間に顕著な(他の被投票者とは異なった)乖離がありました。
今回だけそうなのか以前からの傾向なのかは知りませんが、過去のデータ(3回分くらいはあるらしい)を分析すれば、いくつかのタイプに分類することはそんなに難しくはなく、各タイプに応じた重回帰式を作れば予測の精度も上がるんじゃないですかね。
ま、どーでもいーのでアレなんですが(←なげやりだな!←書いてる途中で心底飽きたんだよ...)。
「心底飽きた」といいながらも根が粘着質なのでちょっと追記です。ルグラン社の分析とオイラが適当にやった分析をどちらも上位15名を対象にして「実測値と予測値のズレ=残差」の「正規Q-Qプロット」を比較してみます。
まずはルグラン社の場合です。とりあえずコメント無しでオイラが適当にやったヤツのも続けて描きます。こんな感じです。
正規Q-Qプロットというのはデータの分布が正規分布かどうかをチェックするためのものです。一直線上に並べば正規分布ということになります。
パッと見た感じで他人がどう認識するのかはよくわからないのですが、オイラがやった方の左下で1個とんでもなく外れている点(「篠田」のデータ)があるのを除けば、ほとんど両者に差はないように思えます。なんというか本当に「篠田」だけが正規分布を不自然に外れている。
余りにも変じゃないかな、これ。逆にいうとルグラン社の分析でこの「篠田」の異常なズレをどうやって修正できたのか、公開されている話だけからはよくわかりません。ブログ口コミ数は(SNSも含むなら)間違いなく多いはずですから、そうなるとテレビCMとかに全然出ない人だってことでしょうか。それとも Google+ や mixi やヤフー検索数みたいなステ...げふんげふんが使えそうなところだけ特別大きな値になる人なのかな?
ま、自然科学とはほど遠い芸能界の話ですしおすし。大人の事情とかそういう感じですかね。なんだかな。
今回 R で重回帰分析をやるのにあたり久々に『工学のためのデータサイエンス入門』を繙いたわけですが...
り け い の は な し は わ け わ か ら ん
英語で読んだ方がまだわかるレベル(←いいすぎやろ!)。なんだろう根本的に物の考え方とか捉え方が違うんじゃないかしらん。少なくとも説明の順序とか優先項目とかが全く違うのは確かだといえる。悪意をもって意図的にワケワカランことを書いているような感じはないんですけどね。
...などというと「おまえがあほなだけじゃぼーけ!」とか煽られそうなので、エピソードをひとつ。
今からもう10年くらい昔になるかもしれませんが、もうちょっと最近だったかもしれません(←あやふやだな!)。研究室の共用パソコンとかで SPSS を使うのがウザかったオイラは Perl と数値計算ソフトを組み合わせて MDS の計算を自宅でやろうとアレコレ取り組んでいたのです。ですが原因不明の怪現象(?)が起きて対処に困っていたところ、親切で顔の広い大先生が理系の先生を紹介してくださって「これ幸い」と相談に行ったわけですよ。
その理系の先生も大変親切な方で「キミがやっとることはB29を竹槍で落とそうとするみたいな努力なので R や S を使うといいよ、R ならタダだし」と(私の疑問点そのものには答えずに:笑?)有益なアドバイスをくれました。
で、御礼をいって帰るときに推薦参考図書を尋ねたところ「うちの学生たちにはこれを買わせてるんだよ、いい本だよ」といって上記『工学のための...』を勧めてくださいました。当然すぐ購入したわけですが、開いてビックリ! MDS の話は一切出てません(脱力笑)。というか多変量解析への言及自体が「9.3 この本で取り上げられなかった話題」のところに数行「取り上げなかったよ」と書かれているだけです。判別分析や主成分分析にさえ全く触れられていません。なぜか回帰分析系統だけはしっかり取り上げられているんですけど。
な ん の さ ん こ う に し ろ と?
とは思いました。(補足:ある程度統計学の全体像みたいなものが認識できるようになってからだとこの本が非常に良いということは得心がいきます。回帰分析にページが割かれているのも、これについて詳しく学ぶことで多変量解析と有意性検定の間のつながりが意識できるからなんだなあ、とかとか。でも「これから勉強を始める人」向けじゃなくて「それなりにわかっちゃった人」の整理用というか、コレジャナイ感はあります。)R を紹介してもらったのは本当に有り難かったのでアレなんですけどね。そんな感じで。
非常にセンシティブな問題なので迂闊に「ある」などといえば、これはもう社会的に抹殺されかねない勢いではあります。たとえば、こんな例↓のように。
>> 日経サイエンス
ハーバード大学前学長のサマーズ(Lawrence Summers)は2005年,科学技術分野のトップに女性がいないのは男女の生まれつきの差が原因だというような発言をして辞職に追い込まれたが,そのとき引用されたのが「男性は女性よりもばらつきが大きい」という仮説だ。それによると,平均的には男女に数学的能力の差はないが,男性は能力のばらつきが大きい。つまり,男性は数学につまずく人の割合も大きいが,脳の発達の仕方か何かが原因で,数学に秀でた男性の割合も同じくらい高いという。
サマーズは経済学者だそうで、なにか統計的にそういうことがいえるみたいな話をしたようです。そして全米中の(特にインテリ層からの)凄まじい大顰蹙をかったと。
このサマーズ発言を敢て擁護した著名人としてはピンカーがあげられます。確か『思考する言語』に書いていたのを読んだような記憶が。どの巻だったかは忘れましたけれど。
ですが擁護している中で「男性の平均値は女性より高い」というようなサマーズがいってないこと(つまり根拠となる「統計的データ」が存在していない内容)を事実のように語ったりしていて、相変わらずピンカーはアレだな...(苦笑)という感じです。
ところで、このテーマは割と最近でも「男女別学の方がいいんじゃね?」問題という形で話題になっていました。
上記リンク先は『男子校という選択』という本についての考察です。孫引き(かつマルパク:汗)するとこんなこと↓が書いてあるみたいです。
桐光学園の教員は男子クラスも女子クラスも受け持っている。一九九一年に女子部が設置された当初は、男女ともに同じように教えていたという。しかし、女子クラスでの指導に違和感を覚えた一部の教員たちが、特に理数系教科に関して教え方を変えてみたところ、理解度が上がったという。 特に理数系教科に関しては、女子は細かいステップを刻みながら少しずつ難度を上げていく方法が効く。所々で「ここまでは大丈夫?」と確認しながら授業を進める。かなり力のある子でも、いったん「わからない」となると、最初のステップから振り返らなければならない。 しかし、同じことを男子のクラスでやると飽きられてしまう。男子クラスでは、いきなり「これできる?」と挑発するような方法が有効なのだそうだ。場合によっては「この問題の答えはこれなんだけど、式書ける?」と問いかけるという。全員が食いついてくるわけではないが、食いつきのいい生徒が問題を解くと、周りの生徒たちも刺激されて、手を動かし始めるのだという。桐光学園の平良一教諭によれば、「男子と女子では、ロジックのとらえ方が違うようです。『女子は理数系が苦手』といわれることがありますが、そんなことはないでしょう。理数系教科の教え方が女子用になっていないだけです」とのこと。(pp.76-77)
教育現場で実際の生徒たちをみている先生たちの実感としてこういうことがいえる、という話なので簡単に否定するわけにはいきません。また、これを肯定するような研究結果も実在するようです。そしてそれを否定する研究結果もまた存在するんだとか。どちらも統計データをもとに有意性検定などを使ってアレコレやっているみたいなんですけども。
で、こうした事柄をみるにつけ私が強く思うのは「だーからフィッシャーがいった通りだろうが!!こんなひどいことになって!!!」ということです。
ええと、例によって手を動かしてみます。今適当にググってみたら「都立西高等学校」の入試データが男女別で出ていました。これを使ってみましょう。
>> 入学者選抜データ
英数国3教科について平成19から24年度までの男女別平均点が載っています。簡単にまず6年分の平均点を(小数点以下第1位までで)計算してみると、英語では男女ともに66.7点。国語は男子55.8点と女子57.4点で女子が1.6点上回っています。ところが数学については男子59.9点に対して女子52.9点と7.0点もの差です。
なんとなく何かがいえそうな気がしてきますが、とりあえず数学の点数の男女差データのみを用いてt検定をやってみましょう。t検定は検定統計量がt分布と呼ばれる確率分布に従うということを利用したもので、標本からそれぞれが属する母集団の平均値(母平均)の差を推計して検定するのに使います。
まず「男子の点数と女子の点数は同じである」という仮説をたてて...
Welch Two Sample t-test
data: Dan and Jyo
t = 0.9728, df = 9.989, p-value = 0.3536
(中略)
> Dan
[1] 61.9 58.1 35.5 70.4 65.6 67.7
> Jyo
[1] 54.7 52.3 28.9 62.4 59.8 59.0
R で t.test() をやってみました。普通のt検定のつもりで見ると自由度(df)が 9.989 というナゾな数値でやや焦りますが、どうやら 母分散が同じかどうかわからない場合につかう 「Welch の検定」が自動選択されたせいらしいです。
ま、なにはともあれ、男子の点数と女子のそれを比較した場合の検定統計量 t=0.9728 は自由度 df=9.989 のt分布において p-value=0.3536 の位置にあるみたいです(後述しますが、この値は正確には t=0.9728 の外側の面積を2倍した値です)。p-value が 0.05 より小さくないと仮説は棄却できません。上の結果によれば 0.3536 > 0.05 なのでこの仮説は棄却出来ず、男女の数学能力の間に有意な差は認められない...という結果になります。
ちなみに母分散に差がないと考えて普通の、というかゴセットが考案したt検定を使うとこんな感じ↓です。
Two Sample t-test
data: Dan and Jyo
t = 0.9728, df = 10, p-value = 0.3536
(以下略)
df は男女それぞれ6年分(計12個)から2を引いた値の10になっています。自由度について説明するのは面倒なので、これはまあこんなもんだと思ってください。検定統計量のt値と p-value は Welch のときと同じです。作図して説明を加えるとこんな感じ↓です。
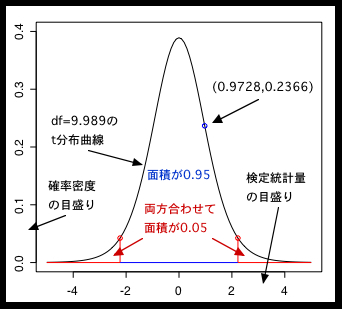
x軸が検定統計量でy軸がその確率密度を表しています。t分布曲線(←この言い方もどうかと思いますが:汗)と y=0 に囲まれた領域の面積は 1 になります。x軸の値が約2.23のところと、それを負にした値(-2.23)の外側の面積の合計は 0.05 になるので、この範囲に検定統計量が入っているとその仮説は棄却されます(滅多に起らない、ということで)。
検定統計量 t=0.9728 のときというのは上の図でいうとx座標が 0.9728 でy座標が 0.2366 の点で表せます。煩雑なのでt分布を表す数式は書きません(ガンマ関数とか出て来てワケワカラン:涙)が、それに x=0.9728 をぶっこむと出て来る値です。
あと先述したように p-value=0.3536 の半分 0.1768 を 1 から引いた値 0.8232 が x=0.9728 の左側(←!)の面積です。なので右の端っこ(←!)からは 17.68 パーセントの位置にあるということになります。つまり、この標本の男女差がこの程度に偏ることは母平均が同じでも 17.68 パーセントくらいの確率で起きるので、そんなに不思議でもないだろ?ってことです。2.5パーセント以下ならアレだけども、みたいな。
それと説明を後回しにしてきましたが、この場合に検定統計量 t はどうやって求めているのかといいますと、まず分子が男子の平均点から女子の平均点を引いた値の絶対値です。分母はそれぞれの標本数が違うときにはやや複雑になるのですが、ここでは同じ数なので、それぞれの分散の和を5(6年分マイナス1)で割って平方根を出した値となります。具体的には (59.8667-52.8500)/sqrt((134.362+125.776)/5)=0.972783...=約0.9728 という感じ。
都立西高等学校入試問題における最近6年分の点数をもとにしたt検定では「男女の数学能力に有意な差はない」という仮説は棄却されませんでした。しかし、たとえばこの6年分のデータを繰り返しコピペして11倍にしてから分析するとどうなるでしょうか。男女それぞれの平均値は変わりませんが...
Welch Two Sample t-test
data: Dan and Jyo
t = 3.5074, df = 129.859, p-value = 0.0006221
(中略)
sample estimates:
mean of x mean of y
59.86667 52.85000
p-value が 0.0006221 とものすごく小さい値になっています。当然これは 0.05 よりも小さいですから「差がない」という仮説は棄却されて「男女の数学能力に有意差がある」ことになります。差がないと考えた場合にこんな結果になるのは 0.00031105 つまり1万回に3回程度だということです。
ここまで極端にしなくても3回コピペしてデータの長さを4倍にするだけで有意差が出てきます。
Welch Two Sample t-test
data: Dan and Jyo
t = 2.0864, df = 45.95, p-value = 0.04252
(略)
p-value = 0.04252 < 0.05 なので仮説は棄却できます。分析結果が様々なのはひとつにはこういうことが原因になっているんじゃないかと推察します。標本数が小さいと有意差が出にくく、標本数が多いと差がでやすい、という傾向があって、その原因は「大数の法則」とか「中心極限定理」なんかと関係していて、まあ、説明するのも億劫(←!)なんで、そんな感じで。
そういえば母平均に差があるとか言ってたのはピンカーで、もともとのサマーズ発言では母集団の分散(母分散)が問題になっていたのでした(忘れてましたが...)。一応これもやっておきましょう。母分散の差の検定にはF検定というのを使います。t検定から類推できるようにF検定は検定統計量がF分布に従うことを利用した検定です。
「男女の分散は同じである」という帰無仮説をたてて...
F test to compare two variances
data: Dan and Jyo
F = 1.0683, num df = 5, denom df = 5, p-value = 0.944
(略)
検定統計量 F=1.0683 は p-value=0.944 > 0.05 なのでこの仮説は棄却されません。作図するとこんな感じ↓です。
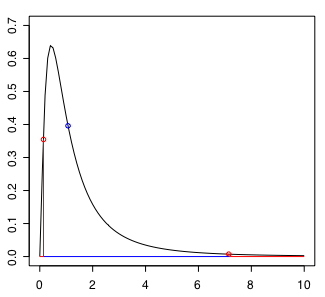
t検定のところで結構説明したのでここでは省きます。曲線とy=0で囲まれた領域全体の面積は 1 です(確率の総和は 1 にならないとおかしいので)。そして赤い線と曲線で囲まれた部分の面積が 0.05 です。ここに検定統計量が入って来ると仮説は棄却されます。
図では青丸がこの場合の検定統計量の位置ですが、右端から面積が 0.944/2=0.472 の場所です。つまりこのような結果になる可能性は(ハズレから) 47.2 パーセント(の位置...つまり真ん中へん...要するにフツウ)なので特に珍しくもなく「母分散に差はない」ということです。
試しに使った6年分の入試データからは数学能力の男女差は見出せませんでした。でも、このことによって「男女差はないのだ!」とはいえません。まず有意性検定では「差がある」ということは95パーセント程度の確かさで言えますが、「差がない」というのは原理的に主張できないのです(「検出力」というのを算出してそれを元にそういうことを言い出す人もいるようではありますが)。「差がある」の反対は「差があるとはいえない」なので、これは「あるともないともなんともいえん...」ということです。
それから母平均の差については、データ量を増やしていけば差が出やすく標本数が少なければ仮に差があったとしても有意にはならない、という傾向が指摘できました。母分散については、「個人ごとの点数」ではなく「各年度の平均点」を使ったためバラツキが均されてしまうといいますか、各性別全体の年度毎のバラつきしか検知されないので(知りたかった内容と全く違う)無意味な検定になってしまいました。
こうしたモロモロからも明らかなように、どんなデータに対しても有意性検定を使えば何かがビシバシと判明していく、というようなことはありません。万能とは程遠い手法です。それに検定統計量がt分布に従うとか、F分布に合致するとかいうのも実は「たぶんそーなんじゃね?」くらいの感じで近似値を計算しているだけなんですよね。根拠はアヤフヤなままで。
そもそも、こういう手法の始祖とされるフィッシャー卿自身があくまで実験計画に基づいてランダム化された標本を用いた対照実験において使うのでなければ有意性検定の使用は不適切だという意見だったようです。
>> 林知己夫(1986)「数量化理論のできるまで(<特集>犯罪とOR)」『経営の科学』31(12) pp.728-734
リプリントの赤本(J. ネイマンによる)を読めと言うので読んでみたが、さっぱり何のことか解らない。検定論の勉強をしてみたが「おかしなことだ」と思うのが先に立って目茶苦茶の論理ではないかとさえ思ったものである。(略)当時の私には、多くの方々が研究の中心としてやっておられる統計的検定論、標本分布論など、はだはだ空しいものと思えたのである。ミーゼスの確率論などの基礎論的考察に訓練された頭にはそう感ぜざるを得なかった。(略)ネイマンはフィッシャーの統計学の真髄をつかんでいないで、別のものを作りあげたというようにしか考えられなかった。フィッシャーのは解せないところがあるものの、科学の立場からの止むにやまれぬ論理、過去の方法よりベターな論理であるが、ネイマンのは、数学と紙の上の論理のように思えたのである。私としては必然的少数サンプルである場合の論理としてのフィッシャーの考えに共感を持ち、その当然の帰結としてネイマンの方法に嫌悪感を持ったのである。(pp.729-730)
引用するにあたって句点と読点は変えています。日本でもフィッシャーと同様の立場をとる統計学者もいたという事例としてあげてみました。この林1986には有意性検定に対しての不信が実に痛烈に述べられています。引用しきれなかった部分でも繰り返しボロクソに言っていて面白い(←!)ので是非PDFファイルをダウンロードして(7ページと短いので)お読みください(笑)。
ちなみにフィッシャーがネイマンをボロカスに言って攻撃していたこと等々の人間模様については『統計学を拓いた異才たち』が参考になります(ただ私の印象だとちょっと読んでて「?」と思う部分もあったので統計学の参考書としてはお勧めしきれないのですが...)。
で、このあとフィッシャー式の実験計画に基づくサンプリング調査をやって、有意性検定がその場合には劇的な効果をあげたことを記しています。
私は、サンプリングを実際に行なってみて、そのすばらしさに感激した。理論的に当たり前のことであるが、実際に小田原市の予備調査で厳重に500の標本をランダムスタートの等間隔抽出法でとってみたところ、これが全体の性、年齢にぴったり一致する---合いすぎの棄却に近い---のを見て驚いたのである。ランダムサンプリングをしっかりやれば、妥当な検定が可能になるということを知ったのである。(p.730)
ただ、きっちりと実験計画を練った場合でも「やっぱりダメなんだ」という結論に後に達したことで数量化理論が生み出されて行ったようです。ダメ、というのは「社会現象が解る」という点に関してですが。
サンプリング調査は「無から有を紡ぎ出す」マイダス王の杖のようなものだとの気持ちを一般の人だけでなく専門家のあいだにも感じさせるものである。サンプリング調査で、社会現象が解るという錯覚である。(pp.730-731)
つまり有意性検定が有効であるのは、確率を生成する事象空間が特定されているような特殊な場合だけであって、巷のアレコレの観測データに使って何かが判明するというようなものではない、ということなんだと思います。(ところで「マイダス王の指」じゃなくて「杖」なのは何か謂れがあるんでしょうか?当時の統計学界のスラングか何か?)
上でみてきた「数学能力の男女差」についても、もし仮にきちんと「性差」を要因として科学的に検定したいのであれば、それ以外の因子を分離する慎重な手続きが必要なはずです。農業試験場で肥料の効果の有無を調べていたときにフィッシャーが行なったような工夫をしなければなりません。つまり日照条件や土壌の豊かさの偏りなどの肥料効果以外の因子を分離する方法を考案して実験計画を練り上げたのと同様のことをしないといけないわけですが、この問題について研究したという人々はそれをやってきたんでしょうか。
もしやっていたのだとしたら、こんな風に結論が出ずにワーワーブーブー言い合ったりはしないはずなので、たぶんやってないのでしょう。と、いうかちゃんとしようとしてもそもそも不可能なのかもしれません。ショウジョウバエの行動や小麦の育成具合、工業製品の出来等々などの対象と違って、あまりにも問題が複雑です。「数学能力」に対する「性差」以外の余計な因子の影響を分離した実験計画などは(倫理的な問題を一切度外視したところで)私には到底思い付けませんし、下手をすると誰にも思い付けない可能性さえあります。
要するに有意性検定を使ってどーのこーのするようなテーマじゃない、ってことかと。同様に医学や法学の領域なんか(ヤブヘビなのでアレですが言語云々も相当滅茶苦茶だと私は思っています)で無定見のままデタラメに使われている現状に対してちゃんと声をあげていかないとダメなんじゃないかなあ、誰かエライ立場の人がそれやればいいのになあ、ほんとエライはずの人達って無責任極まりないよね〜無責任なんじゃなくて実はアレなのかもしれんけど〜こんなこと書いているとますますココロがすさんでくるからやめとくか〜でも有意性検定なんて使ったこともなさそうなひとがやたらと「有意な差が云々」とか書いてるのみるとイラっとはくるよな〜某ブログを「有意」で検索したら112件もあったし〜オレの辞書には「These are overused in such phrases as a significant improvement or significantly faster. For a change, use important, marked, considerably, appreciably, etc.」って書いてあったけどな〜ええかげんにしいや〜
えーと、唐突にここまでの話と関係あるような無いようなことを書きますが、こんな人もいるみたいです。
>> 数学という力
リンク先ではジャズピアニストの中島さち子さんにインタビューしています。なんでも高校時代に国際数学オリンピックで金メダルを取ったのだとか。大学でも数学科だったんですね。
と、長々書いてきて疲れたのでこんな感じで。
いろいろ直接関係ないことまで総ざらいしていた都合で久々に「確率分布」にも思いを巡らせてみています。これはこれで味わい深いと言うか、暇で生活にも困ってなかったらこういうのをしみじみ極めていくというのも案外面白そうかなと思わなくもない。でもそんな余裕はない(涙)。
ところで世間の見方としては「確率分布」ってどうなんでしょう?
わかっているのかいないのか。大昔に勉強会のような講習会のようなヤツに出てみた感じだと、かなり深刻なくらい「わかってない」とか「わかる気配もない」みたいな(でもナントカ検定使って論文は書けちゃうみたいな:笑?)印象でした。
「確率」の「分布」ってところがそもそもわかりにくい上に、その確率分布の母数の比の確率分布の母数の比の確率分布...なんて感じのも平気で出てきますし。理解への道は遠いなあ...とため息がでます。
そういう意味では離散型の分布などは(浅いレベルで理解するのに「解析」とか使わなくていいので)入門者向けといえるかもしれません。「ポアソン分布」や「2項分布」などがこれにあたります。というか、これよりやさしいのは無いから泣いても嗤ってもここから入門するしかないわけですね...。
交通事故、天災など、まれにしか起らない偶然の出来事は、「ポアソン分布」という特殊な確率分布の状態にしたがって起こるといわれている。(p.102)
引用は『皆殺しの數學』の「ポアソン分布の謎」からなんですが、本当に「謎」があって(←?)焦りました。そういえば著者の秋山仁先生はペンタドロン云々というので最近話題になっていたような。
それはさておき、上記引用元ではポアソン分布の例として「平成4年3月の選抜高校野球大会における逆転・勝ち越しの発生回数」をあげていました。全31試合のうち発生しなかったのが17試合、1回あったのが10、2回が3、3回が1、4回以上発生した試合はなかったのだそうです。
このときの1試合あたりの逆転・勝ち越し発生回数は (1*10+2*3+3*1)/31=約0.613 です。この数値は1試合あたりの平均発生回数とも考えられます。これをλとして次の数式を用いると発生回数xに応じた発生確率 P(X=x) がわかります。(eはネイピア数というヤツで概ね 2.71828 くらいです、念のため)
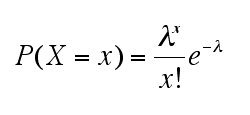
P(X=x=0) つまり P(0)=0.5483 だとか P(1)=0.3293 や P(2)=0.0988 そして P(3)=0.0197 なんてのが計算できるとしているのです。このそれぞれに31試合分ということで31をかけると、順に 17.0128, 10.2083, 3.0628, 0.6107 となり、四捨五入すると 17, 10, 3, 1 なので実際の結果にあてはまっているというのですが、どうでしょう?
理論値と実際のデータを比較してほしい。ほとんど完璧に、現実がポアソン分布の理論にしたがっていることがわかるだろう。(p.109)
たぶん「全くデタラメに起っているようなことでも数学で扱える」というイメージを伝えようという意図がメインで解説していたのかな、と推察します。この本が書かれた当時「カオス理論」だとか「複雑系」などが割合流行していたことの影響もあったのかもしれません。
でもカオス理論みたいな「決定論」を前提とした考え方は「ランダム性から完全に逃れることは絶対に誰にもできない」という確率分布の考え方とは根本的に異なっていると思うんですけどね。案外根深く誤解されているような。
ちなみに私にとっての「ポアソン分布の謎」はこの本に書いてあった P(X=x) の計算結果が悉く R でのものと微妙に違うことなんですけど、なんでそんなことが起きているんだろう。謎だ...。(Rでは順に 0.5417, 0.3321, 0.1018, 0.0208 でした)
とりあえず野球ネタではなく医療ネタ(?)でポアソン分布について引き続き考えてみます。
「透明中隔嚢胞(透明中隔腔)」が大人になっても残っている人間は100人にひとり程度と言われ、頭部の損傷等で検査を受けた折りに偶然発見される。今、酒場にいる客200人をつかまえて手当り次第にMRIに放り込んだ場合、ちょうど3人の脳にこれが発見される確率 P(X=x=3) はどうなるか。
自作の例題です。ちなみに計算結果は P(3)=約0.180 です。λはひとりあたりの発生数=発生率 p=0.01 に標本数 n=200 を掛けた値で 2 なんですが、次のケースではどうでしょうか。
クロイツフェルト・ヤコブ病(CJD)は全身の不随意運動と認知症を特徴とする中枢神経の疾患である。このうち発生原因が不明の散発性CJDは100万人にひとりの発生率である。無作為に200万人を選び出して追跡調査をした場合、ちょうど3人が罹患する確率 P(X=x=3) はどうなるか。
λが同じ 2 なので計算結果は P(3)=約0.180 です。p=0.01 の事象が標本数 n=200 の中で3回だけ起きる確率と p=0.000001 の事象が標本数 n=2000000 の中で3回だけ起きる確率というのは同じだというのですが、なんだかすごいことのような、至極当たり前のような...。
いずれにせよ計算してみるとλが 2 のときの確率分布が出ます。(λが 2 とか面倒の無い数値なら電卓でも余裕で計算できるのがポアソン分布のいいところですよね...)
0.135 0.271 0.271 0.180 0.090 0.036 0.012 0.003 0.001
0.135 0.406 0.677 0.857 0.947 0.983 0.995 0.999 1.000
適当に四捨五入してます。見てそのままですが上段が確率密度で下が累積分布。これを利用すると、たとえば5名以上が該当する確率は 0.053 だとか、1〜3名が該当する確率は 0.722 などとわかります。
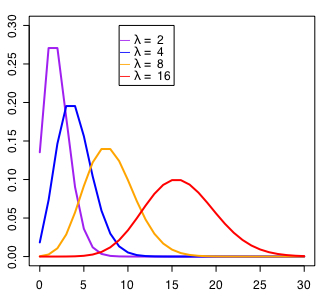
λの値を適当に変えて確率密度のグラフを作図してみました。本来ポアソン分布は離散型分布なので曲線で描くのはおかしいのですが、ヒストグラムや点だけだと見づらいことを考えての措置です。λの値によって確率分布図が変化しているのですが、こういう値のことを「母数 parameter」といいます。累積分布については下記のようになります。
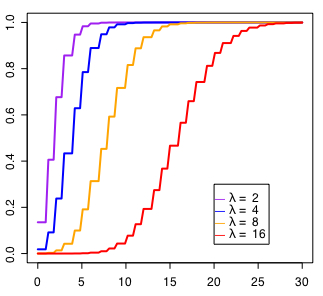
λが小さいと極端になることがわかります。つまりひどく低い確率の事象だったり少ない標本数だったりする(あるいはその両方の)ときに「全くの偶然であって何の継続性も規則性もない突発的出来事」にみえるというポアソン分布の特徴が強く表れるようです。反対にλが大きくなると正規分布に近似するのだとか。
試しにやってみると確かにそんな感じなのですが、理屈の面でよくわからないので困ります。
私の感覚では「確率分布」についての話と、マラルメが以下のように書いている内容とが同種のこととして結びついています。感覚的なものなので説明するのがちょっと難しいのですが。
たとえば私が、花!と言う。すると、私のその声がいかなる輪郭をもそこへ追放する忘却状態とは別のところで、(声を聴く各自によって)認知されるしかじかの花々とは別の何ものかとして、(現実の)あらゆる花束の中には存在しない花、気持ちのよい、観念そのものである花が、音楽的に立ち昇るのである。(p.146)
引用は『詩と散文』から。
「花」という語はあるが、この「花」が正確に指し示す何か、というものは今まで存在したことはないし、今もないし、これからもない。「花」という語は実際に使用されて何かを指し示す用をなしているけれども「花」そのものであるような何かはどこにも存在しません。
確率分布という考え方は、どんなに精緻にやってみても理論と実測値との間の「誤差」は無くならない、という事実から生まれています。この考え方を受け入れなかったりそもそも知らなかったりすると、現実に起きていることから目を背けて嘘や誤摩化しをせざるを得ないのです。
著名な科学者たちが自分たちの理論とズレたデータを誤摩化すために色々と怪しい改変をしていたらしいことは、たとえば『統計学とは何か』なんかで言及されて暴かれています。本来、確率分布に則ってバラけるはずの数値が異常にまとまりよく記録されていることから人為的に操作したことがバレてしまうんですね。だから理論や法則は結局のところそれから外れているバラバラの数値から考案され、故にそれによる予測は現実には悉く一致しません。とはいえ、それらが全くのデタラメだとか無意味だとかいうのではありませんが。
そういうもんだ、と考えるべきだと言いたいのです。かなりの客観性を持ち得る自然科学においてさえそうなのですから、言語における「意味」の研究など(というアヤシイ領域:笑)では、理論や法則はもっとずっと頼りないし役に立たないのだと知る必要があると思います。
「花」という語は「植物」という語に内包されるから「花ならば植物」という命題が成り立ち、「植物」は「花」の「意味」だといえる。こうやって関係全部を集合論や論理学を使って記述してやれば「意味」の構造をとらえることができるし、計算機処理も完璧に可能なのだ!みたいなことが前世紀には(それなりに盛んに)言われていましたが、もういいかげん目を覚ませといいたい。石を精緻に積み上げて一般家屋やピラミッドはつくれても軌道エレベーターはつくれないんです。たとえ神が邪魔をしなくても!
純粋著作は、詩人の語り手としての消滅を必然の結果として齎す。詩人は主導権を語群に、相互の不等性の衝突によって動員される語群というものに譲るのである。そして語群は、あたかも宝石を連ねたあの玉飾りの上における灯影の虚像の一条の連鎖のように、相互間の反射反映によって点火される。(p.148)
頭がラリパッパな詩人の方がずっとちゃんと物事を正確にとらえているな、と思えてなりません。畢竟するに私が統計学の知見を借りたりして色々足掻いていることも「詩論」の一種なんでしょう。ま、そんなだから受け入れられ難いんでしょうけどね。しかたがないか...。
(しかし世の中は捨てたもんじゃないようなそうでもないような。『荒地の恋』はなぜか売れてました。時々本屋で奥付をみると結構なペースで重刷がかかっていて終いには文庫化まで。この本の主人公として実名で描かれる北村太郎さんなどはまさしく「確率分布と腐れ縁な詩人」だと思うのですが、詩論や詩そのものへの言及は極力避けられていたのが良かったんですかね。ていうか、それにしても不思議:笑?)
もしかしたら説明不足でわかりにくかったかもしれないので...。
『皆殺しの數學』に出ていた「選抜高校野球」の話では、λ=0.613 は1試合あたりの逆転発生数の平均値です。だからP(0)は1試合あたり0回逆転が発生する(つまり一度も発生しない)確率のことです。なのでこれに試合数の31を掛けると31試合中で何試合逆転0の試合があるのか計算できます。
一方「透明中隔嚢胞」の例では、λ=2 は200人あたりの保持者数の平均値です。P(0)は200人あたり0人が保持している(つまり誰も保持していない)確率であって、ひとりあたり0個を保持している(保持していない)確率ではありません。P(0)=0.135 に 200 を掛けると 27 という数字になりますが、これは無意味な数値です。
ところで野球の例に合わせてλ=0.01(ひとりあたりの発生率)で計算して求めた P(0) に 200 を掛けると 198.01 という数値になります。P(1)*200 では 1.98 です。四捨五入してやると 198 と 2 になりますが、これは「保持していない人が198名、1個だけ保持している人が2名、2個以上持っている人(←!)はいない」という意味だと解釈できます。
逆に野球の例を後者に合わせるとλ=19(31試合あたりの平均逆転発生数)になります。この場合で計算すると P(0)=0 です。これは「31試合中に1回も逆転が発生しないということは有り得ない」と解釈します。確率分布は P(19) を中心としてその前後が高い確率になります。
以下、おまけのおまけ追記です...。
Rの計算結果と『皆殺しの數學』での数値との違いがやっぱり気になるので、それなりに決着をつけておこうと思います。「どちらが正しいのか?」の判定法は「第三者による検算」を採用。そんでこの場合の第三者はオイラ(←!)です。オイラーじゃなくてオイラ...げふんげふん。λ=0.613として手作業で P(0) を求めてみました。
>> 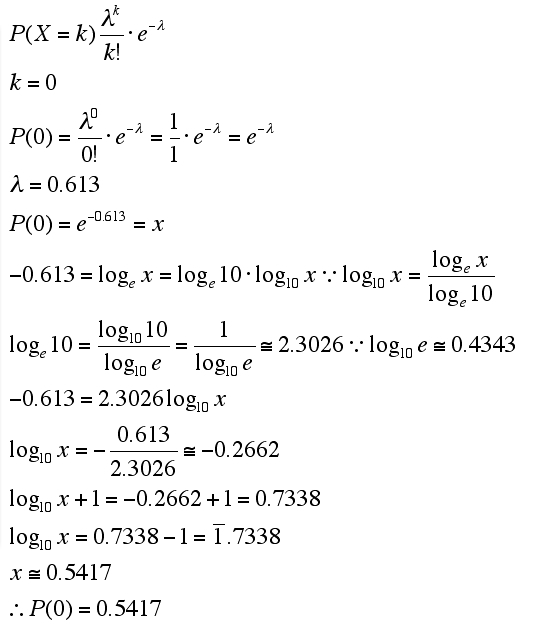
未知の値を求めるところで x を使いたかったので、ポアソン分布式の P(X=x) をここでは P(X=k) に変えました。それと、対数の計算には常用対数表を使っています。しかし21世紀に対数表...。
結果は見ての通り P(0)=0.5417 で Rの結果と一致しました。やはり R が正しかったようです。
まあ、大抵はこんな風に「どちらが正しいのか」は割と簡単にわかるんですけど、でも正しくない方がなんで正しくないことを主張したのかの原因を推察するのは骨が折れるんですよね。
>> 
「Rとオレサマの結果が同じだったから」以外の理由でも『皆殺しの數學』の数値がダメなことを示しました。P(0)とP(1)の値から推算できるλの値と、計算に使っているはずのλの値が一致していません(Rやオイラは大丈夫です:笑)。
これには「計算間違い」と「λの値が違っている」というふたつの理由が考えられますが、推算できる「0.6006」を使った場合の計算結果は本にあるのと(近いですが)異なるため、前者であろうと思われます。
なんでこんな計算間違いをしているのか?という謎は相変わらず残りますけど...。
ま、そんな感じで。
前回、前々回、更にその前と延々書いてきた話の、とりあえずの完結編です。
自説のオリジナルな部分の話をする遥か以前のところで、つまり多変量解析だのテクスト論の基礎的な考え方だのの部分で「それはおかしいなんだかわからんせつめいせんかい!せつめいされてもぜんぜんわからん!!なにいってんの!!!」的な難癖を受け続けて萎えていたと書いてきました。
ちょうど『銀のいす』の地下世界で洗脳されかけた主人公達みたいな心境(そうか...MDSとかテクスト論とかソシュールとか、もともとそんなもん世の中に存在しなかったんや...)でしたが、そこから辛うじて脱出できたのは『フーコーの穴』という本のおかげでした。なのですごく感謝してます。変なタイトルですけど(でもこのタイトルじゃなかったら手にとらなかっただろうしなあ...)。
この本では統計学と社会についての色々な話題に言及しているのですが、第7章で「プロファイリングの現在」を取り上げ、デヴィッド・カンターの研究について触れています。
次に、犯人像推定の中で最も重要な犯人の人格的特徴の分析において、カンターが取った方法を見てゆく。彼が導入したのは、犯罪行動についてのファセット理論と呼ばれる多変量解析の一種である。
彼がこの方法を考えついたのは、これまでの犯人像推定が、方法論上の難点を抱えていたからだった。これまでのプロファイリングでは、「ある犯罪における行動の説明を、犯罪の意図や動機、あるいはそこから推定される犯罪者の性格特徴の説明と結びつけて」考えてきた。(略)しかし、犯人が分かっていない時点での犯人像推定では、こうした類型論は実はあまり役に立たないのである。(略)無数のありふれたレイプ事件の中から未知の加害者の性格特徴を割り出すには、その行動、被害者への働きかけや相互行為のプロセスで何をしたかに注目する以外に手だてがないからである。(pp.202-203)
傍線は引用者がつけました。類型論的手法は悪く言えば先入観や思い込みによる決めつけでもあるわけで、うまくハマれば効率よく解決できるのでしょうが、その歪みが捜査を誤らせることもあります。「見込み捜査による失敗」というフレーズは良く耳にしますし。
これを克服する手だてとして傍線部にあるような「相互行為のプロセス」データから「有用な何か」を読み取る方法を紹介しています。
この考え方はまさしくテキストマイニングです。「行動」を扱っていることになっていますが、捜査資料は自然言語で書かれているわけですから、そこに記された「相互行為のプロセス」は何らかの仕方で言語化されています。ですので、ここから「関連性データ」を拾い出して「視覚化」したときに明らかになるのは第一義的には「行動を表すことば同士の関係」なのです。
引用部分にはカンターが使う手法は「ファセット理論」だとされていました。で、大変申し訳ないのですがこの「ファセット理論」というのは正直よくわかりません(←!!)。カンターの分析手続きを見て行くと以下のように進めています。
(1)66件のレイプ犯罪事例の調書から33種類の犯罪行動(ex. 口実を使って接近、不意打ち、電撃的攻撃、目隠し、緊縛、さるぐつわ...)を抽出。
(2)犯罪事例と犯罪行動でバイナリデータ(ある/なし)のクロス集計表(66×33行列)をつくる。
(3)個々の犯罪事例中で同じ値(00又は11)がついている犯罪行動は類似しているとみなして類似度(相関度?)を加算する
(4)犯罪行動について類似度を値とする対称なクロス集計表(33×33行列)をつくる
(5)類似度数をランク付けして一番数値の大きいのを1とし、以下順に類似度を順位に置き換えていく。
(6)非計量多次元尺度構成法(NMDS)を使ってデータを視覚化。
(7)散布図を線でいくつかに分割してクラスタリングし、各クラスタにラベル(ex. 暴力性、非人間性...)をつける。
ええと、たぶん(7)のところが facet (面?)みたいだということでファセット理論なんだと思います。おそらく普通にクラスター分析とかでクラスタリングして、散布図への書き込みのときにそういう感じにしてるんじゃないかと推察します。プレゼン用の工夫でしょうか?
あと(3)は違っているかもしれません(←違ってました:汗。この段階ではJaccard係数を使っていたみたいです。後にGuttman-Lingoes係数というのを使うようになって、そっちをSSAと呼んでこっちはSSA-Iとしたらしいです。ザクと旧ザクみたいなもんですかね。ま、でもメンドクサイので直しません←オイ!)。『フーコーの穴』の説明は今ひとつ要領を得ないものだったので、こちらで勝手に一般的な非対称データ表を対称データ表にする方法に従ってみました。と、いうのも恐らくこの本の著者は多変量解析については明るくないと思われたからです。
彼の創意は、三三の要素すべてについて、残りの三二要素との間の相関を調べ上げ、しかもそれを、二次元の図の中に表現するというアイディアにある。この方法は行動マトリックスの最小空間分析 Smallest Space Analysis(SSA)と呼ばれる。(p.204)
なんかモジモジします(たぶん私が書いていることも詳しい人から見たらモジモジするような内容だとは思うのですけど)。「そ、それはカンターのオリジナルではないですよね?」といいたい。犯罪捜査に応用したのは彼の創意かもしれませんけど。
なにはともあれ(5)のように類似度を順位に置き換えるところが「最小空間分析」というアルゴリズムの特徴なんでしょう。よくわかりませんが。
素人目でみて思い付くこの方法の利点としては「類似度を非類似度に変換できること」と「類似度の偏りをイイカンジに調節できること」あたりがあります。前者は見てそのままですが、後者についてはそうですね、ちょっと手を動かしてみますか。
非対称データではないのですが、前回使ったバイナリデータの表Aを再利用します。
これを数え上げデータ表に変換します。
値は「2、3、4、5、6、9」で類似度です。順位値に置き換えると以下のようになります。
値は「0、1、9、21、25、29」で非類似度です。NMDSを使って作図した結果はどちらも似たようなもので大差はありません。上が数え上げデータの場合、下がSSAモドキの場合です。
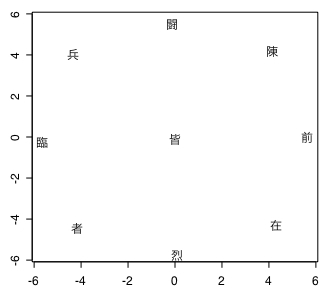
見た目は同じようであっても当てはまりの度合いを示す数値である stress は大きく違いました。SSAモドキの方が凡そ0.00(←!)なのに対して、数え上げデータの場合はメチャクチャ高い数値になっています(0.05以下が望ましく、高いと当てはまりが悪い)。後者についてはあまりにも異常な値なので何か私が間違った操作をしているのかもしれません。とりあえず前者でよい数値が出ていることにだけ注目したいと思います。
詳しいことはよくわかりませんが、感覚的に見ても上のケースでは同順があればその分次の値との差はひらくわけですからSSAモドキの数値の方が当てはめやすくは見えます。また、大きなデータを使って類似度が極端にバラける場合には、逆に数値の差を縮めてまとまりやすくする方向で作用しそうです。
カンターの行なった多変量解析を使った犯罪プロファイリングは、彼がリヴァプール大学の先生だったことから「リヴァプール式」と呼ばれています。ファセット理論を使った研究成果の初出は1990年ですので、80年代に色々実践していったものなのでしょう。
日本の警察もこの方式には取り組んでいて、近年では「科学捜査で痴漢常習犯を捕まえた!」的なニュースが小さく報道されたり、捜査関係者が記した一般書もいくつか出ています。
本格的な導入は2000年に道警本部刑事部科学捜査研究所が特異犯罪情報分析室を設けたのが最初らしく、同年にカンターの来日もあったのだとか。
なのですが、日本の警察ではSSAもファセット云々も採用しなかったみたいです。面倒ですもんね(笑)。
非対称のバイナリデータを分析するわけですからコレスポンデンス分析(CA)が手っ取り早いと考えるのが普通の判断でしょう。大抵の統計解析ソフトでも対応していますし。そうした事情(?)のせいか『プロファイリングとは何か』にはこんな風に書いてあります。
本章第3節「リバプール方式のプロファイリング」の図2-3-1「強姦犯の犯行テーマ」の分析(81頁)が数量化III類と類似の方法による分析である。(p.88)
あかんやん...「利用される統計手法は、ファセット理論に基づくものであり、最小空間分析(SSA-I)などの非計量多次元尺度構成法を使用する。(p.80)」て自分らで書いてるやん...MDSは数量化IV類やんか...。
この本で紹介されている日本人による研究事例はすべて数量化III類のCAを用いたものですし、2章5節「プロファイリングの実践例(pp.106-115)」ではカンターの分析法をなぞりつつ「SSA→CA」「ファセット→クラスター分析」に置き換えていましたので、そう書きたくなる気持ちもわかりますけど。
でもカンターは敢て面倒でもNMDSを使ったのかもしれないわけで、そこのところにはもう少し注意を払ってもいいんじゃないかと思わなくもありません。同じデータをもとにSSAとCAで比較してみれば色々わかってくる気がしますが、誰もやってないんでしょうか?(←CAよりSSAが良いとかいう結果が出ても誰も得しませんもんね...)
こまけえ話をしても仕方がないので分析法のアレコレについてはとりあえず忘れます(←笑?)。
ええと、何に使ってもMDSの結果を読む方法は大筋では同じです。中心に没個性な項目が集まったクラスタが1個、それ以外に共通の特徴を持った項目が固まってできる複数のクラスタが配置されます。その各クラスタが何を意味しているのか解釈して、それからなんでそうなったのかを考えます。
上でとりあげた66の犯罪事例と33の犯罪行為についての分析例では中央クラスタが(不意打ち、無反応、非人間的言葉、衣服を乱す、膣内挿入、凶器)の6犯罪行為項目から形成されます。これはレイプ犯罪において犯罪者のタイプに関係なく大抵共通して行なわれる行為を表します。
複数のクラスタのうち「暴力性」とラベルをつけられたものは(侮辱の言葉、支配のための暴力、支配のため以外の暴力、言葉の暴力)から成ります。「非人間性」だと(電撃攻撃、衣服を破る、面識を示唆)などです。時計回りで「性愛性」「暴力性」「非人間性」「犯罪性」「親密性」となっています。これらはレイプ犯がこの犯罪を通して何を一番重要視するタイプかということを表していると考えるようです。主たる動機が5種類あるということですね。
レイプを暴力を振るう手段だと考えている犯人は「支配/抑圧のための暴力」と「支配/抑圧のため以外の暴力」を両方振るうという酷さに加えて罵声を浴びせたり傷つける言葉を吐いたりしますが、これは一応相手のことを人間だとは思っているわけです。わざわざ攻撃や暴力の対象に人間を選ぶのは、それでしか得られない何かが彼等にはあるのでしょう。
一方、「非人間性」カテゴリの犯人は、相手を自分と同じような人間ではないものとして扱うことを主たる動機とするということです。たぶんサド/マゾでいうところのサディストに近いんじゃないでしょうか。「暴力性」カテゴリの方はDV夫みたいなタイプをイメージするといいのかもしれません。似て非なるものなんですね。
これらの区分は100パーセント正しいというものではもちろんありませんが、漠然とした「レイプ犯」イメージについて「とらえどころ」のようなものを提供してくれます。見方を変えると「レイプ犯について記述されたテクストの内容分析」だとも言えます。そして、この方法がこの件について有効であったなら別のテクストに対して適用しても同じ程度には有効であろう、と期待できます。
実際に、窃盗犯、放火犯、ストーカー犯罪等々という「別テクスト」への適用はすでになされています。先述した通り痴漢常習犯に関しては分析結果を利用して実際に逮捕するところまで至っているようです。
カンターらの研究について調べていくとレイプだの殺人だのの話ばっかりなので到底心躍るものではないのですが、こうした方法が実際に犯人逮捕などの役にたち、当初は馬鹿にしていた犯罪捜査の現場の人達からも信頼を得て行っているらしい...ということには非常に勇気づけられました。
カンター自身の一般向け著作『心理捜査官ロンドン殺人ファイル』(邦題はどうかと思いますが...)で示される考え方にも非常に同意する点が多くあります。
最近出た「捜査関係者の記した一般書」では『犯罪捜査の心理学』が(少しだけですが)分析法についても具体的に触れていて良かったように思います。他の本はリヴァプール式プロファイリングを受け入れてもらう際の苦労などについてが主な内容で、読んでいると身につまされるというよりも苛ついてきます(←!)のでお勧めはしません。
なんとなく、そんな感じで。
前回、前々回と書いてきたことの続きです。「数量化III類とIV類の違いってどう考えたらいいんですかね?」という、大多数の人類にとっては割とどうでもよさげな問題について言及したところで前回は終っていました。
文系からは「数学とかキョーミないしーカンケーないしー」と心を閉ざされそうですし、理系からは「オマエw w 数学わかってねーじゃんw w w 理解できるわけないw w w」と嘲笑われそうですしおすし。
それは、まあ、その通り。
確かに「主成分分析(PCA)」「コレスポンデンス分析(CA)」「多次元尺度構成法(MDS)」の核となる部分では数学を使って次元縮約をしています。数学がわからなければこの部分は理解できません。ですが「数学がわからない」=「これらの手法は理解できない」なんでしょうか?
たとえば前々回の宮島1970は12の古典作品間の「類似度/非類似度」を値として持つ12×12の行列を作成し、それを12×2の行列へと数理的に変換することで2次元図へのプロットが可能となりました。数学によって12の古典作品間の関係性を「視覚化」したといえます。
前回の「子どもを作らない理由」アンケートの分析(Lebart et al.1998)では、語の出現数を値として持つ14×5の行列を作って、それを14×2と5×2のふたつの行列に分割変換して2次元図へプロットしています。それによって色々な関係性をひとめで見られるようになりました。
けれど、このふたつの事例を純粋に数理的視点からのみ考えれば、どちらも単に要素の多い行列を(出来るだけ情報を減らさないようにして)少ない行列に変換したのだ、というだけのことです。それぞれの行(rows)や列(columns)が何を意味しているとか、要素の数値が何を意味しているとか、何を反映しているとか、そういうこととは全く関係ありません。
データに含まれていた「関係性」が「視覚化」されたわけですが、その結果を解釈して何か「意味」を見出したとしたら、それは数学とは直接関係のない分析者の感性や知識や推理によるのです。
宮島1970なら「どうも書き手が女性かどうか(かな文学か漢文訓読文体か)が分布の仕方に影響している感じがするぞ」「韻文か散文か、というのも重要にみえる」「そういえば更級日記は源氏物語に言及するのがすごく早かったとか聞いたな」...云々。Lebart et al. 1998なら「個人的な要因と社会的な要因」「学校教育へのコミットメントの程度」等々に関して色々考えさせられるなあ...とかとか。こういったものは数理的にどうこうではないのです。
PCAやCAやMDSという手法は「関連性データの視覚化」をしますが、数理部分はブラックボックス状態であっても十分使用可能だと思います。どういうデータを与えると適切な結果を返してくるのかは、使っているうちにわかってくるはずです。そういう付き合い方で試行錯誤していけばいいんじゃないでしょうか。もともと理論的にどうこう、じゃなくて実践で鍛えられてきた(robustな)手法ですし、それでそれなりの信頼も得ているわけですから。
私の興味は、この「関連性データの視覚化」手法を「テクスト論」に応用することにあります。実用性実効性の面で実績のある手法の助けを借りて、アヤフヤな論をシャキッとした見掛けにしよう(=カタギに見える格好をして胡散臭さを薄めて広く受け入れてもらおう)という試みだったのですが、よもやこれほどの攻撃誘発性を発揮するとは...(涙)。
どうやら「胡散臭いけどマジメ」じゃなくて「胡散臭いうえに不気味」と見えるみたいです。確かにチンピラがマジメな格好をしていたら逆に怪しさが増しますもんね...。
でも泣いてばかりいてもしかたがないので、「関連性データの視覚化」をできるだけわかりやすく簡単に説明する方法を引き続き考えてみます。
とりあえず理論的な説明みたいなものは苦手なので手を動かしてみます。まず、こんなの↓を用意して...

タイルを3×3に並べて、そこに「臨兵闘者皆陳烈在前」という九字を書いたものがある、とみなしてください。これから近接性というか隣接性というか、そういうデータを取って2種類のクロス集計表をつくります。ひとつはバイナリ(0か1)データで、ふたつめは実数測定値データでつくります。
前者は各文字タイル自身とそれに上下左右1枚分隣接している範囲のものは「1」、それ以外は「0」を入れて表にします。たとえば「臨」行(row)だったら「C7(臨)」「C8(兵)」「C4(者)」列(columns)とクロスするマスに「1」を入れ、他は「0」です。これを表Aとします。
後者については、自身のタイルを「0」、隣り合うタイルの中心同士の距離を「1」とし、斜め下なら「2の平方根」みたいに実際に測定できる距離データをクロス集計表に入れていきます。こちらを表Bとします。

まず数量化III類チーム(?)のCAで表Aを処理して作図します。
回転したり裏返ってたりするのは気にしません。文字の位置関係はかなり正確に再現できています。次はPCAでの作図。
大体再現できていますが、ちょっと膨らんだ感じになっています。
引き続いて数量化IV類チームの出番なのですが、その前にひとこと。MDSには実は大きく分けて「計量(古典的)MDS」と「非計量MDS」があります。以下前者をCMDS、後者をNMDSと区別して呼びます。CMDSは分析対象の数値が「ユークリッド距離」的性質を持つデータでなければならないので、表Aはまともに分析できそうにありませんが、とりあえずやってみます。
メチャクチャですね。NMDSではどうでしょう。こういう場合でも分析できるように開発されたものなので、なんとかなりそうではあるのですが。
CAとPCAの中間ぐらいな感じでしょうか。表Aに関しては数量化IV類チームの負けですね。
同じ様に表Bに関してもみていきます。CAによる作図。
素人目には表Bの方が情報量は多そうに見えるのですが、表Aのときより精度が落ちてしまいました。PCAでもやってみます。
表Aのときより再現度が上がっています。では数量化IV類はどうでしょう。CMDSの結果。
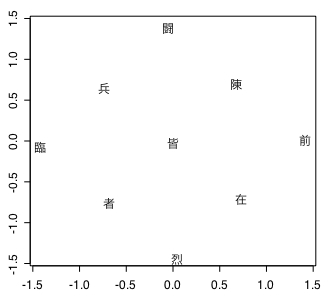
正確です。次にNMDS。
同じく正確ですね。表BについてはMDS陣営の勝利です。あとCMDSの名誉(?)のために付け加えておくと、表Aの「0」と「1」は「類似度」なので反転させて「非類似度」にして表A2を作って分析させると、以下のようになります。
あまり正確ではありませんが、メチャクチャではなくなりました。
非常に単純なことからいうと、数量化III類の方がIV類よりも扱えるデータの範囲が広いということがわかります。一般にIII類で扱うのは列名と行名が異なる非対称なデータ構造のクロス集計表であり、IV類は列名と行名が同じで対称なものであるとされています。ですが、III類は別に対称データでも問題はないようです。
これに対してIV類ではCMDSが表Aのようなバイナリデータに対してそのままでは分析不能になるなどの制限もあります。PCAとCMDSは同じ程度に古い時代に成立した分析法ですが、今回の比較実験からはPCAの方が対象データの適用範囲も広く分析結果の妥当性の程度などからも上位互換的手法にみえます。
一方、PCAと同じく数量化III類のCAは、バイナリデータ(binary data)にはかなり強く、実数測定値データ(real valued measurement)には弱いというPCAと逆の性質があることがわかります。Rで計算するときも後者では警告が出ていました。どうもCAはバイナリデータやLebart et al. 1998で扱ったような数え上げデータ(count data)を専ら扱うように考案された分析法のようです。
こうしてみるとPCAとCAは相補関係にあることもあり、どんなデータ型に対しても数量化III類は最良の結果が出せそうです。NMDS単体をみれば(四種の分析法の中ではもっとも新しいこともあって)トータルでは一番優秀でしたが、それでも非対称データに関してはどうにもなりません。
以上のことから比較すると、数量化IV類は扱えるデータ型に制限が多く、特にバイナリデータの扱いについては不完全であるという点で数量化III類に劣ることがわかった!数量化IV類なんていらんかったんや!!だから影がうすいんや!!!...とうっかり結論してしまいそうですが、それは違います。
MDSの観点からいうと、バイナリデータを上手く扱えていないのではなく、表Aのバイナリデータが対象となったタイルの関係性をうまく表現できていない、ということなのです。試しに敢てCMDSの分析結果について寄与率を計算してみると2軸がそれぞれ50パーセントなので合計すると100パーセントになります。
数量化IV類の特質はCMDSからNMDSが派生していくときにどのような改良が加えられたのか、をみていくとよくわかります。
NMDSではまずCMDSを計算して2次元座標を得ます。これをとりあえずの初期配置とし、このときの項目間距離を計測して、元の関連性データにある項目間距離と比較します。そして、元のデータの項目間の(距離の大小などの)関係をできるだけ再現するように2次元座標を修正していきます。この試行を延々繰り返して「まあまあかな?」という配置を得るのです。
CMDSは距離のデータから座標を推計する方法です。確か三角関数を使ったやり方とベクトルを使うのの二種類の方法で表せるところから欠損した情報を補って座標を導き出す...みたいな原理だった気がしますが、思いっきり嘘の可能性がありますので信じないでください(←!...なにせ統計ソフトに頼らない自力での計算は十年近く前にやってみただけだったので記憶が...元のデータが2次元図とかじゃない場合には算出される座標はかなりの多次元空間における座標になるので、そこから更にPCAと同様の方法で次元縮約してたような...)。いずれにせよ、座標算出原理の関係で「距離」以外の尺度は使えなかったんだと思います。使ったところでかなり不正確だったと。
NMDSはそれを上記の方法で調整して使えるようにしています。とにかく項目間の位置関係の維持にだけ注力した手法なんだということがわかります。
数量化III類の方は対象データの項目をできるだけ「分散」が大きくなるように順位付けできる軸を探してきて(大抵の場合は)そのうちふたつを使って散布図を描く手法です。ここでいう「分散」は日常語で「投資リスクは分散しないと!」みたいにいう分散ではなく統計学の用語で、項目の散らばり具合を表す値です。
100円均一の店で売っている商品を分類するのに値段を軸にしてしまっては、その尺度は全く用をなしません(分散=0)。なるべく差が出る尺度がよいわけです。
数量化III類の結果では、そうした分散が大きい尺度同士の相関が描かれることになります。このとき分析対象となる関連性データはできるだけ多様な型に対応していた方が望ましく、また個々の項目相互間の値の差にも数量化IV類のデータが持っているような意味はありません。
分析法の性能差にみえるものは目的や考え方の違いに起因していると考えるべきでしょう。
上で作ったのは3×3の極小データですが、もっと大きいものを使うと劇的な結果になる可能性がかなりあります。少なくとも表Aを5×5=25項目についての表(25×25の行列)にするだけでPCAの結果がメチャクチャに歪むことはわかっています(CAはかなりがんばります)(注:Lebart et al. 1998にPCAとCAをこの表で比較する話がでてきます)。またMDSに表Bの拡大版を処理させる場合(2次元データのままではたぶんビクともしないので)3次元方向に拡大すると、結構な歪みが発生するかもしれません。
誰かやってくんないかな。自分でやるのは色んな意味でシンドイですが、どんなもんかは知りたいので。
ではでは、そんな感じで。
こんなのどうせ誰もよまねーんだよなあ...と、ヤサグレ気分で書いた前回の記事ですが、 Twitter で好意的に取り上げてくださった方がいらっしゃったらしく(←デジタルデバイドのため気づくのがかなり遅れました:汗)思いのほか多くの人に読んでいただけたようです。赤面しつつもよろこんでいます。
ありがとう&幸あれ。
ただ、読み返してみるとアヤシゲでイイカゲンな箇所もかなりあり、補足や訂正が必要にも思えました。たとえば、以下の部分なども主観的には嘘ではありませんが「ちげーよ」という意見もありそうです。
「多次元尺度構成法(MDS)」は1930年代くらいに確立した手法ですが
これは Gale Young らの業績を指して「確立」といっているのですが、Torgerson の1950年代の業績をいう方が一般的かもしれません。また、その少しあとに書いた「非計量MDS」が生まれた年代についても「1970年代ごろ」ではなく「1960年代なかば」くらいのニュアンスじゃないと実体と乖離しすぎているきらいがあります。
それと、テキストマイニングにMDSを用いると迫害されるから気をつけなはれ...的な話をやたらシツコク書いてしまったため、当人の意図と逆の効果を及ぼしてしまったかもしれません。「最近この手法に取り組む人が増えてきたようでウレシイ!みんなもっとドンドン使って!」と言いたかったのに、「使うとひどい目にあうからヤメナハレヨシナハレ...」みたいに受け取られたんじゃないかと心配です。
これについては思わせぶりに警告するのではなく、具体的な話もしておけば「ああ、その程度か」と見極めがつく(←?)かもしれないので、私自身の経験をふたつだけ例示しておきます。どちらも5年くらい前のものです。
テクストがたまたま難しいとされているところから(しかし○○の文章が難解だとは私には思えませんが)、幼稚な分析をしたところで、それは「難しい質的領域への応用」ではなく「難しいと言われているテクストへの安易な適用」に過ぎません。
○○は分析対象としたテクストの書き手の名前が入ります。この箇所だけ改変しましたが、あとは原文ママです。
「難解」かどうかが話題になっているのは、テキストマイニング(内容分析)の対象を「読み切れないほど大量のテキストデータ」ではなく「そんなに大量ではないが読み難いとされているテキストデータ」にしていたためです。
で、注目して欲しいのはカッコ内の記述です。対象テクストが(世間一般では)「難しいとされている」ことは認めてくださっているようなのですが(そしてそれで十分なのですが)なぜか「自分にとっては難解ではない」旨付け加えています。
これを読んだときの私の気持ちをドラクエ風にいうとこう↓です。
上で引用した中に(おそらくは罵倒の意味で)「難しいと言われているテクストへの安易な適用」だとあるのですが(「安易」のニュアンスにはひっかかりますけど)まさしくそっちをやったつもりだったので非常に困惑しました。
以上の例では MDS を使った分析そのものについては直接触れていませんので、ふたつめは技術的な問題について言及した事例をあげておきます。書き手は上の人とは別です。あと両方とも私的なやりとりではなく、アカデミズムの場の公的な見解として私の研究に向けられた意見です。
Fig. 1 の2次元配置は、あくまで一回の計算で求められたものであって、一つの次元は一つの「意味」(基準? 因子?)を持っていると考えられる。Fig. 1は全体の布置を説明するのに二つの軸しか見ていないはずである。しかし、この論文では、5個のクラスターを設定した後、それぞれのクラスターが独自の性質をもっているように見て分析を進めている。これはおかしいのではないか。一つの語の位置は、他の90語との距離(非類似度)によって決められるのであって、そのクラスターの中の10語なり15語なりとの関係だけを見て決められるものではない。
この点からは、論文の後半の議論は何かずれているように思えてならない。二つの分析手法を混在させて、両方を眺めて分析するのが趣旨というなら、それは問題を複雑化させるだけであろう。MDS ではこういう結果になり、クラスター分析ではこういう結果になった、最後に両者の共通点と相違点を示すというような述べ方をするほうが望ましい。
技術的な問題についての(やや)詳しい話は後述しますが、端的にいうと「MDSと主成分分析(PCA)は違う分析法だ」「MDSの結果をクラスター分析で処理して解釈するのは普通のことだ」という事実認識の点で私の見解と相違があります。
前者についていうと、この人はたぶんMDSのつもりでPCAの話をしてます。「全体の布置を説明するのに二つの軸しか見ていない」と書きつつ「第1主成分と第2主成分...固有値が...寄与率が...」と考えていたんじゃないでしょうか。とはいうものの、この両者の区別については諸説みかけますので、まだ議論の余地はあるのかもしれません。注:MDSのアルゴリズムのうち「主座標分析(PCO)」は数理的にPCAに帰着できるそうですし
ただ後者については、現在ではそこら中で行なわれている現状があるわけですから、決定的ではないかと思います。ここでは一例だけ示しておきます。
引用は『関連性データの解析法』から。副題は「多次元尺度構成法とクラスター分析法」です。引用者が傍線をつけ句点読点は変えました。
最もよく使われる方法として、データに潜む空間構造を描き出す多次元尺度構成法(multidimensional scaling、MDS)と、かたまりの構造を抽出するクラスター分析法(cluster analysis)がある。おおまかにいえば、前者はデータから対象の位置関係を表す地図を作る方法であり、後者は対象をかたまりに分類する方法に対応する。このことから、所与の関連性データに対して2種類のアプローチが可能である。実際の応用では、これらを併用し、対象の空間的な配置図にかたまりの構造を書き込むことによって、データに潜む構造情報を明確にとらえることができる。(p.2)
当時でもこうした事例をあげて間違いの指摘をすること自体は比較的容易でしたが、それで相手を説得できるかどうかは別問題でした。たぶん今はもう少し環境がよくなっているでしょうし、研究領域で事情もかなり違うと思います。
以下、前回の続きです。
もともと「おさらい」用のメモみたいなものなのでアヤシイことも書くと思います。なるべく間違いのないようにするつもりですが、ヤッチマッタ場合はすみますみません。
というわけで、早速「コレスポンデンス分析(CA)」をやってみようと思うのですが、サンプルデータとしては『Exploring Textual Data』で使われたものを拝借します。本来ならまたパイセン(←注:先輩)たちの大昔の業績から未計算データを持って来て作図しようかと思ったのですが、体験談を書いているうちに色々思い出して気力が萎えてきてしまったので、まあ、こんな程度で。
このデータは、2000人に以下のような質問をして得られた回答から抜き出した14語と、回答者を educational level で区分した5つの項目とで14行(14 rows)5列(5 columns)のクロス集計表をつくり、語の出現回数を記入したものだそうです。
"What are the reasons that might cause a couple or a woman to hesitate having children?" Survey about aspirations and life styles of the French.(p.47 脚注3)
作図してみると以下のようになります。
>> 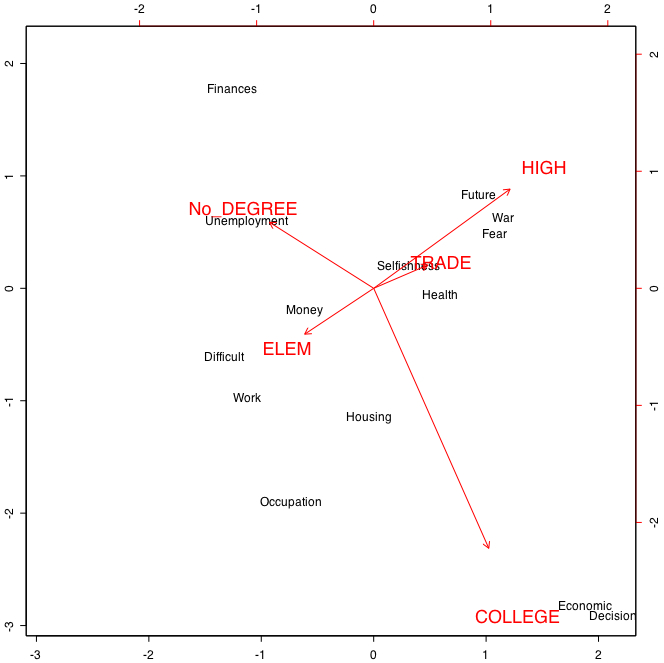
が、『Exploring Textual Data』に記載された図とは左右が反転しています。また座標の数値もかなり違っています。でもプロットされた項目の位置関係はほぼ同じです。
14語のうちわけは Selfishness が重なっていて見え難いのと、Decision の最後の n が削れている以外は図から読み取れると思います。回答者の区分は TRADE が Trade School(どうもフランスの話らしいので高校=リセが二種類あるうちの職業校的な方のことかな?)のことだとわかりにくいくらいでしょうか。No_Degree は「その他」的なものじゃないかと思います。
ざっと眺めると、たとえば TRADE と Selfishness が非常に近接していることから、Trade School の学生の回答には子どもを作らない理由をそのようにみなすのが多かった(比率が高かった)ということがわかります。また回答者区分では TRADE と HIGH は COLLEGE と比べて似たような語を回答に選択する傾向があり、両者の関係は近いということもいえます。語同士、回答者区分同士、回答者区分と語の間等々において近接性の程度で関係が推察できます。
この図とその読み方や利用法は、前回「シンプルなMDSの利用例」で例示した宮島1970と、概ね似たものに見えるかもしれません。では、違いがあるとすればどんな点なのでしょうか。
教科書的な本には大抵書いてあるように思うのですが「数量化III類」は「反応パターン分類法」です。これは「林の数量化理論」の考案者である林知己夫先生がデザイナーの佐藤敬之輔氏と缶詰会社のラベルのデザイン分析をする中で生み出されたのだとか。
複数のラベル群をたくさんの人に見せて、気に入ったものには印をつけてもらうということでデータをとると、みっつのことがわかります。
「ラベルの選び方に共通するパターンを持った人々」が出現することで人々の類似関係がわかるのがまずひとつ。それから「人々の選び方が共通するパターンを持ったラベル群」が出現することでラベル同士の類似関係がわかるというのがふたつめ。そしてこのふたつの類似関係からラベルと人々の関連(類似)もわかります。これがみっつめですね。
クロス集計表のデータを特異値分解などの数学的手段で処理して上で述べたパターンを解析するのがこの方法です。CAはこの「数量化III類」にあたります。先述のPCAもそうです。
こうした principal axes methods では元の状態をできるだけ保って次元縮約を行なう際に、各次元(軸)に対応した「固有値(λ)」を算出し、その寄与率(固有値全体の総和に占める各固有値の割合=元の状態を反映している程度)の高い2軸(=principal axes)を選びます。この手続きを経て2次元図へのプロットが行なわれるわけです。
ちなみに上でCAを試すのに使ったサンプルデータの固有値は、第1主成分と第2主成分を合わせても累積寄与率が78パーセントにしかならず、目安とされる80パーセントに届いていないため「あまりうまく元の状態を説明できていない」結果ということになります。
一方MDSは「数量化IV類」に含まれます。対象間の親近性がデータとして与えられたとき、ユークリッド空間に対象を布置する手法のことだとされています。このとき、似ているものは近くに、そうでないものは遠くに配置されます。
定義がこういう(ゆるい?)ものだとすると、数理的処理の部分では確かにPCAで使われるのと同じ方法を用いてもMDSとはいえるわけで、そのあたりでウヤムヤな感じがあるのかもしれません。
...と、ぐだぐだになってきたので、そんな感じで。
10年前には考えられなかったような事態が起きていて驚いています。たとえばこうした記事↓のような。
特定の話題(ここでは英語教育)に関する言説を集積したもの(ここではTwitterでのつぶやき)を対象にして多次元尺度構成法で分析を行なっています。「おもしろそうだったのでとりあえずやってみた」的に非常に手軽(←?)に試みているのが印象的です。感無量といってもいいくらいです。
「多次元尺度構成法(MDS)」は1930年代くらいに確立した手法ですが、計算の大変さがネックになって当時は気軽に使えるというものでもなかったようです。それが1970年代ごろに計算機がどんどん高性能になりつつ利用する際の敷居が低くなっていったこともあって、実際に活用される中で色々な工夫や改善と応用などがなされていきました。「非計量MDS」などが生まれたのもそのころだったかと思います。それでもまだまだ一部の研究者がそれなりの設備を用いて使用するもので、一般にも知られるようなものでもありませんでした。
近年ではより一層の計算機の進化や環境の変化を受け、膨大なデータの中から「有用な何か」を見つけ出してくる技術(データマイニング)の需要が組織でも個人でも非常に高まっており、データマイニングで使用できそうな技法についての一般の注目度もあがってきています。こうした流れの中で多変量解析の一種であるMDSも再評価されたり、それまでになかった用途での応用などもなされるようになってきたのでしょう。
後述しますが、それでも上で引用リンクしたタイプ(←大量のテキストデータに含まれる語彙相互の関係からテキスト全体の内容にどういう傾向があるかをMDSで推察するタイプ)の分析は少なくとも10年前には私は見かけませんでした(たぶん5年前でもなかったと思う)。使用されているツール「KHCoder」の作者である樋口耕一先生もその当時はMDSではなくコレスポンデンス分析を主に使っていたのではなかったかと記憶しています(もちろんKHCoderはコレスポンデンス分析をはじめ様々な分析法に対応していますけれど)。
ではMDSを使ったこうしたタイプの分析法が(使い易いツール=KHCoderの普及にともなって順調に)広く普及していくのだろうか?と考えるとそれほど楽観視はできないと思えます。前項でのリンク先「ツィッター上の英語教育言説の構造」でも以下のように書いてありますが、MDSは曖昧な手法で使い方が難しいのです。
というわけで、あんまり「新奇な知見!」は見られないわけですが、今回はかなり大ざっぱに分析したのでこんなものだと思います。実際のテキストデータをじっくり見ながら、丁寧に分析していけばもうすこし面白いことは言えるかも知れません。
MDSで算出した結果をどう解釈するか...というのは、ある種職人芸的なものです。計算そのものは文字通り機械的に行なわれるのですが、分析対象となるデータから何を選び、それらの「類似度/非類似度」をどう設定し、計算結果として得られた配置から何を読み取るか、という部分は分析者のセンスに強く依存しています。「実際のテキストデータをじっくり見ながら、丁寧に分析」していくという過程がどうしても必要になるのです。
「ツィッター...」の筆者はもちろんその点を理解なさっていますが、やっぱり今でも誤解している人(というか、そもそも知らないし関心がない人)の方が多いんじゃないでしょうか。
まだまだ人々の多くが統計処理に期待するのは(大昔の安直なSFなどに出て来た擬人化されたコンピュータがやるように)「とりあえず手当たりしだいにデータをぶっこんでやれば自動で機械的に(すばらしく明解で端的で期待通りの)答えがでる」ことでしかなく、そういうつもりでMDSを試みた人は「おもてたんとちがう...」とガッカリするんじゃないかと思います。
分析の設計や結果の解釈が「分析者のセンスに依存」すると指摘しましたが、幸いにも卓越したセンスで画期的な知見(「新奇な知見!」)に到達できた場合でも、実はかえって深刻な問題を生じる危険があります。つまり、その解釈を評価する人々がセンスについてきてくれないことがあるのです(←笑?)。
「評価する人々」がMDSの特性を(誤解なく)理解してくれていれば、まだなんとかなるのですが、現状ではそういうことはあまり期待できません。ありきたりの結果となりました...なら「ああ、そう」で済ませてもらえますが、新奇な知見の解釈を説明するためにはその解釈部分だけでなくMDSで作図したものの読み方の基本からレクチャーせねばならず、その段階で「わかんない」「めんどくせえ」「おまえてきとうなこといってけむにまいてるだろ」的な批難(?)を浴びて気力が萎えたりします。
こうした問題を避けるもっとも簡単確実な方法は分析の単純化じゃないかと思います。不本意ではあっても。
意欲的な研究は複雑なものになりがちですが、複雑なものは理解がされにくく、理解できない対象に対してはとりあえず攻撃しようという敵意(←理解できないものが提示されたことを、自身の面子を潰そうという攻撃とみなしての反撃なんでしょうけど:萎)の対象となり易くなります。MDSを使ったテキストマイニングは複雑な上に曖昧なので、非常に難癖がつけやすく、こうした点での危険が無視できません。
MDSに限らず統計処理全般がそうなのですが、分析結果からわかるのは「目安」や「傾向」であって何らかの「証明」につかえるレベルの正確さはもともと持ち得ません。全くのデタラメからなるべく遠くなるように結果をだそうとするものであって、物理法則のような正確さが期待されるものではないのですが、そのあたりの認識に混乱があるようにも思えます。
古い時代(1970年代ごろ)における自然言語(文章)へのMDSの利用は、主に文献相互の類似性を比較するもの(文体分析)でした。この分析は上で引用した「ツイッター上の英語教育言説の構造」と比較すると結果についてはかなりシンプルです。
このシンプルな方法で「ツイッター上の...」と同じデータを使って分析するなら、図にプロットされるのは語ではなく、つぶやきをした個々の Twitter アカウントになり、アカウント同士の「類似度/非類似度」は tweet に含まれる語彙の状態によって算出されます。
この結果何が得られるかというと「英語教育についてつぶやく人々のうち、誰と誰が似かよった傾向のつぶやきをしているか」という相関図です。
ここでの「似かよった傾向」は語彙の出現傾向の話なので、たとえば「日本」「大学入試」「TOEFL」という語彙が共通するために近接してプロットされたアカウント同士であっても、意見そのものは逆であるかもしれません。つまり「日本の大学入試をTOEFLにしろ!」というのと「日本の大学入試をTOEFLにするなんて!」という意見のアカウントは「似かよった傾向」とされるのです。そんなのオカシイ!と難癖をつける人はたぶんいるでしょうけど(萎)。
具体的なこのタイプの実例としては、たとえば宮島1970などがあります。
宮島達夫(1970)「語いの類似度」『國語學』82 pp.42-64
われわれは、たとえば紫式部日記のことばは徒然草よりも源氏物語にちかい、と感じる。その理由はいくつもあるだろうが、その1つに、源氏と紫とでつかわれている語いが似ている、ということがあるはずだ。ここでは、このような語いの類似度をはかる方法と、その方法をいくつかの古典にあてはめてしらべた結果と、ほかの分野への応用とについてのべたいと思う。
ここでいう「語いの類似度」は各作品に含まれる語彙(語の全体)同士の類似度のことです。まずは二つの作品の(語彙の)類似度を単純に「それぞれの作品の見出し語数の和から共通の見出し語数を引いたものを分母とし、共通の見出し語数を分子とする係数で表す」としたところ、期待と違う結果が出たことを受け、その理由を考察し(たとえば類似度が主に作品の長さの影響を受けている等々)常識的な人間の感覚と近い結果がでるように調整していく過程を記述しています。ある種の科学観を持った人は、こういう点を「非科学的だ!」「恣意的だ!デタラメだ!」と怒るかもしれません。
試行錯誤を経て最終的には以下の係数を考案して使用していました。
>> 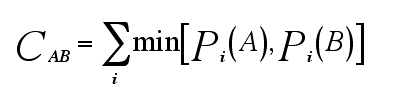
作品AとBの(語彙の)類似度は各語のAでの使用率とBでの使用率のうち少ない方の使用率の総和によって表される、ということになります。しかしこれであっても決定的とはいえず「より精密な結果をえるためにも、方法の特徴や適用範囲をみさだめるためにも、まだいろんなことがのこされている」としています。
さて、この係数を使った「万葉集や源氏物語、枕草子といった12の古典作品の分析」なのですが、当時(42年前!!)はまだMDSの計算ができる環境は日本には無かったのか、この論文独自の工夫による風変わりな作図が行なわれていました(←なので実は宮島1970はMDS風であってMDSではありません:汗)。折角ですので現代の計算環境でこれを作図し直してみます。
>> 
中心クラスタは土左日記、伊勢物語、更級日記によって構成されていて、これら(具体的には更級への言及のみでしたが)は宮島1970の分析でも「比較的どの作品にもあらわれるような平凡なことばでかかれている」作品ということになっていました。
これに対して周縁に分布するものたちはそれぞれ「独特の用語をもっている」ということが言えます。そして同一クラスタに含まれる作品群には共通する特徴がある、つまり似かよっているということになり、似ている度合いは近さで表されます。たとえば右端にある文字が判読不能なほど重なっているクラスタなどは「独特かつ互いに共通性の高い用語が使用されている作品群」なわけです。
ですが、非常に見づらいので階層クラスター分析の結果得られるデンドログラム(樹状図)も作成してみます。
>> 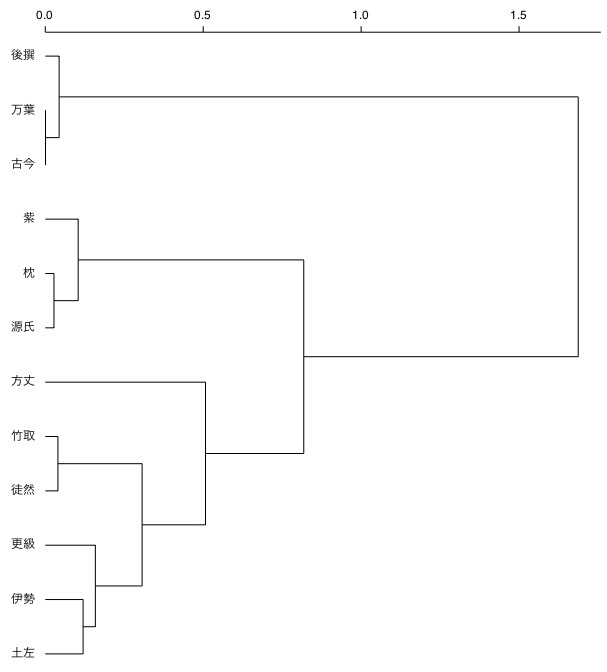
このクラスタに属しているのは万葉集、古今集、後撰集で三つとも歌集です。宮島1970では古今集と後撰集が非常に似かよっていることは指摘されていましたが、2次元に縮約したときに万葉集と古今集がほぼ同じ位置で重なり合うほど近接することには気づいていなかったようです(←類似度の数値を見ただけでは、異常感覚をもった数学の天才でない限りこの関係に気づくことは不可能だったと思われます)。
今ここで細かい話をしても仕方がないのでザッと述べますが、宮島1970で試作されたデンドログラムでは先述した中心クラスタの作品群をクラスタとしてとらえ損なっていたり等々、色々な違いも見られるものの、大枠での分析は上で示したMDSの計算結果と比較して妥当なものだったと言えそうです。つまり12の古典作品群はそれぞれ独特の用語を持った(万葉集、古今集、後撰集)(紫式部日記、源氏物語、枕草子)(方丈記)(竹取物語、徒然草)という4つの周縁クラスタと、そうした作品群に共通する語彙のみが主に使用されていて独自色の薄い(土左日記、伊勢物語、更級日記)という1つの中心クラスタで構成されている、あるいは分類できる、とみなせます。
あとは個々のクラスタに属する作品群それぞれに共通する特徴を具体的に考察して、その特徴を特定できれば分析できたことになるはずです。「あとは」と付けたしのように言いましたが、実はこちらの方が肝要ですね。宮島1970でも以下のように指摘されています。
さて、文体分析を考えるばあいには、以上にえられたような類似度は結論ではなくて出発点または手がかりにすぎない。A作品とB作品との類似度というのは、それだけではほとんど無内容な数値であって、いろんな原因による似かよいの度あいを「要するに」という形で1つにしぼったものだ。だから、それらの原因を分析し、なぜそのような値が出てくるのかを追求しなければならない。
と、いうわけですが原因の追求は省略させてください(←笑?)。
最終的な作図に至るまではかなり複雑な考察を経ていても、結果として提示されるものや考察しなければならない問題の範囲などはシンプルに決まっているのでMDSを理解しない人にもこのタイプの分析は比較的受け入れてもらいやすいのではないでしょうか。これをTwitter アカウントの例に適用すれば、各アカウントが属するクラスタがそれぞれどういう共通属性を持った集団で構成されているのかをプロフィールなどを参照して推察することで、英語教育にかんするアジェンダ選択における傾向と社会属性の関係が何かわかるかもしれません。それによって「わかった」ことは比較的シンプルに論述可能なように思えます。
ここまで見て来たもの(「テキストマイニングへのMDSの利用」と「作品分類へのMDSの利用」)に対して「コレスポンデンス分析(対応分析)」は中間、あるいは(分析の用途としては)折衷的な手法といえそうです。
...なのですが、コレスポンデンス分析や最小空間分析(SSA)の話など、続きはまたあとで(←!)。
とか、そんな感じで。
そういえばそうだ...と、今更気づきました。
大体結婚を決意するあたりのタイミングで「無欲かっ!」とツッコミたくなるくらいに私物をきれいさっぱり処分したり何にも欲しがらなくなる人々がいたんですけど、あのとき「おとな」になってたんだなあ、と思ったりします。そしてそういう人々は(いい意味で←?)ちゃんと出世してます。案外世間も見る目あるんだなあ...などとヒトゴトみたいに言っている場合でもないようなあるような。
映画『エル・トポ』でも「男は7歳になったらオモチャと母親(の写真)を捨てろ!」みたいな話があったような気がするのですが、ウロ覚えなので嘘かもしれません。ちなみにホドロフスキーといえば『サンタ・サングレ』に「(すごく変だけど)完璧やないかっ!」と猛烈な感動をさせられましたが、今見たらどうなんだろう。全然違う受け取り方をするかもしれない気も。
どれどれ、ちょっくら確認してみっか、ビデオどこに仕舞ったっけ...とかやっているといつまでたっても片付かんわけです(汗)。時間はどんどんなくなるし。
先月末くらいからアクセスしにくくなっていて「?」でした。Amazon.com の方は問題なかったのですが Amazon.co.jp だと妙な感じに繋がらなかったりしたのです。
詳しいことはわからないのですが、原因はルータでした。正確には Amazon.co.jp のサーバの状態が変わり(IPアドレスの末尾が0に?)それに伴ってルータが接続先をアレコレするフィルタリング(偽装IPで末尾0が多いという理由で弾いている?)で問題が生じた、ということのようです。ちなみに現時点の Amazon.co.jp は「176.32.121.0」です。
>> 諸悪の根源は物理的
IPアドレスの末尾が0 (xxx.yyy.zzz.0) になっていると、USPSのサイトでアクセス拒否をしている。これはセキュリティ対策で、80%の偽装IPアドレスの末尾が0だからだ。(略)しかし、いくらなんでも0を全て弾くとは…なんとも大雑把で乱暴なセキュリティ対策だこと。これもお役所臭さと言うのだろうか。USPS はとっくに民営化されてるけど。
USPSっていうのはアメリカの郵便局みたいなヤツだそうです。そこを見ようとするとアクセス拒否される、と。探ってみると「0 in the end of their 'false' IP address 80% of the time」というのが公式見解で出てたみたいです。アメリカ人の雑イズムこわい。
同じような(方向は反対だけど)雑なことをBuffalo(←日本企業ですよね?)製ルータもやってたのかな?まあ、ファームウェアを更新したら直ったのでヨシとしますか。
ちょっと思うところもあって久々にレイモンドの論文を読み返してみました。
>> 「ノウアスフィアの開墾」
昔読んだときにはあんまり自分にとって切実な問題ではなかったせいか内容もほとんど覚えていなかったのですが、今読むと「おお!」となります。とはいえ、あくまで自分の興味というか問題意識に引きつけての勝手な読みをしてそう感じているってだけですけど。
詳しいことは上記リンク先を読んでもらうとして、簡単に三箇所だけに言及しておきます。まずは所有に関する「ロック」理論というものについて。これがハッカー文化における所有概念と似ているというのです。
この理論はハッカーの慣習と同じように、中央権力が弱いか存在しないような場面で有機的に発達してきた。それは千年以上もかけて、ノルウェイやドイツの部族法から発展してきたものだ。それを近代の初期に体系化して合理化したのがイギリスの政治哲学者ジョン・ロックだったので、これはよく所有物の「ロック」理論と呼ばれる。
論理的によく似た理論は、ある物件が経済的または生存上で高い価値を持っていて、しかも稀少財の配分について、中央集権的に強制するだけの力を持った単一の権威が存在しないところでは必ず生じるようだ。これは、ときどきロマンチックに「所有」の概念がないと考えられたりもする狩猟採集文化でも成り立つ。たとえば Kgalagadi (カラハリ) 砂漠のクンサン・ブッシュマンの伝統では、狩猟場には所有権は存在しない。でも、井戸や泉については所有権が存在して、その理論は明らかにロックの理論と似ている。
クンサン・ブッシュマンの例は示唆的だろう。というのも、これはロック式の所有権慣習が、その資源からの期待リターンがそれを独占して守る期待コストよりも大きい場合にのみ生じることを示してくれるからだ。狩猟場が所有権の対象にならないのは、狩猟のリターンがすごく予想しにくくて変動しやすく、さらに(すごく高く評価はされるけれど)日々の生存にとって絶対的に必要なものではないからだ。一方の井戸は、生存にとって不可欠だし、守りきれるくらい小さい。
この論文の題名に出てくる「ノウアスフィア(noosphere)」というのはアイデア(観念)の領域であり、あらゆる可能な思考の空間だ。ハッカーの所有権慣習に暗黙に含まれているのは、ノウアスフィアの部分集合の一つであるすべてのプログラムを包含する空間での、所有権に関するロック理論なんだ。だからこの論文は「ノウアスフィアの開墾」と名付けた。新しいオープンソース・プロジェクトの創始者がみんなやっているのがそれだからだ。
オープンソース・プロジェクトは必ず誰かに「所有」されているという話だったかと思います。オープンソースウェアの開発に関しては色々な人間が自由に関わることができるけれどもグチャグチャになったりしないのは、それが誰かに所有されており、その誰かが正しく判断をしながらコントロールしているためだ、とかなんとかいう前提があって、そうした所有者がどうやってハッカーコミュニティの中で認定されていくのか、ということに言及しています。
ロック的な構造は、オープンソースのハッカーたちがその慣習をまもるのは、なにか自分たちの努力からの、一種の期待収益を守ろうとしているからだろうと強く示唆している。この収益は、プロジェクト開墾の努力や「所有権の連鎖」を記録したバージョン履歴を維持するコスト、そして捨て子になったプロジェクトを占拠するまでに公的な通達を出してしばらく待つという時間コストよりもずっと大きなものでなくてはならない。
さらに、オープンソースからの「収益」は単なるソフトの利用価値以上のものでなきゃならない。プロジェクトの分裂によってダメになったり減ったりしてしまうようなものでなければ。もし利用価値だけが問題なら、分裂に対するタブーはないし、オープンソースの所有権も土地所有権とは似てもにつかないはずだ。事実、既存のオープンソース・ライセンスから導かれるのは、こういう(利用価値だけが唯一の収益となる)別世界だ。
いくつか候補としてあがる収益はすぐに却下できる。ネット接続上では有効な脅しがかけられないので、権力追求はまったく成り立たない。同じく、オープンソース文化はお金や内的な稀少性経済に類するものは持っていないから、ハッカーたちも物質的な富とあまり似たものを追求していることはあり得ない。
傍線は引用者がつけました。ロック的所有権の慣習をハッカーが守っているからには「一種の期待収益」が想定されているだろうことを指摘しています。論者はそれが「(贈与文化社会における)評判」であって、一般的に想定されるような「(希少性のあるものを溜め込む的な)物質的な富」とは違うだろうと言っています。
また、少しあとの部分ではこうした「評判」の獲得を動機とするモデルで理解する方が(ハッカーには受け入れられ易い)「職人気質」を動機とする説よりも適切だろうと結論付けました。両方(「同業者の中での名誉という報酬とハッキングの喜び」)とも動機なんじゃないか?などという話も出ていたようですが、なんだか腑に落ちたような落ちないような変な感じ。この論が書かれた当時の議論でも「期待収益が何か」については皆が納得したということでもなかったようです。
「ハッキングの喜び」とか「職人気質」というのをどう捉えるか(あらかじめ評判ゲームは仕込まれている、とかそうじゃないとかとか)で話も変わってくるように思うのですが、やはりハッカーの主たる動機を「評判ゲームで競うため」と看做すことには抵抗があります。倫理的にどうこう、というよりも「他人と競って勝ちたい」という欲求の威力は、ハッカーを途轍もなく高度な技術の習得や底知れなく深い理解への到達へと導くには弱すぎるのではないかと思えてならないのです。競って勝つだけなら、別にハッキングじゃなくてもよいわけですし。梅干しの種とばし競争でもなんでも好きなだけやればいい。もっとずっと簡単で効果的な方法があるだろうに、そちらを選択しない理由がよくわかりません。
この慣習については「知的好奇心を充足させる際に最も有効な(効率の良い)戦略だから」という方が主たる動機という印象を持ちます。論中でもいくらか言及されていましたが表面上は似たような贈与文化を持つ warez d00dz(違法コピーソフト配布)文化に属する人々の行動との比較で明らかになるんじゃないでしょうか。こっちは純粋な「評判ゲーム」モデルで説明できそうです。
「評判ゲーム」が主たる行動原理だと、相対的に相手に勝てればそれでよいわけですから積極的に贈与(違法コピーソフトの配布)を行なうだけでなく、相手の評判を落とすということも同様に価値ある行動ということになります。他者の能力への誹謗中傷や、隙あらば他者の業績を自分のものとしようとする(バレて評判が落ちる危険もありますけど)等々も効果的な選択肢となります。警察にチクったり罠にはめて相手を社会的に抹殺する、等々直接的かつ積極的な妨害を行なうというのもよい手段となるでしょう。「評判ゲーム」であることで(やりすぎると悪評が立つため)自ずと表立った行動の部分では歯止めはかかるのでしょうが、その分陰湿な脚の引っ張り合いは多発すると考えられます。
一方ハッカー文化では下記のような特徴が見られると言う指摘が論中でなされています。傍線は引用者がつけました。
ハッカーたちは、イデオロギー上のちがいや個人的なちがいでおたがいをフレームしあうのは、ぜんぜんかまわないと思っている。でも、どんなハッカーでも、技術的な仕事について、ほかのハッカーの有能ぶりをおおっぴらに罵倒するのは、前例がない(私的な批判でさえ、あまり見られないし、あってもかなり口ごもった感じで行われる)。バグの追跡と批判は必ずプロジェクトの名前で行われ、個人の名前では行われない。
さらに、開発者は過去のバグのことで自動的に責められたりはしない。バグが修正されたということのほうが、そのバグがかつて存在したということよりも重要だと一般には考えられている。ある評者が述べたように、「Emacsのバグ」を直すことで自分の評判をあげる人はいるけれど「リチャード・ストールマンのバグ」をなおして評判を上げる人はいない---そしてストールマンを批判するのに、修正済みの古いバグを根拠にするのは、とてもよくないこととされるだろう。
これは、アカデミズムの多くの部分ととてもおもしろい対照ぶりを示している。アカデミズムでは、欠陥があると思われる他人の成果をボロクソにするのは、評判を勝ち取る重要な方法の一つだ。ハッカー文化では、こうした行動はいささか強力にタブー視されている---それが強力すぎるために、そういう行動が存在しないということを、ぼく自身が思いつかなかったほどだ。ちょっと変わった視点を持つ評者が、本論文発表から1年以上たって指摘してくれて、やっとはっきり気がついたほどだ!
能力に対する攻撃に関するタブー(アカデミズムとは異なる)は、威張ることについての(アカデミズムと共有された)タブーよりさらに多くを物語ってくれる。ハッカー世界とアカデミズム世界での、コミュニケーションのあり方のちがいや支持構造のちがいについて考えるとき、これが足がかりになるからだ。
これは効率的に評判を得るための戦略というよりは、バグの発見と修正において無駄な諍いが起きたりしないようにする(つまりオープンソースウェアの品質管理上の効率を最大化する)ためのものと考えてよいのではないでしょうか。
また、傍線部分にあるように残念ながら(←笑?)アカデミズム文化はハッカー文化と違法コピー海賊文化の中間くらいの程度で「評判ゲーム」なんだろうと思います(←余談ですが急速に後者に近づいていっているような気も:笑?)。でもこれはコミュニティがどのくらい誰でも参加自由なものか、という程度にも関係しているように思えるので(ハッカー世界で認知され「発表」が許されるにはアカデミズム世界よりも選別が厳しく、warez世界は誰でもオーケーです)簡単には断定できないかもしれません。おかしな人間が予め存在しない世界なら誰も(世迷い言とその発生源を排除するために)攻撃的になる必要はないですからね。
とか、そんな感じで。
ちょっと気になった話があったので久々に書いてみます。
上記サイトの記事「あなたの作ったものはゴミである、あるいはプロとアマの分岐点」対して賛否両論の大きな反響があったようです。「励まされた!」と感謝する人もいれば「フザケンナ!」と怒っている人もいるという具合にコメント欄での反応は両極端にわかれているのですが、その原因はどうも位相の異なる話をゴチャゴチャにして混同させたまま強引に以下の結論に結びつけたことにあるのではないかと思えます。
「頑張ること」それ自体に価値があるのはアマチュアの世界、価値がないのがプロフェッショナルの世界である。
少し私なりに議論を整理してみたいと思います。
まず「モノをちゃんと理解してから評価する/しない」という項目Aと「説明をする/しない」という項目Bを設定してみます。
白川氏が例にあげた建築家の手塚貴晴氏は「モノをちゃんと理解して評価する」&「説明はしない」というタイプです。白川氏本人については書かれたことだけからはハッキリしないのですが「モノをちゃんと理解して評価する」&「説明をする(しないときもある)」という感じでしょうか。
いずれにしても項目Aは○なんですね。そして気にしているのは項目Bに関して相手が受けるショックについてです。プロの仕事では良い結果を出すことがすべてに最優先されるので、モノの出来が悪いにもかかわらず相手の努力を評価して受け入れてあげるということはできないし、その理由を相手が理解できるとも限らないから傷つけてしまうこともある、という話をしています。
こうした話の流れから、プロになりたければ評価される側も「良いモノ」をつくることを最優先に心がけて相手のダメ出しを逆恨みしたりしないことが大事だよ、と結ぶのは何の問題もなさそうです。
ですが該当記事冒頭に引用されている話とは何かズレているように思えます。引用されていたのは以下の記事です。
シアトルの Northwest College of Art & Design で経験した「3ヵ月かけて完成させた学生たちの作品を教師が見もしないでゴミ箱に捨てろと言った授業」について書いてあります。このときの教師 David Johnson は以下のように説明したそうです。
そして、怒っている生徒に向けて先生はこう言いました。「私はこの学校は非常勤で、別にちゃんとデザインと写真のビジネスで生計立ててるから次のクオーターここで教えることができなくなっても一向にかまわない。ただ、みんなプロのデザイナーとしてこの先の人生食っていこうと思っているなら、こんなことは日々起こること。これでショックを受けてやる気をなくしているなら、クリエイティブな職種に向かないから違う道に進んだほうがいい。クライアントの中にはアイデアや作品を見ることもなく破り捨てる人もいる。わたしもそんなこと毎日のように経験してるぞ。」
さて、この話の中に出て来るクライアントは上記の項目AとBでいうとどうなるでしょうか。おそらく「A×B×」ですね。でもこの先生は「A×B○」なので実は同じではありません(説明はしている)。簡単にまとめるとこういうことです。
| 項目A | 項目B | |
| 手塚 | ○ | × |
| 白川 | ○ | △ |
| ジョ | × | ○ |
| クラ | × | × |
要するに4人とも別々のタイプなんです。だから評価される側が受けるショックの原因も別々なはずです。
白川氏の話は項目Aが○じゃないと成立しません。自分が作ったモノの出来が水準に達していないという客観的事実を突きつけられて傷つく、という話です。これを乗り越えるにはクリエイターは涙を拭いて、さらに良いモノを作り上げるべく一層の努力をし精進すればよいだけのことです。
しかし項目Aが×のときはどうでしょうか。これによってクリエイターが傷つくとしたら、その原因は自分の作品にダメ出しされたことによるのではもちろんありません。その人自身が否定されたから、ということでもない。良いモノを作るという行為とその価値そのものが否定された、ということです。モノの良し悪しなどはどうでもいい!と、クリエイターが生きて行く枠組みそのものが「(少なくとも相手にとっては)無価値である」とされたことに対するショックであり失望であり怒りや哀しみなんですね。
でも、それを気にしても仕方がないよ、っていうのが David Johnson 氏の授業から受け取るべきメッセージであり教訓なんだろうと思います。モノを改善しても意味がないならクリエイター自身には打つ手がありません。モノを見もしない相手に納得してもらうには別種の努力が必要になるはずです。対策としては凄腕マネージャー(エージェント?ネゴシエイター?)を雇って裏工作や交渉や接待でなんとかして貰うくらいでしょうか。時間はかかりますが、見もしないで破り捨てることが惜しくて出来ないくらいの実績をあげて名声を得ておく、という方法でもよいかもしれません。
そう考えると、上記引用ブログの書き手が以下のように書いているのはこのエピソードの理解としては間違いなんじゃないかと思います。批難するつもりはありませんけど。
多くのまだ経験の浅いクリエイターの人は、作品や仕事にダメだしされてるのに、人格を否定されたような気分に陥って、自分を否定されたように思って、まだ人に認められるような作品を作る前に辞めてしまったり、上司やクライアントと喧嘩したり、病んでしまったりってあると思います。そういうことを考えると、学生時代にこの体験をしたことで、前職の制作会社に居た時も、フリーランスになってからも、数えきれないほどダメだしされても冷静に対応できたのかなぁって思います。
白川氏はこの部分(と「ゴミ箱」という単語)に反応してああいう記事になったのだと思うのですが、そこに混乱のモトがあったんじゃないでしょうか。
プロかアマかにかかわらず「教育」という観点が入った場合、評価する側は「A○B○」という態度をとるべきなんじゃないか、というように私は思っていました。つまり「モノをちゃんと理解して、当人が改善するときの参考となるように良い部分もダメな部分もきちんと説明してあげる」ということが正しいことなのだと考えていたのです。
そして理論的というか心掛けとしては今もコレが正しいと思っています。
ですが、これは非常に限られた局面でしか成立し得ないものなのかもしれません。まず「モノをちゃんと理解して正しく評価する」というのはとても難しいことです。評価する側とされる側に相当のレベル差がないとできません。
また目的がはっきりしていて評価軸が決まっているのでなければ、何が足りていないのかは確定できません。ある価値基準で「まるでダメ」に見えたものが、考え方によっては「大傑作まであとちょっと」だったりもするのです。
相手が何を意図してそういうモノを作ったのか、どうして失敗しているのか、等々に関しては出来上がったモノを見ただけでは手掛かりを掴めないこともあります。そうするとかなりの手間をかけて相手のことを知る必要が出て来る。これはもうとてつもない労力です。
こういうことを完全に実践できる人間はそう多くない、と推定できます。大抵は「モノをちゃんと理解して正しく評価したつもりでトンチンカンな説明をして呆れられる」というケースがほとんどなんじゃないでしょうか。良し悪しの判断だけは辛うじてなんとか妥当に下せても、それを更に言語化して相手に伝えるまでやるとなると難度が高すぎるように思えます。評価にも説明にも反論の余地があまりにありすぎる、というようなものしか提示できない人間がほとんどじゃないでしょうか。
そのうえ仮に落ち度無く評価と説明が行なえたとしても(相手の落ち度による?)別種の問題が生じるかもしれません。前節で引用したブログの書き手双方が気にしていた点ですが「説明=批評」が『ポライトネス 言語使用における、ある普遍現象』あたりでいうところの FTA(face threatening act)になってしまうことがあります。反論の余地が無ければないで、逆切れ逆恨みが生じる危険性が増してしまうのです。そのあたりにも配慮しなくてはなりません。
ならばいっそのこと「説明はしない」方がマシかもしれません。これなら「説明=批評」にまつわる問題は評価される側に委ねられるので、本物の才能や実力を持っている人なら(必ずしも評価者が想定したのと同じではない)欠点を自分で見つけ出して改善していける可能性があります。この可能性に委ねた方が教育的にはずっと良い結果が得られるのではないでしょうか。
ダメな批評や指導に対しては(つまり批評=モノとなり評価の対象となるので)評価される側が手間をかけてダメな批評のダメな部分を説明し、なぜその批評を受け入れないのかを相手に伝えなければならなくなります。不当な評価をされ不当な批評をきかされてウンザリさせられつつ、なぜ評価者がそのような妥当でない結論に至ったのかを考察し、相手がキレないように心配りをしながら説得して翻意させる...という(そのうえ大抵は意固地になられて不成功に終る)無駄な手間が発生します。
沈黙は金、雉も鳴かずば撃たれまいに、とかとかいいますしね(←!)。
ところで「碌にモノを見もしないで評価する」という態度にも利点はあるのでしょうか。
たぶん「ある」のだと思います。たとえば「原発関連情報の取捨選択に役立つ、糸井メソッド」という例。
ぼくは、じぶんが参考にする意見としては、「よりスキャンダラスでないほう」を選びます。「より脅かしてないほう」を選びます。「より正義を語らないほう」を選びます。「より失礼でないほう」を選びます。そして「よりユーモアのあるほう」を選びます。 itoi_shigesato 2011/04/25 12:44:57
togetter にまとめた人は「100%確実な方法ではありませんが、内容を自力で検証できないとき、手っ取り早い目安になります」と書いています。でもこれって「無知な相手を説得する技法について造詣が深く、しかもそれを情報伝達自体よりも優先して使う余裕がある人」の意見かどうかの目安にしかならないんじゃないでしょうか。
それはさておき、文章の内容そのものを精査するのではなく、別の基準を出来不出来の目安にするということは古くから行なわれているように思います。誤字脱字の数をみるとか引用文の比率や長さで論文の良し悪しを判断する等々もそうですし、手書き文字が上手かどうかで異性との交際や(習字の先生以外の普通の就職なんかでの:笑)採用の成否が決まった時代なんかもあったようです。
モノの出来不出来と相関がある目安をうまく設定できれば、モノ自体の良し悪しがわからない人でも妥当な評価がくだせるようになるかもしれませんし、むしろモノを見ないで目安だけで判断した方が正しい結果になる可能性が高まるかもしれません。でも、問題はそういう都合の良い目安というのが設定し難いってことなんですよね。
論文の良し悪しが誤字脱字の量で決まるという目安が広く知られてしまえば、研究内容はどうでもいいがとにかく他人から高い評価を受けたいという願望の強い人がその部分だけに注力して実際の能力とかけ離れた評価を受けてしまうかもしれません(そしてそういう人達が次世代の評価者となりまた同じ目安で...と、数世代たてばその学問分野が不適格者に占拠されて壊滅してしまうことになります:笑?)。手書き文字の件でも字の練習をするというよりは代筆を頼む方が普通だったようですし、あまり意味はなかったんじゃないかと。
まとめると、以下のような感じでしょうか。
大抵の人間がそもそもまともな評価を下せないという現実があるのだから、「理解しないで評価する」ための良い目安を見つけてそれを使った方が良い結果になることはある。ただし、その目安は相手に気づかれてはならない。
関係あるようなないような話なんですが『皆殺しの數學』にこんな例題が出ています。
20人の相手とお見合いをするとき、可能な限り望ましい相手と結婚する方法を次の条件によって求めよ。
1、相手からは断わられない。
2、結婚を申し込むのは1度だけ。
3、断わった相手には2度と会えない。
解法の説明はややこしいらしくて具体的にはかかれていなかったのですが、「動的計画 dynamic programming」を使って「平均でベスト3の相手と結婚できる方法」が求められるとしています。「最初の5人までは、絶対に結婚しない」から始まる9つの条項があげられていました。そしてここでいう「平均で」の意味は下記の通りです。
ここで示されているのは、あくまでも「平均で」3位までの相手と結婚するための方法である。すなわち、1000人、1万人の人がこの戦略にしたがって結婚を決断をすれば、その人達の選んだ相手の平均順位が3位になるということである。数学的に考えると、これがお見合いを成功させるためのベストの戦略なのだ。(p.46)
統計的手法の話をしているようです。これを実践すれば必ずベスト3以内をゲットできるというわけではありません。要するに「目安」にすぎないんですよ(1000万人の中から平均でベスト4以内をゲットできるガイドラインも算定できるそうなので立派な「目安」ではあるのですけど:汗)。ですので選定法がお見合い会社(?)にバレていたら裏をかかれて意図的にスカを掴まされることになります。
ま、久々に書いて疲れたのでこんな感じで...
Copyright(c)2006-2012 ccoe@mac.com All rights reserved.
{kind=link}
{kind=link}
{kind=link}