
妋棪曄悢X乮random variable X乯偵懳偟偰妋棪枾搙娭悢f(x)偑埲壓偺傛偆偵側傞偲偒丄偙傟傪僇僀2忔暘晍乮chi-square distribution乯偲偄偆丅
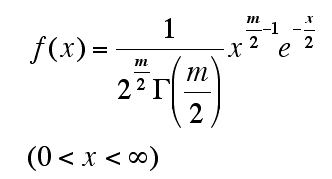
m偼帺桼搙乮degrees of freedom乯傪昞偡丅忋幃偱巊傢傟偰偄傞僈儞儅娭悢乮gamma function乯偺悢幃偼埲壓偺捠傝丅
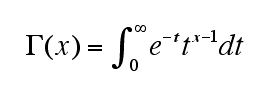
偙偺娭悢偼惍悢埲奜偺奒忔傪寁嶼偡傞偨傔偺傕偺傜偟偔丄t暘晍傗F暘晍偱傕梡偄傜傟傞丅
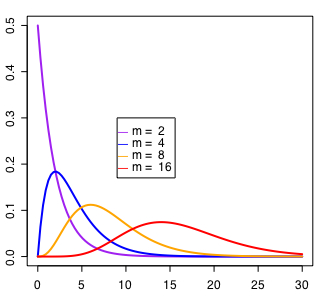
帺桼搙3偺偲偒偺妋棪枾搙暘晍偲椵愊暘晍偼埲壓偺僗僋儕僾僩偱媮傔傜傟傞丅
dchisq(0:10,3)
pchisq(0:10,3)
僌儔僼傪昤偔僗僋儕僾僩偼師偺捠傝丅
ma<-2
mb<-4
mc<-8
md<-16
curve(dchisq(x,ma),0,30, type="l", lwd="2",col="purple",ylim=c(0,0.5))
#curve(pchisq(x,ma),0,30, type="l", lwd="2",col="purple",ylim=c(0,1))
par(new=TRUE)
curve(dchisq(x,mb),0,30, type="l",lwd="2", xlab="", ylab="", main="", axes=F,ylim=c(0,0.5),col="blue")
#curve(pchisq(x,mb),0,30, type="l",lwd="2", xlab="", ylab="", main="", axes=F,ylim=c(0,1),col="blue")
par(new=TRUE)
curve(dchisq(x,mc),0,30, type="l",lwd="2", xlab="", ylab="", main="", axes=F,col="orange",ylim=c(0,0.5))
#curve(pchisq(x,mc),0,30, type="l",lwd="2", xlab="", ylab="", main="", axes=F,col="orange",ylim=c(0,1))
par(new=TRUE)
curve(dchisq(x,md),0,30, type="l",lwd="2", xlab="", ylab="", main="", axes=F,col="red",ylim=c(0,0.5))
#curve(pchisq(x,md),0,30, type="l",lwd="2", xlab="", ylab="", main="", axes=F,col="red",ylim=c(0,1))
legend(9, 0.3, paste("m = ", c(2,4,8,16)), col=c("purple","blue","orange","red"), pch="乕", ncol=1)
#legend(20, 0.3, paste("m = ", c(2,4,8,16)), col=c("purple","blue","orange","red"), pch="乕", ncol=1)
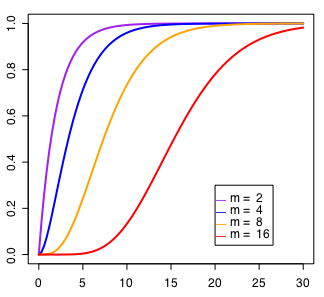
僐儊儞僩傾僂僩偟偨乮pchisq傪巊偆乯曽偱椵愊暘晍恾偑昤偗傞丅
専掕摑寁検偑僇僀2忔暘晍偵廬偆専掕傪僇僀2忔専掕乮chi-square test乯偲偄偆丅乽揔崌搙専掕乮test of goodness of fit乯乿傗乽撈棫惈偺専掕乮test of independence乯乿側偳偵梡偄傞丅
亀儅儞僈摑寁庤朄擖栧亁戞13復偺僨乕僞傪巊偭偰R偱揔崌搙専掕傪峴側偆丅僉僀儘僔儑僂僕儑僂僶僄傪悢偊偰乽栰惗宆儊僗 592旵乿乽栰惗宆僆僗 331旵乿乽敀娽僆僗 281旵乿偩偭偨偲偒丄偙傟偑棟榑忋偺抣乽2:1:1乿偵揔崌偟偰偄傞偺偐偦偆偱側偄偺偐傪専掕偡傞丅
chisq.test(c(592,331,281), p=c( 2, 1, 1)/4)
乽娤應抣偲棟榑抣偺娫偵嵎偑側偄乿偲偄偆婣柍壖愢傪棫偰偰専掕偟偨寢壥偼壓婰偺捠傝丅乽Chi-squared test for given probabilities乿偑幚峴偝傟傞丅
X-squared = 4.485, df = 2, p-value = 0.1062
帺桼搙2偺僇僀2忔暘晍偵偍偄偰専掕摑寁検偼乮p-value > 0.05偵傛傝乯婞媝堟偵擖偭偰偄側偄偺偱壖愢偼婞媝偱偒側偄丅傛偭偰乽嵎偑偁傞偺偐側偄偺偐傢偐傜側偄乿偲偄偆偙偲偵側傞丅p抣乮p-value乯偼乽桳堄妋棪乮observed significance level of the test乯乿偲傕偄偄丄乽桳堄悈弨乮significance level乯乿偲斾妑偟偰彫偝偄抣偱偁傟偽壖愢傪婞媝偡傞丅
亀儅儞僈摑寁庤朄擖栧亁戞12復偺僨乕僞傪巊偭偰R偱撈棫惈偺専掕傪峴側偆丅
| 僔乕僩儀儖僩拝梡 | 僔乕僩儀儖僩枹拝梡 | |
| 晧彎偟偨恖 | 10533恖 | 8896恖 |
| 巰朣偟偨恖 | 31恖 | 167恖 |
chisq.test(matrix(c(10533, 8896, 31, 167), ncol=2, byrow=T))
僔乕僩儀儖僩拝梡偺桳柍偲旐奞偺戝偒偝偵娭學偑側偄丄偲偡傞婣柍壖愢傪棫偰偰乽Pearson's Chi-squared test with Yates' continuity correction乿傪幚峴偡傞丅
X-squared = 115.689, df = 1, p-value < 2.2e-16
帺桼搙1偺僇僀2忔暘晍偵偍偄偰専掕摑寁検偼乮p-value < 0.05偵傛傝乯婞媝堟偵擖偭偰偄傞偨傔丄壖愢偼婞媝偱偒傞丅偮傑傝僔乕僩儀儖僩偺拝梡偲岎捠帠屘旐奞偵乽撈棫惈偼側偄乿亖娭楢偑偁傞丄偲偄偆偙偲偑偄偊傞丅
乽摨摍惈偺専徹乮test for equality乯乿偼専掕摑寁検偑婞媝堟偵擖傜側偐偭偨偙偲傪壖愢惉棫偲擣傔傛偆偲偄偆峫偊偵婎偯偄偰偄傞丅亀儅儞僈摑寁庤朄擖栧亁戞14復偺僨乕僞傪巊偭偰R偱専徹偡傞丅
| 僠僪儕 | 僔僊 | 僒僊 | |
| 扟捗姳妰 | 210塇 | 2500塇 | 110塇 |
| 鎩憗姳妰 | 350塇 | 3800塇 | 230塇 |
chisq.test(matrix(c(210, 2500, 110, 350,3800,230), ncol=3, byrow=T))
扟捗姳妰偲鎩憗姳妰偱捁偺暘晍斾偵嵎偑側偄丄偲偄偆壖愢傪棫偰傞丅乽Pearson's Chi-squared test乿偑幚峴偝傟傞丅
X-squared = 7.9816, df = 2, p-value = 0.01848
帺桼搙2偺僇僀2忔暘晍偵偍偄偰専掕摑寁検偼乮p-value < 0.05偵傛傝乯婞媝堟偵擖偭偰偄傞偨傔丄壖愢偼婞媝偱偒傞丅偮傑傝傆偨偮偺姳妰偱捁偺暘晍斾偵嵎偑偁傞丄偲偄偆偙偲偑偄偊傞丅
pwr.chisq.test(w=0.01848, N=6,df=2,sig.level=0.05)
偙偺椺偱偼壖愢偑婞媝偝傟偰偟傑偭偰偄傞偺偱埖傢側偐偭偨偑丄捠忢乽摨摍惈偺専徹乿偱偼乽専弌椡乮power of test乯乿偺抣傪傒偰乽摨摍偐偳偆偐乿傪敾抐偡傞丅忋偺僗僋儕僾僩偵傛偭偰 power = 0.0501535 偑嶼弌偱偒傞丅power > 0.8 偺偲偒乽壖愢偑惉傝棫偮乿偲敾抐偡傞丅
乽僼傿僢僔儍乕偺惓妋妋棪専掕乮Fisher's exact test乯乿偱偼挻婔壗暘晍傪棙梡偟偰 p-value 傪媮傔傞丅昗杮悢偑嬌嬐偐偱偁傞側偳丄僇僀2忔専掕偱埖偄偵偔偄僨乕僞偵懳偟偰巊梡偡傞丅梡搑偼僇僀2忔専掕偲摨條乽撈棫惈偺専掕乿傗乽曣廤抍偺曣斾棪斾妑乿側偳偱偁傞丅
梌偊傜傟偨僨乕僞偵懳偟偰挻婔壗暘晍傪梡偄偰妋棪傪寁嶼偡傞丅梌偊傜傟偨峴楍偵懳偟偰暘巕偼乽奺峴乮row乯偺憤榓偺奒忔偲奺楍乮column乯偺憤榓偺奒忔偺愊乿偱丄暘曣偼乽抣偺憤榓偺奒忔偲奺抣偺奒忔偺愊乿偱偁傞丅
傑偢娤嶡偝傟偨僨乕僞偵懳偟偰偙傟傪峴側偆偙偲偱惗婲妋棪傪摼傞丅
師偵奺峴偺憤榓偲奺楍偺憤榓傪屌掕偟偨傑傑偱丄奺抣傪曄壔偝偣傞偙偲偱摼傜傟傞忬懺偡傋偰偵偮偄偰惗婲妋棪傪寁嶼偡傞丅2亊2峴楍乮1峴栚a,b 2峴栚c,d乯偺応崌丄撈棫惈傪専掕偡傞梫場摨巑偺娭楢偺嫮偝傪傒傞偨傔偵 ad-bc 傪寁嶼偟丄娤應偝傟偨僨乕僞傛傝傕偦偺抣偑戝偒偄傕偺偺惗婲妋棪偺憤榓偲娤應偝傟偨僨乕僞偺惗婲妋棪偺榓傪媮傔傞乮曅懁専掕偺応崌乯丅偙偆偟偰媮傔偨抣偑 p-value < 0.05 偺偲偒婣柍壖愢偼婞媝偝傟傞丅
師偺2亊2僋儘僗廤寁昞傪娤應偝傟偨僨乕僞偲偟偰寁嶼偡傞丅
| B1 | B2 | |
| A1 | 1 | 2 |
| A2 | 3 | 4 |
X <- matrix(c(1, 2, 3, 4), ncol=2, byrow=T)
#chisq.test(X)
fisher.test(X, alternative="g")
僇僀2忔専掕偺寢壥偵偼乽Warning message:僇僀帺忔嬤帡偼晄惓妋偐傕偟傟傑偣傫乿偲偄偆傾儔乕僩偑弌偨丅偦傟偱傕堦墳乽X-squared = 0.1786, df = 1, p-value = 0.6726乿偑嶼弌偝傟傞丅乽Fisher's Exact Test for Count Data乿偱偼 p-value = 0.8333 偲側傞丅僼傿僢僔儍乕偺惓妋妋棪専掕傪庤嶌嬈偱寁嶼偟偰傒傞丅忋婰偺僋儘僗廤寁昞偺応崌丄師偺4偮偺応崌偑懚嵼偡傞丅
a=0,b=3,c=4,d=3乮ad-bc=-12, P0=0.1666667乯
a=1,b=2,c=3,d=4乮ad-bc=-2, P1=0.5乯
a=2,b=1,c=2,d=5乮ad-bc=8, P2=0.3乯
a=3,b=0,c=1,d=6乮ad-bc=17, P3=0.03333333乯
娤應偝傟偨僨乕僞P1傪娷傫偱偦傟傛傝 ad-bc 偑戝偒偄偺偼P2,P3側偺偱偦偺憤榓偱偁傞 p-value 偼 0.5+0.3+0.33333...=0.833333...偲側傝丄fisher.test 偺寁嶼寢壥偲堦抳偡傞丅
>> EMAN偺暔棟妛乽僈儞儅娭悢乿
>> R-Tips 66愡乽僇僥僑儕僇儖僨乕僞偺専掕乿
>> 墱懞惏旻愭惗偺僒僀僩乽僇僀2忔専掕乿
>> 惵栘斏怢愭惗偺僒僀僩乽僼傿僢僔儍乕偺惓妋妋棪専掕乮捈愙妋棪乯乿