統計解析ソフト「R」で多次元尺度構成法を行う際の覚え書き
下三角行列ではなく、最上端をラベル用headerとし、すべての項目が数値で埋まった行列を用意する。
図を出力する必要があるので、ターミナル上ではなくGUIソフトとしてRを使用した。私の計算機の設定ではターミナルの日本語コードはEUCだが、こちらの使用法の場合はUTF-8で読み込みデータを作らないとマルチバイト文字が不正というアラートが出現する。
しかしながら、headerとして読み込むと日本語は「X..」という記述に改変されるのでマルチバイト文字でエラーが出なくても意味はあまりない。日本語表記のheaderはローマ字表記に改めておく必要がある。
データの区切り文字にはスペースを使用する。デフォルトの設定でスペースが選択されている模様である。
読み込みに適したデータは以下のサンプルに準ずるものである。
A B C
0 3 4
3 0 5
4 5 0
上記内容を含むテキストファイルは文字コードをUTF-8とし、改行コードをCRとしたものとなる。次節の説明に必要なのでこのサンプルはrat.data という名前を付けて作業ディレクトリに保存したものとする。
行列変数Xにサンプルデータrat.dataを読み込ませる場合には以下のような手順を用いる。
> X <- read.table("rat.data", header=T)
> X
A B C
1 0 3 4
2 3 0 5
3 4 5 0
読み込み作業自体は最初の1行で終了する。それ以降のものはXにどのような形でデータが収納されたのかの確認結果である。最左端は入力した数値ではなくRによって割り振られたrow番号である。
古典的多次元尺度構成法、計量多次元尺度構成法と呼ばれる手法での分析を行う手順は以下の通り。
> loc <- cmdscale(X)
> plot (loc)
> text (loc, names(X), col="red")
最初の1行で計量MDS自身の計算は終了している。2行目からは作図のためのものである。作図結果は以下の通り。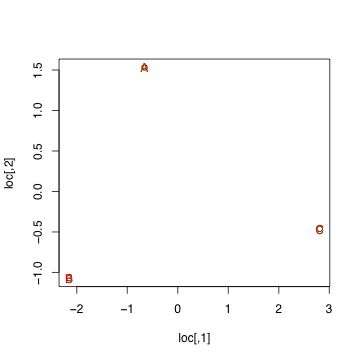
統計解析ソフト「R」でクラスター分析を行う際の覚え書き
上記多次元尺度構成法の場合と文字コード(UTF-8)や区切り文字(スペース)、改行コード(CR)については同じである。
相違点はheaderを読み込む必要がないこと、その代わりに各rowにラベルが必要であることである。最上端ではなく最左端にデータ固有のラベル列が必要となる。
読み込みに適したデータは以下のサンプルに準ずるものである。
A 2 3
B 2 2
C 6 1
D 9 9
E 4 8
MDSの場合と同様にsample.dataなどの名前で作業ディレクトリに保存する。
サンプルデータsample.dataを分析に適した形で読み込ませるには以下のような手順を用いる。
> X <- read.table("sample.data")
> df <- data.frame(X, row.names=T)
> df
V2 V3
A 2 3
B 2 2
C 6 1
D 9 9
E 4 8
headerは存在しないので、header=Tは必要ない。sample.dataの最左端ラベル列は1行目の段階ではデータ項目としてread.tableコマンドで行列Xに読み込まれている。
2行目ではdata.frameコマンドを使って最左端をrow.namesとして認識させて、新たに行列dfに読み込ませている。3行目以降は読み込まれたデータの確認結果である。
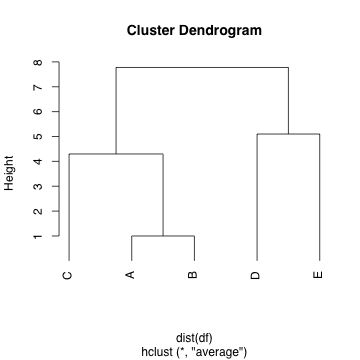
階層クラスター分析と呼ばれる手法を用いてデンドログラムを得る手順は以下の通り。
> hc <- hclust(dist(df), "ave")
> plot (hc)
> plot (hc, hang = -1)
最初の1行で階層クラスター分析自身の計算は終了している。2行目からは作図のためのものである。作図結果は以下の通り。