
基本的なインストール方法などについては上記リンク先か下記キャプチャ画像を参照のこと。
>> 
MacOSXの場合は configure の一部を書き換えないと(少なくとも0.98までは)うまくいかない場合がある。解決方法は上記サイトを参照のこと。内容のキャプチャ画像は下記の通り。
>> 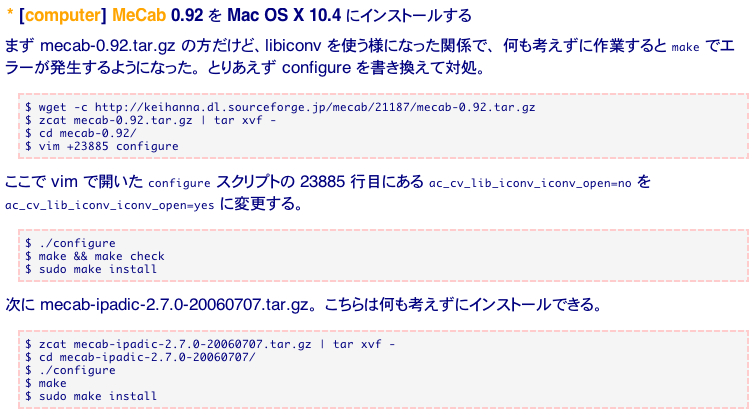
MacOSXのバージョンによって書き換えなければならない configure 上の行番号は異なるので確認が必要である。
Perlスクリプトの中で MeCab を使うには上記サイトで説明されている措置が必要である。該当部分のキャプチャ画像は下記の通り。
>> 
use MeCab;
スクリプトの出だしに MeCabモジュールの使用を宣言しておく。
####### 日本語でMeCabを使う場合
$mecab = MeCab::Tagger->new();
$node = $mecab->parseToNode($lines);
for( ; $node; $node = $node->{next} ) {
next unless defined $node->{surface};
$surface = $node->{surface};
$lemma = (split( /,/, $node->{feature} ))[6];
if($lemma eq "\*"){
push(@words, $surface);
}else{
push(@words, $lemma);
}
}
$lines には分析対象文字列が入っている。MeCab はこの文字列を形態素解析して「表層形」を分割する。上の例では各形態素に付帯する分析情報のうち「原形(レンマ)」情報だけを取り出して一旦 $lemma に格納してから、それを要素として配列 @words に次々と順に押し込んでいる。結果として表層形を原形に変換する作業をしたことになる。
しかしそのように処理しただけでは、辞書に定義されていない語には原形情報も存在しないため、アスタリスクに置き換えられてしまう問題も発生する。こうした未知語の問題をどのように扱うかについては慎重に検討する必要があるが、上の例では表層形を利用することで簡便に処理している。
ちなみに分析情報は以下のように分類されているようだ。上記スクリプトでは feature のうち6番目の情報である「原形」を利用している。
surface...表層形
feature...品詞[0],品詞細分類1[1],品詞細分類2[2],品詞細分類3[3],活用形[4],活用型[5],原形[6],読み[7],発音[8]
Perl における MeCab の利用については先述した Kawanet Tech Blog に説明がある。該当部分のキャプチャ画像は下記の通り。
>> 
追記:現在一般的には MeCab.pm ではなく Text::MeCab が使われている。後者を使う場合のスクリプトについてはTermExtract::MeCabを話題にした部分で言及した。
Copyright(c)2005-2012 ccoe@mac.com Allrights reserved.